 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Connection between Out-of-Distribution Generalization and Privacy of ML Models
Oct 07, 2021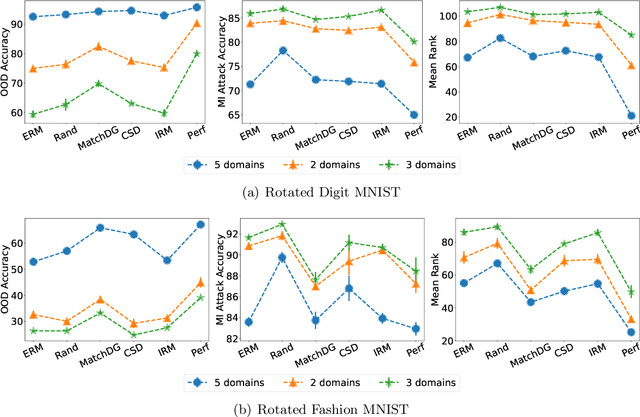

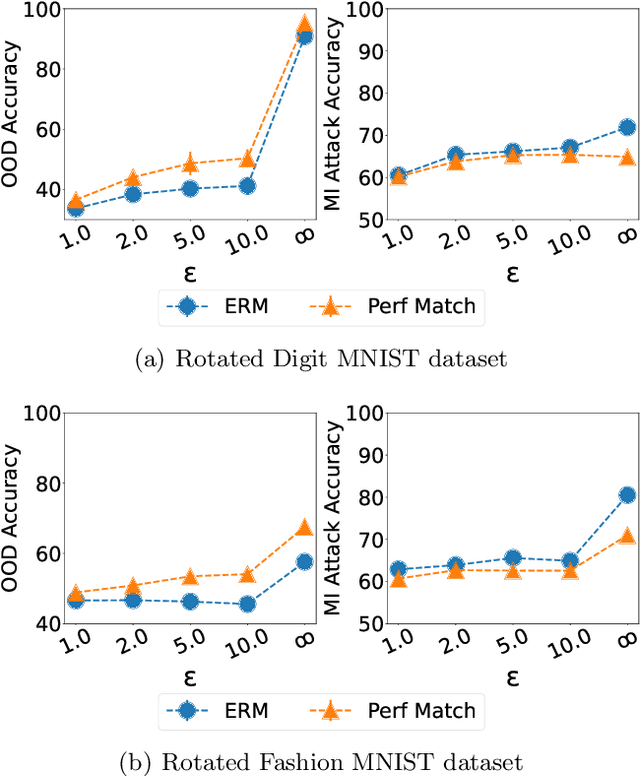
With the goal of generalizing to out-of-distribution (OOD) data, recent domain generalization methods aim to learn "stable" feature representations whose effect on the output remains invariant across domains. Given the theoretical connection between generalization and privacy, we ask whether better OOD generalization leads to better privacy for machine learning models, where privacy is measured through robustness to membership inference (MI) attacks. In general, we find that the relationship does not hold. Through extensive evaluation on a synthetic dataset and image datasets like MNIST, Fashion-MNIST, and Chest X-rays, we show that a lower OOD generalization gap does not imply better robustness to MI attacks. Instead, privacy benefits are based on the extent to which a model captures the stable features. A model that captures stable features is more robust to MI attacks than models that exhibit better OOD generalization but do not learn stable features. Further, for the same provable differential privacy guarantees, a model that learns stable features provides higher utility as compared to others. Our results offer the first extensive empirical study connecting stable features and privacy, and also have a takeaway for the domain generalization community; MI attack can be used as a complementary metric to measure model quality.
Split-Treatment Analysis to Rank Heterogeneous Causal Effects for Prospective Interventions
Nov 11, 2020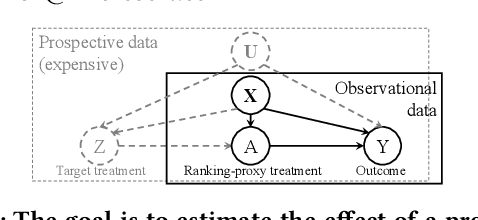
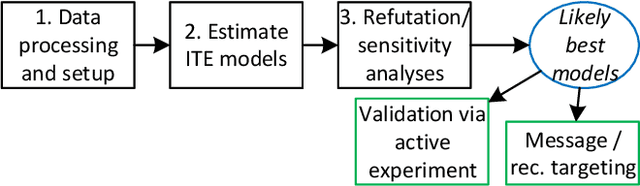
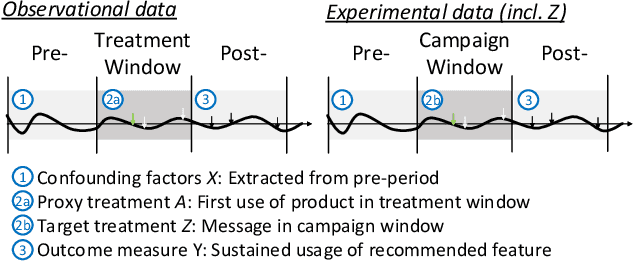
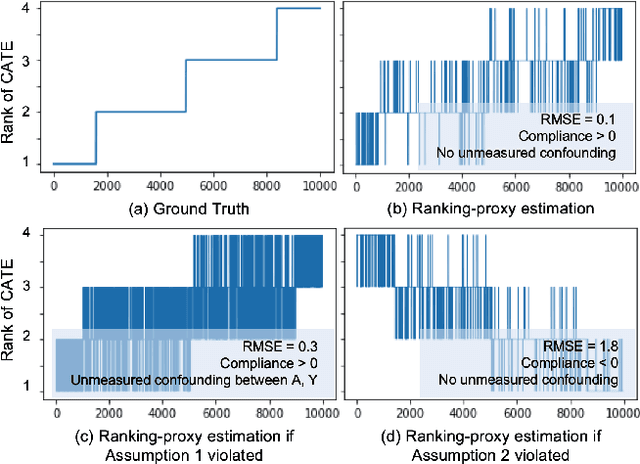
For many kinds of interventions, such as a new advertisement, marketing intervention, or feature recommendation, it is important to target a specific subset of people for maximizing its benefits at minimum cost or potential harm. However, a key challenge is that no data is available about the effect of such a prospective intervention since it has not been deployed yet. In this work, we propose a split-treatment analysis that ranks the individuals most likely to be positively affected by a prospective intervention using past observational data. Unlike standard causal inference methods, the split-treatment method does not need any observations of the target treatments themselves. Instead it relies on observations of a proxy treatment that is caused by the target treatment. Under reasonable assumptions, we show that the ranking of heterogeneous causal effect based on the proxy treatment is the same as the ranking based on the target treatment's effect. In the absence of any interventional data for cross-validation, Split-Treatment uses sensitivity analyses for unobserved confounding to select model parameters. We apply Split-Treatment to both a simulated data and a large-scale, real-world targeting task and validate our discovered rankings via a randomized experiment for the latter.
Towards Unifying Feature Attribution and Counterfactual Explanations: Different Means to the Same End
Nov 10, 2020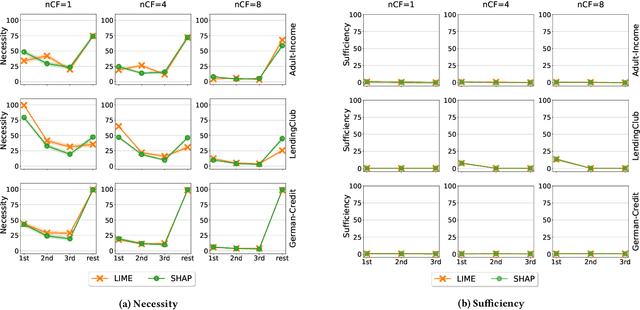

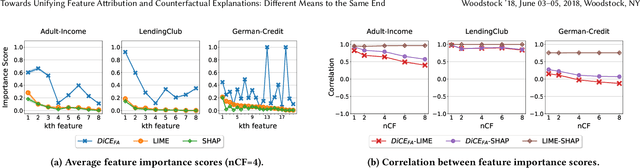
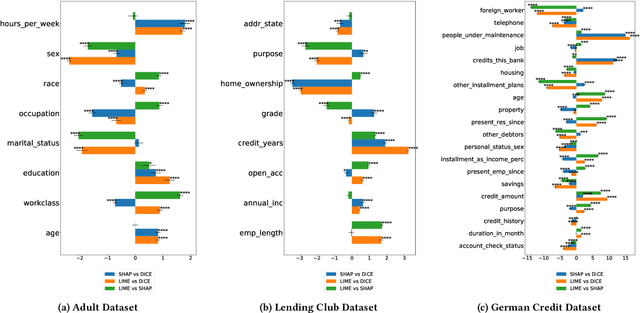
To explain a machine learning model, there are two main approaches: feature attributions that assign an importance score to each input feature, and counterfactual explanations that provide input examples with minimal changes to alter the model's prediction. We provide two key results towards unifying these approaches in terms of their interpretation and use. First, we present a method to generate feature attribution explanations from a set of counterfactual examples. These feature attributions convey how important a feature is to changing the classification outcome of a model, especially on whether a subset of features is necessary and/or sufficient for that change, which feature attribution methods are unable to provide. Second, we show how counterfactual examples can be used to evaluate the goodness of an attribution-based explanation in terms of its necessity and sufficiency. As a result, we highlight the complementarity of these two approaches and provide an interpretation based on a causal inference framework. Our evaluation on three benchmark datasets -- Adult Income, LendingClub, and GermanCredit -- confirm the complementarity. Feature attribution methods like LIME and SHAP and counterfactual explanation methods like DiCE often do not agree on feature importance rankings. In addition, by restricting the features that can be modified for generating counterfactual examples, we find that the top-k features from LIME or SHAP are neither necessary nor sufficient explanations of a model's prediction. Finally, we present a case study of different explanation methods on a real-world hospital triage problem.
Domain Generalization using Causal Matching
Jun 12, 2020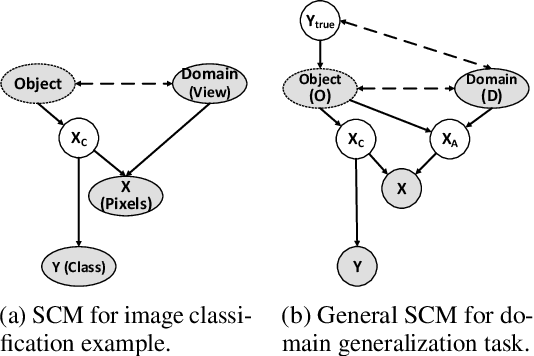
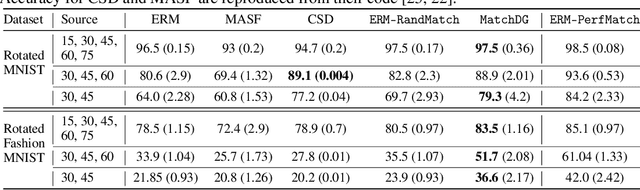
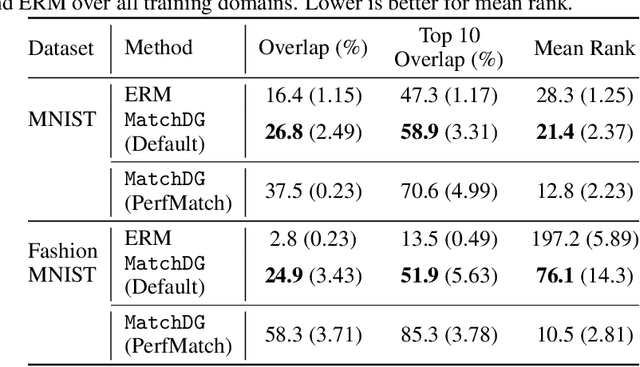
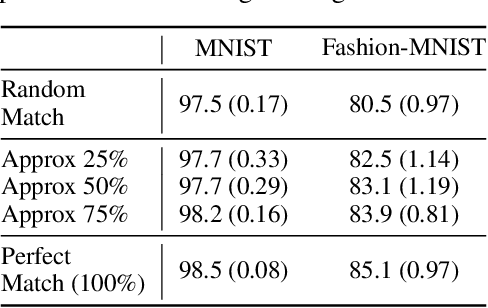
Learning invariant representations has been proposed as a key technique for addressing the domain generalization problem. However, the question of identifying the right conditions for invariance remains unanswered. In this work, we propose a causal interpretation of domain generalization that defines domains as interventions under a data-generating process. Based on a general causal model for data from multiple domains, we show that prior methods for learning an invariant representation optimize for an incorrect objective. We highlight an alternative condition: inputs across domains should have the same representation if they are derived from the same base object. In practice, knowledge about generation of data or objects is not available. Hence we propose an iterative algorithm called MatchDG that approximates base object similarity by using a contrastive loss formulation adapted for multiple domains. We then match inputs that are similar under the resultant representation to build an invariant classifier. We evaluate MatchDG on rotated MNIST, Fashion-MNIST, and PACS datasets and find that it outperforms prior work on out-of-domain accuracy and learns matches that have over 25\% overlap with ground-truth object matches in MNIST and Fashion-MNIST. Code repository can be accessed here: \textit{https://github.com/microsoft/robustdg}
Preserving Causal Constraints in Counterfactual Explanations for Machine Learning Classifiers
Dec 06, 2019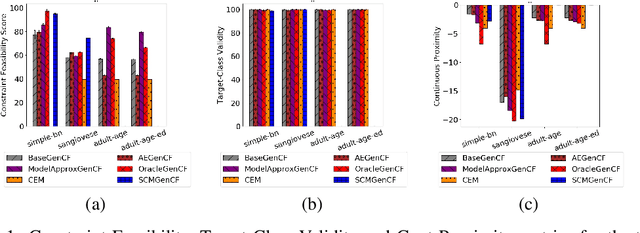
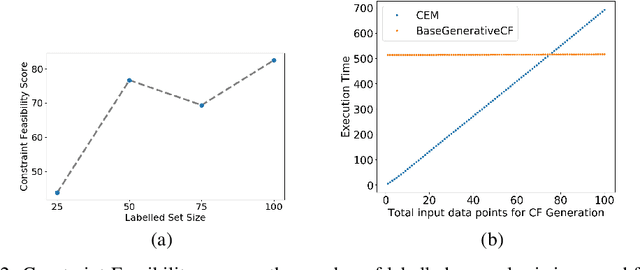
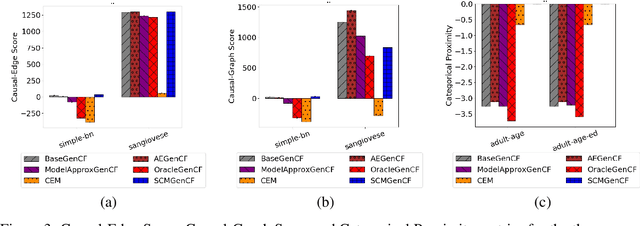
Explaining the output of a complex machine learning (ML) model often requires approximation using a simpler model. To construct interpretable explanations that are also consistent with the original ML model, counterfactual examples --- showing how the model's output changes with small perturbations to the input --- have been proposed. This paper extends the work in counterfactual explanations by addressing the challenge of feasibility of such examples. For explanations of ML models in critical domains such as healthcare, finance, etc, counterfactual examples are useful for an end-user only to the extent that perturbation of feature inputs is feasible in the real world. We formulate the problem of feasibility as preserving causal relationships among input features and present a method that uses (partial) structural causal models to generate actionable counterfactuals. When feasibility constraints may not be easily expressed, we propose an alternative method that optimizes for feasibility as people interact with its output and provide oracle-like feedback. Our experiments on a Bayesian network and the widely used "Adult" dataset show that our proposed methods can generate counterfactual explanations that satisfy feasibility constraints.
A Generative Framework for Zero-Shot Learning with Adversarial Domain Adaptation
Jun 07, 2019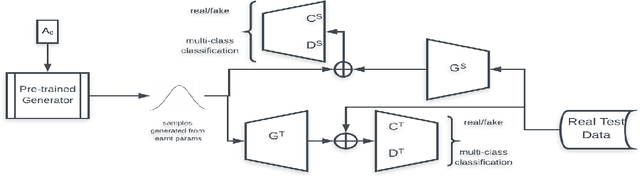
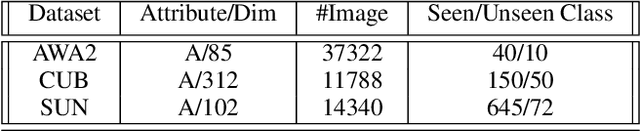
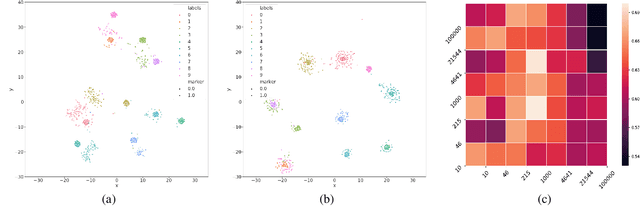
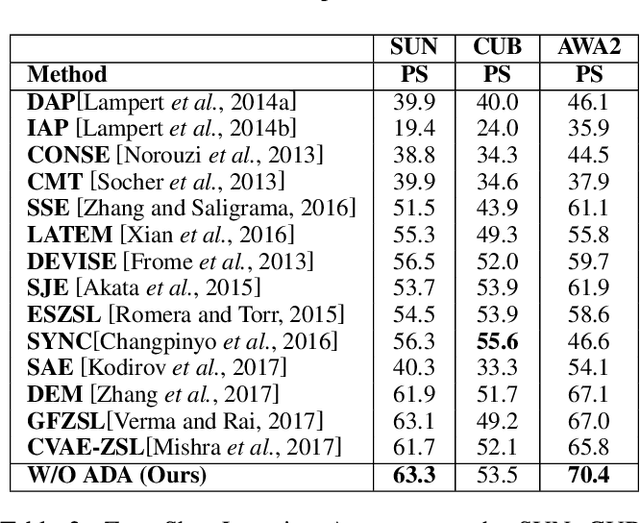
In this paper, we present a domain adaptation based generative framework for Zero-Shot Learning. We explicitly target the problem of domain shift between the seen and unseen class distribution in Zero-Shot Learning (ZSL) and seek to minimize it by developing a generative model and training it via adversarial domain adaptation. Our approach is based on end-to-end learning of the class distributions of seen classes and unseen classes. To enable the model to learn the class distributions of unseen classes, we parameterize these class distributions in terms of the class attribute information (which is available for both seen and unseen classes). This provides a very simple way to learn the class distribution of any unseen class, given only its class attribute information, and no labeled training data. Training this model with adversarial domain adaptation provides robustness against the distribution mismatch between the data from seen and unseen classes. Through a comprehensive set of experiments, we show that our model yields superior accuracies as compared to various state-of-the-art ZSL models, on a variety of benchmark datasets.