 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Understanding to Erasing: Towards Complete and Stable Video Object Removal
Apr 02, 2026Video object removal aims to eliminate target objects from videos while plausibly completing missing regions and preserving spatio-temporal consistency. Although diffusion models have recently advanced this task, it remains challenging to remove object-induced side effects (e.g., shadows, reflections, and illumination changes) without compromising overall coherence. This limitation stems from the insufficient physical and semantic understanding of the target object and its interactions with the scene. In this paper, we propose to introduce understanding into erasing from two complementary perspectives. Externally, we introduce a distillation scheme that transfers the relationships between objects and their induced effects from vision foundation models to video diffusion models. Internally, we propose a framewise context cross-attention mechanism that grounds each denoising block in informative, unmasked context surrounding the target region. External and internal guidance jointly enable our model to understand the target object, its induced effects, and the global background context, resulting in clear and coherent object removal. Extensive experiments demonstrate our state-of-the-art performance, and we establish the first real-world benchmark for video object removal to facilitate future research and community progress. Our code, data, and models are available at: https://github.com/WeChatCV/UnderEraser.
Identity as Presence: Towards Appearance and Voice Personalized Joint Audio-Video Generation
Mar 18, 2026Recent advances have demonstrated compelling capabilities in synthesizing real individuals into generated videos, reflecting the growing demand for identity-aware content creation. Nevertheless, an openly accessible framework enabling fine-grained control over facial appearance and voice timbre across multiple identities remains unavailable. In this work, we present a unified and scalable framework for identity-aware joint audio-video generation, enabling high-fidelity and consistent personalization. Specifically, we introduce a data curation pipeline that automatically extracts identity-bearing information with paired annotations across audio and visual modalities, covering diverse scenarios from single-subject to multi-subject interactions. We further propose a flexible and scalable identity injection mechanism for single- and multi-subject scenarios, in which both facial appearance and vocal timbre act as identity-bearing control signals. Moreover, in light of modality disparity, we design a multi-stage training strategy to accelerate convergence and enforce cross-modal coherence. Experiments demonstrate the superiority of the proposed framework. For more details and qualitative results, please refer to our webpage: \href{https://chen-yingjie.github.io/projects/Identity-as-Presence}{Identity-as-Presence}.
LaRender: Training-Free Occlusion Control in Image Generation via Latent Rendering
Aug 11, 2025
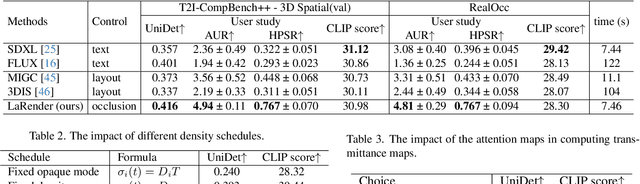


We propose a novel training-free image generation algorithm that precisely controls the occlusion relationships between objects in an image. Existing image generation methods typically rely on prompts to influence occlusion, which often lack precision. While layout-to-image methods provide control over object locations, they fail to address occlusion relationships explicitly. Given a pre-trained image diffusion model, our method leverages volume rendering principles to "render" the scene in latent space, guided by occlusion relationships and the estimated transmittance of objects. This approach does not require retraining or fine-tuning the image diffusion model, yet it enables accurate occlusion control due to its physics-grounded foundation. In extensive experiments, our method significantly outperforms existing approaches in terms of occlusion accuracy. Furthermore, we demonstrate that by adjusting the opacities of objects or concepts during rendering, our method can achieve a variety of effects, such as altering the transparency of objects, the density of mass (e.g., forests), the concentration of particles (e.g., rain, fog), the intensity of light, and the strength of lens effects, etc.