 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Object Deformation and Contact Patch Estimation from Visuo-Tactile Feedback
May 23, 2023



Reasoning over the interplay between object deformation and force transmission through contact is central to the manipulation of compliant objects. In this paper, we propose Neural Deforming Contact Field (NDCF), a representation that jointly models object deformations and contact patches from visuo-tactile feedback using implicit representations. Representing the object geometry and contact with the environment implicitly allows a single model to predict contact patches of varying complexity. Additionally, learning geometry and contact simultaneously allows us to enforce physical priors, such as ensuring contacts lie on the surface of the object. We propose a neural network architecture to learn a NDCF, and train it using simulated data. We then demonstrate that the learned NDCF transfers directly to the real-world without the need for fine-tuning. We benchmark our proposed approach against a baseline representing geometry and contact patches with point clouds. We find that NDCF performs better on simulated data and in transfer to the real-world.
CHSEL: Producing Diverse Plausible Pose Estimates from Contact and Free Space Data
May 14, 2023This paper proposes a novel method for estimating the set of plausible poses of a rigid object from a set of points with volumetric information, such as whether each point is in free space or on the surface of the object. In particular, we study how pose can be estimated from force and tactile data arising from contact. Using data derived from contact is challenging because it is inherently less information-dense than visual data, and thus the pose estimation problem is severely under-constrained when there are few contacts. Rather than attempting to estimate the true pose of the object, which is not tractable without a large number of contacts, we seek to estimate a plausible set of poses which obey the constraints imposed by the sensor data. Existing methods struggle to estimate this set because they are either designed for single pose estimates or require informative priors to be effective. Our approach to this problem, Constrained pose Hypothesis Set Elimination (CHSEL), has three key attributes: 1) It considers volumetric information, which allows us to account for known free space; 2) It uses a novel differentiable volumetric cost function to take advantage of powerful gradient-based optimization tools; and 3) It uses methods from the Quality Diversity (QD) optimization literature to produce a diverse set of high-quality poses. To our knowledge, QD methods have not been used previously for pose registration. We also show how to update our plausible pose estimates online as more data is gathered by the robot. Our experiments suggest that CHSEL shows large performance improvements over several baseline methods for both simulated and real-world data.
Data-Efficient Learning of Natural Language to Linear Temporal Logic Translators for Robot Task Specification
Mar 21, 2023



To make robots accessible to a broad audience, it is critical to endow them with the ability to take universal modes of communication, like commands given in natural language, and extract a concrete desired task specification, defined using a formal language like linear temporal logic (LTL). In this paper, we present a learning-based approach for translating from natural language commands to LTL specifications with very limited human-labeled training data. This is in stark contrast to existing natural-language to LTL translators, which require large human-labeled datasets, often in the form of labeled pairs of LTL formulas and natural language commands, to train the translator. To reduce reliance on human data, our approach generates a large synthetic training dataset through algorithmic generation of LTL formulas, conversion to structured English, and then exploiting the paraphrasing capabilities of modern large language models (LLMs) to synthesize a diverse corpus of natural language commands corresponding to the LTL formulas. We use this generated data to finetune an LLM and apply a constrained decoding procedure at inference time to ensure the returned LTL formula is syntactically correct. We evaluate our approach on three existing LTL/natural language datasets and show that we can translate natural language commands at 75\% accuracy with far less human data ($\le$12 annotations). Moreover, when training on large human-annotated datasets, our method achieves higher test accuracy (95\% on average) than prior work. Finally, we show the translated formulas can be used to plan long-horizon, multi-stage tasks on a 12D quadrotor.
Learning the Dynamics of Compliant Tool-Environment Interaction for Visuo-Tactile Contact Servoing
Oct 07, 2022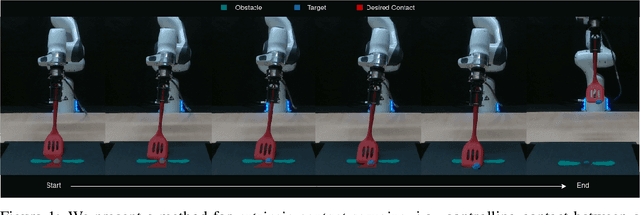
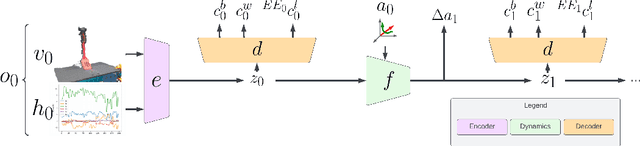
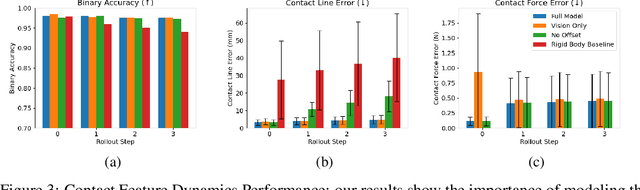
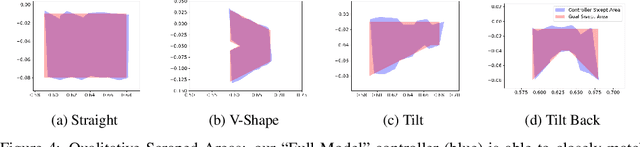
Many manipulation tasks require the robot to control the contact between a grasped compliant tool and the environment, e.g. scraping a frying pan with a spatula. However, modeling tool-environment interaction is difficult, especially when the tool is compliant, and the robot cannot be expected to have the full geometry and physical properties (e.g., mass, stiffness, and friction) of all the tools it must use. We propose a framework that learns to predict the effects of a robot's actions on the contact between the tool and the environment given visuo-tactile perception. Key to our framework is a novel contact feature representation that consists of a binary contact value, the line of contact, and an end-effector wrench. We propose a method to learn the dynamics of these contact features from real world data that does not require predicting the geometry of the compliant tool. We then propose a controller that uses this dynamics model for visuo-tactile contact servoing and show that it is effective at performing scraping tasks with a spatula, even in scenarios where precise contact needs to be made to avoid obstacles.
Focused Adaptation of Dynamics Models for Deformable Object Manipulation
Sep 28, 2022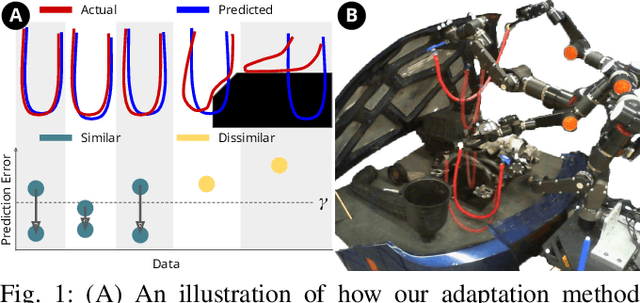
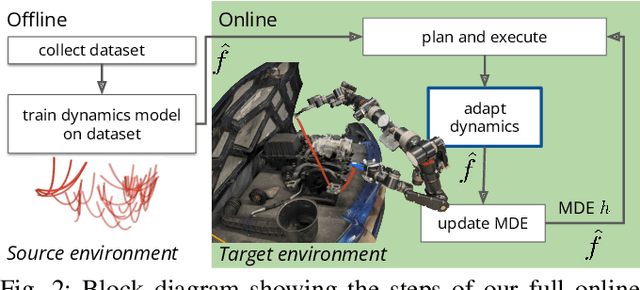
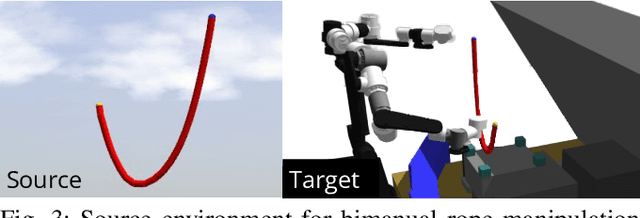
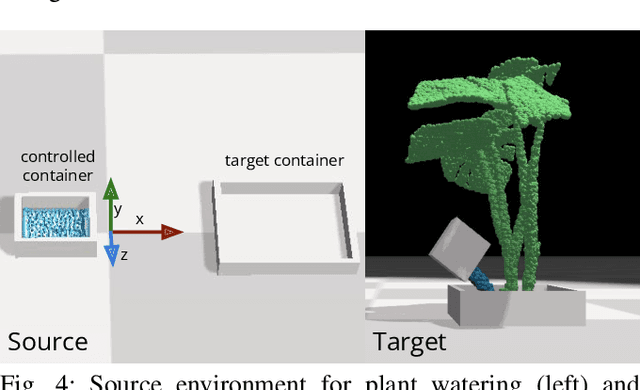
In order to efficiently learn a dynamics model for a task in a new environment, one can adapt a model learned in a similar source environment. However, existing adaptation methods can fail when the target dataset contains transitions where the dynamics are very different from the source environment. For example, the source environment dynamics could be of a rope manipulated in free-space, whereas the target dynamics could involve collisions and deformation on obstacles. Our key insight is to improve data efficiency by focusing model adaptation on only the regions where the source and target dynamics are similar. In the rope example, adapting the free-space dynamics requires significantly fewer data than adapting the free-space dynamics while also learning collision dynamics. We propose a new method for adaptation that is effective in adapting to regions of similar dynamics. Additionally, we combine this adaptation method with prior work on planning with unreliable dynamics to make a method for data-efficient online adaptation, called FOCUS. We first demonstrate that the proposed adaptation method achieves statistically significantly lower prediction error in regions of similar dynamics on simulated rope manipulation and plant watering tasks. We then show on a bimanual rope manipulation task that FOCUS achieves data-efficient online learning, in simulation and in the real world.
Manipulation via Membranes: High-Resolution and Highly Deformable Tactile Sensing and Control
Sep 27, 2022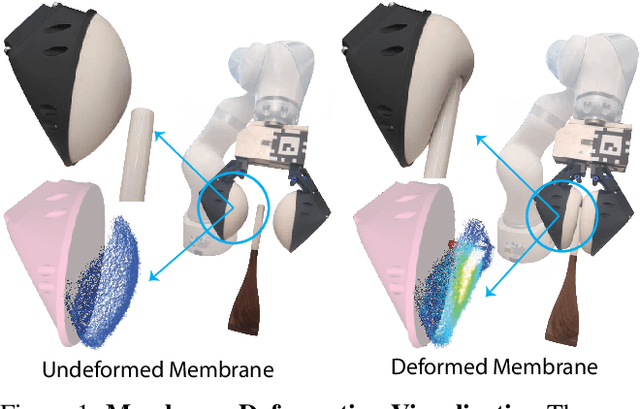
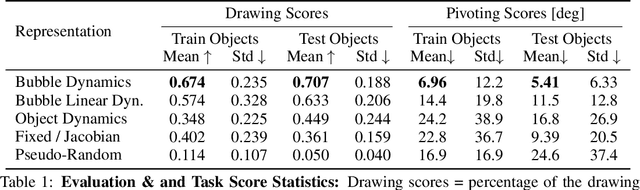
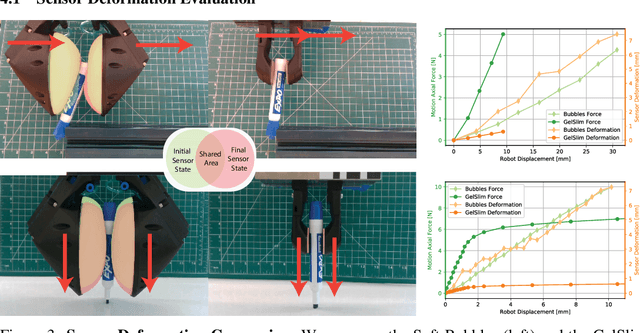
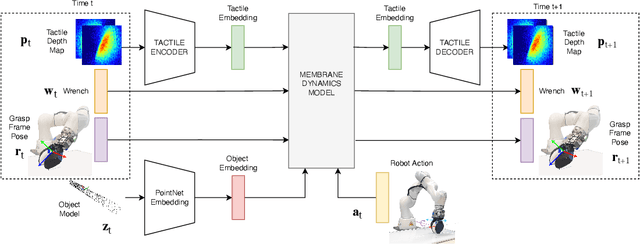
Collocated tactile sensing is a fundamental enabling technology for dexterous manipulation. However, deformable sensors introduce complex dynamics between the robot, grasped object, and environment that must be considered for fine manipulation. Here, we propose a method to learn soft tactile sensor membrane dynamics that accounts for sensor deformations caused by the physical interaction between the grasped object and environment. Our method combines the perceived 3D geometry of the membrane with proprioceptive reaction wrenches to predict future deformations conditioned on robot action. Grasped object poses are recovered from membrane geometry and reaction wrenches, decoupling interaction dynamics from the tactile observation model. We benchmark our approach on two real-world contact-rich tasks: drawing with a grasped marker and in-hand pivoting. Our results suggest that explicitly modeling membrane dynamics achieves better task performance and generalization to unseen objects than baselines.
Safe Output Feedback Motion Planning from Images via Learned Perception Modules and Contraction Theory
Jun 14, 2022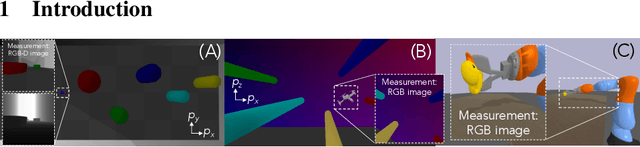
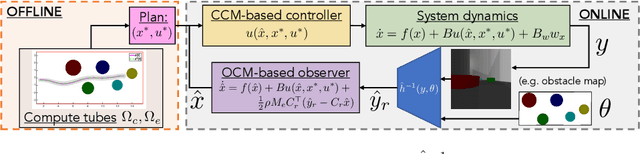
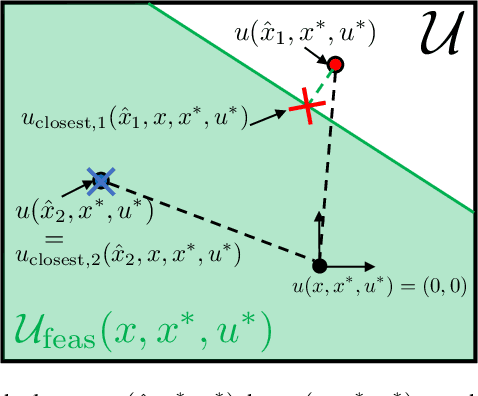
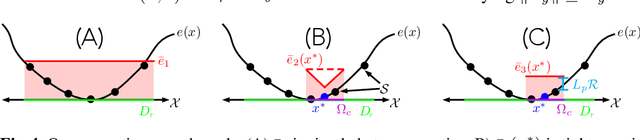
We present a motion planning algorithm for a class of uncertain control-affine nonlinear systems which guarantees runtime safety and goal reachability when using high-dimensional sensor measurements (e.g., RGB-D images) and a learned perception module in the feedback control loop. First, given a dataset of states and observations, we train a perception system that seeks to invert a subset of the state from an observation, and estimate an upper bound on the perception error which is valid with high probability in a trusted domain near the data. Next, we use contraction theory to design a stabilizing state feedback controller and a convergent dynamic state observer which uses the learned perception system to update its state estimate. We derive a bound on the trajectory tracking error when this controller is subjected to errors in the dynamics and incorrect state estimates. Finally, we integrate this bound into a sampling-based motion planner, guiding it to return trajectories that can be safely tracked at runtime using sensor data. We demonstrate our approach in simulation on a 4D car, a 6D planar quadrotor, and a 17D manipulation task with RGB(-D) sensor measurements, demonstrating that our method safely and reliably steers the system to the goal, while baselines that fail to consider the trusted domain or state estimation errors can be unsafe.
Data Augmentation for Manipulation
May 17, 2022

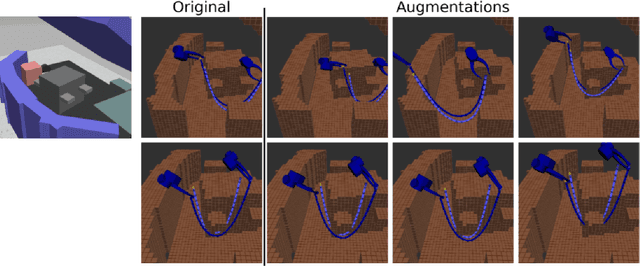
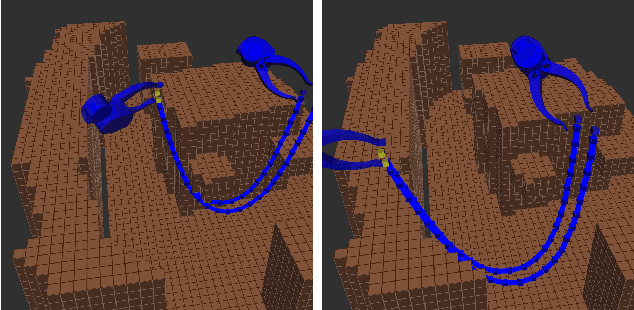
The success of deep learning depends heavily on the availability of large datasets, but in robotic manipulation there are many learning problems for which such datasets do not exist. Collecting these datasets is time-consuming and expensive, and therefore learning from small datasets is an important open problem. Within computer vision, a common approach to a lack of data is data augmentation. Data augmentation is the process of creating additional training examples by modifying existing ones. However, because the types of tasks and data differ, the methods used in computer vision cannot be easily adapted to manipulation. Therefore, we propose a data augmentation method for robotic manipulation. We argue that augmentations should be valid, relevant, and diverse. We use these principles to formalize augmentation as an optimization problem, with the objective function derived from physics and knowledge of the manipulation domain. This method applies rigid body transformations to trajectories of geometric state and action data. We test our method in two scenarios: 1) learning the dynamics of planar pushing of rigid cylinders, and 2) learning a constraint checker for rope manipulation. These two scenarios have different data and label types, yet in both scenarios, training on our augmented data significantly improves performance on downstream tasks. We also show how our augmentation method can be used on real-robot data to enable more data-efficient online learning.
Variational Inference MPC using Normalizing Flows and Out-of-Distribution Projection
May 10, 2022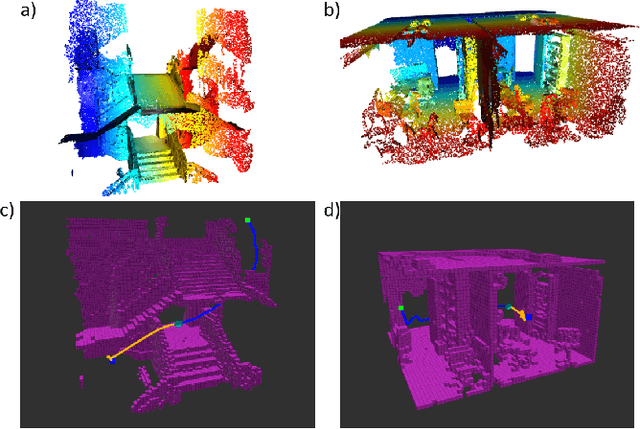
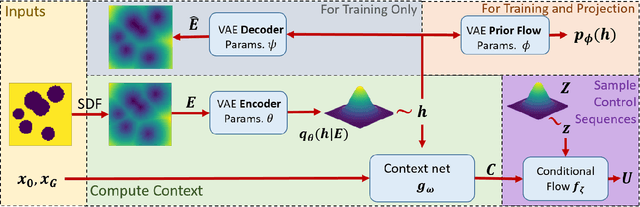
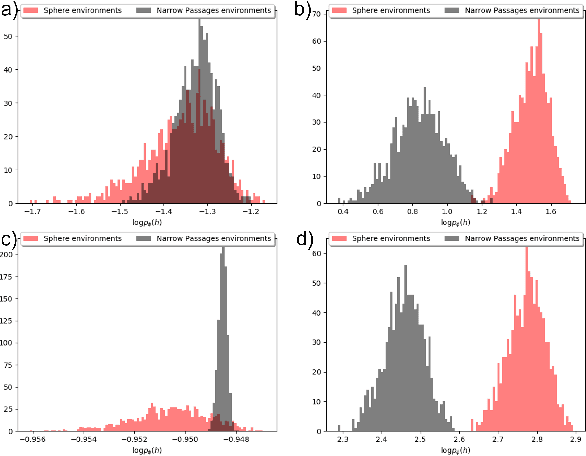
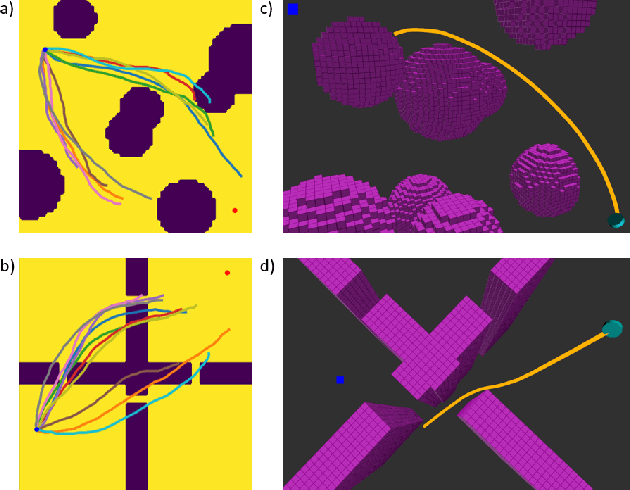
We propose a Model Predictive Control (MPC) method for collision-free navigation that uses amortized variational inference to approximate the distribution of optimal control sequences by training a normalizing flow conditioned on the start, goal and environment. This representation allows us to learn a distribution that accounts for both the dynamics of the robot and complex obstacle geometries. We can then sample from this distribution to produce control sequences which are likely to be both goal-directed and collision-free as part of our proposed FlowMPPI sampling-based MPC method. However, when deploying this method, the robot may encounter an out-of-distribution (OOD) environment, i.e. one which is radically different from those used in training. In such cases, the learned flow cannot be trusted to produce low-cost control sequences. To generalize our method to OOD environments we also present an approach that performs projection on the representation of the environment as part of the MPC process. This projection changes the environment representation to be more in-distribution while also optimizing trajectory quality in the true environment. Our simulation results on a 2D double-integrator and a 3D 12DoF underactuated quadrotor suggest that FlowMPPI with projection outperforms state-of-the-art MPC baselines on both in-distribution and OOD environments, including OOD environments generated from real-world data.
Soft Tracking Using Contacts for Cluttered Objects to Perform Blind Object Retrieval
Jan 25, 2022
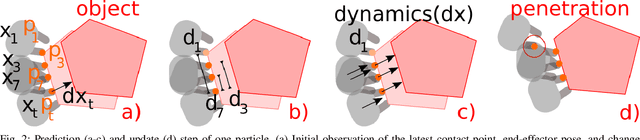

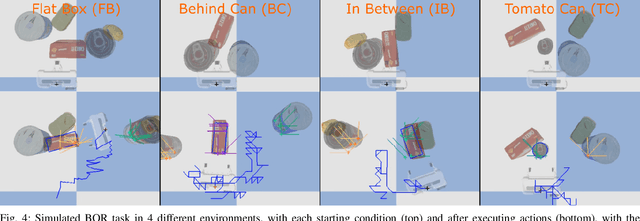
Retrieving an object from cluttered spaces suchas cupboards, refrigerators, or bins requires tracking objects with limited or no visual sensing. In these scenarios, contact feedback is necessary to estimate the pose of the objects, yet the objects are movable while their shapes and number may be unknown, making the association of contacts with objects extremely difficult. While previous work has focused on multi-target tracking, the assumptions therein prohibit using prior methods given only the contact-sensing modality. Instead, this paper proposes the method Soft Tracking Using Contacts for Cluttered Objects (STUCCO) that tracks the belief over contact point locations and implicit object associations using a particle filter. This method allows ambiguous object associations of past contacts to be revised as new information becomes available. We apply STUCCO to the Blind Object Retrieval problem, where a target object of known shape but unknown pose must be retrieved from clutter. Our results suggest that our method outperforms baselines in four simulation environments, and on a real robot, where contact sensing is noisy. In simulation, we achieve grasp success of at least 65% on all environments while no baselines achieve over 5%.