 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Expressive Power of Tuning Only the Norm Layers
Feb 15, 2023Feature normalization transforms such as Batch and Layer-Normalization have become indispensable ingredients of state-of-the-art deep neural networks. Recent studies on fine-tuning large pretrained models indicate that just tuning the parameters of these affine transforms can achieve high accuracy for downstream tasks. These findings open the questions about the expressive power of tuning the normalization layers of frozen networks. In this work, we take the first step towards this question and show that for random ReLU networks, fine-tuning only its normalization layers can reconstruct any target network that is $O(\sqrt{\text{width}})$ times smaller. We show that this holds even for randomly sparsified networks, under sufficient overparameterization, in agreement with prior empirical work.
Looped Transformers as Programmable Computers
Jan 30, 2023



We present a framework for using transformer networks as universal computers by programming them with specific weights and placing them in a loop. Our input sequence acts as a punchcard, consisting of instructions and memory for data read/writes. We demonstrate that a constant number of encoder layers can emulate basic computing blocks, including embedding edit operations, non-linear functions, function calls, program counters, and conditional branches. Using these building blocks, we emulate a small instruction-set computer. This allows us to map iterative algorithms to programs that can be executed by a looped, 13-layer transformer. We show how this transformer, instructed by its input, can emulate a basic calculator, a basic linear algebra library, and in-context learning algorithms that employ backpropagation. Our work highlights the versatility of the attention mechanism, and demonstrates that even shallow transformers can execute full-fledged, general-purpose programs.
Transformers as Algorithms: Generalization and Implicit Model Selection in In-context Learning
Jan 17, 2023



In-context learning (ICL) is a type of prompting where a transformer model operates on a sequence of (input, output) examples and performs inference on-the-fly. This implicit training is in contrast to explicitly tuning the model weights based on examples. In this work, we formalize in-context learning as an algorithm learning problem, treating the transformer model as a learning algorithm that can be specialized via training to implement-at inference-time-another target algorithm. We first explore the statistical aspects of this abstraction through the lens of multitask learning: We obtain generalization bounds for ICL when the input prompt is (1) a sequence of i.i.d. (input, label) pairs or (2) a trajectory arising from a dynamical system. The crux of our analysis is relating the excess risk to the stability of the algorithm implemented by the transformer, which holds under mild assumptions. Secondly, we use our abstraction to show that transformers can act as an adaptive learning algorithm and perform model selection across different hypothesis classes. We provide numerical evaluations that (1) demonstrate transformers can indeed implement near-optimal algorithms on classical regression problems with i.i.d. and dynamic data, (2) identify an inductive bias phenomenon where the transfer risk on unseen tasks is independent of the transformer complexity, and (3) empirically verify our theoretical predictions.
A Better Way to Decay: Proximal Gradient Training Algorithms for Neural Nets
Oct 06, 2022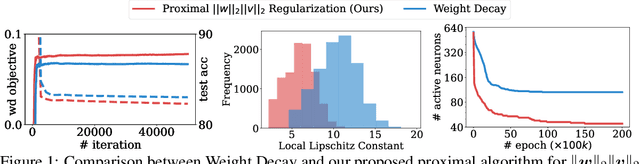
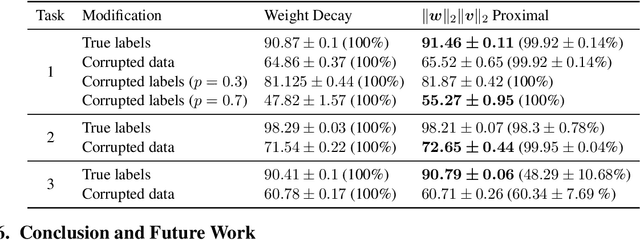

Weight decay is one of the most widely used forms of regularization in deep learning, and has been shown to improve generalization and robustness. The optimization objective driving weight decay is a sum of losses plus a term proportional to the sum of squared weights. This paper argues that stochastic gradient descent (SGD) may be an inefficient algorithm for this objective. For neural networks with ReLU activations, solutions to the weight decay objective are equivalent to those of a different objective in which the regularization term is instead a sum of products of $\ell_2$ (not squared) norms of the input and output weights associated each ReLU. This alternative (and effectively equivalent) regularization suggests a novel proximal gradient algorithm for network training. Theory and experiments support the new training approach, showing that it can converge much faster to the sparse solutions it shares with standard weight decay training.
LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
Jun 15, 2022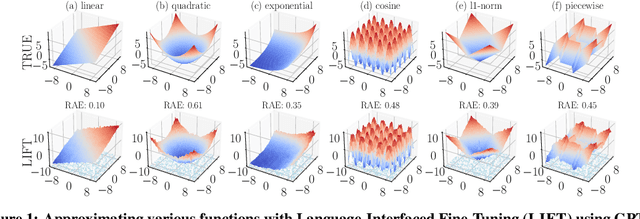
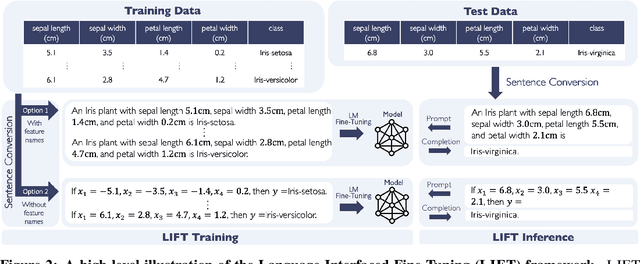

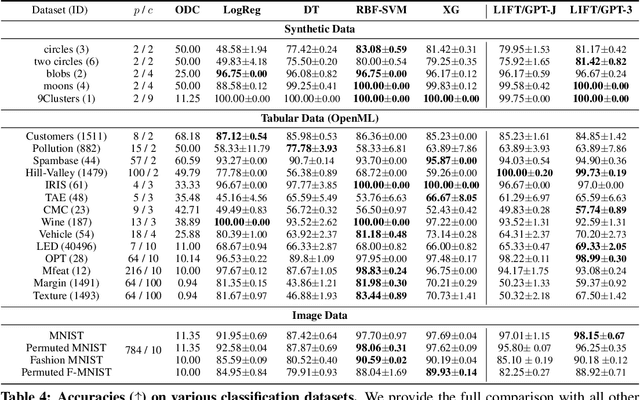
Fine-tuning pretrained language models (LMs) without making any architectural changes has become a norm for learning various language downstream tasks. However, for non-language downstream tasks, a common practice is to employ task-specific designs for input, output layers, and loss functions. For instance, it is possible to fine-tune an LM into an MNIST classifier by replacing the word embedding layer with an image patch embedding layer, the word token output layer with a 10-way output layer, and the word prediction loss with a 10-way classification loss, respectively. A natural question arises: can LM fine-tuning solve non-language downstream tasks without changing the model architecture or loss function? To answer this, we propose Language-Interfaced Fine-Tuning (LIFT) and study its efficacy and limitations by conducting an extensive empirical study on a suite of non-language classification and regression tasks. LIFT does not make any changes to the model architecture or loss function, and it solely relies on the natural language interface, enabling "no-code machine learning with LMs." We find that LIFT performs relatively well across a wide range of low-dimensional classification and regression tasks, matching the performances of the best baselines in many cases, especially for the classification tasks. We report the experimental results on the fundamental properties of LIFT, including its inductive bias, sample efficiency, ability to extrapolate, robustness to outliers and label noise, and generalization. We also analyze a few properties/techniques specific to LIFT, e.g., context-aware learning via appropriate prompting, quantification of predictive uncertainty, and two-stage fine-tuning. Our code is available at https://github.com/UW-Madison-Lee-Lab/LanguageInterfacedFineTuning.
Utilizing Language-Image Pretraining for Efficient and Robust Bilingual Word Alignment
May 23, 2022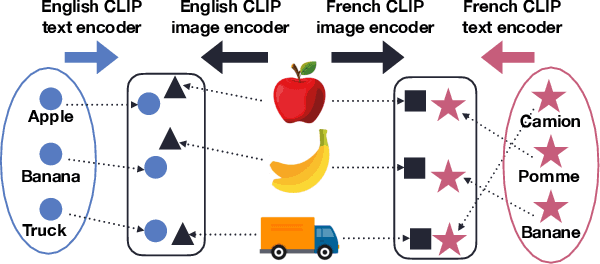
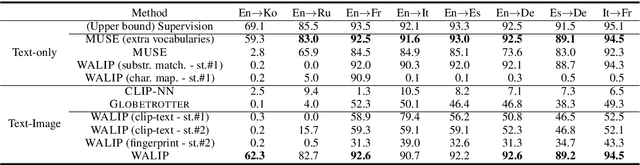
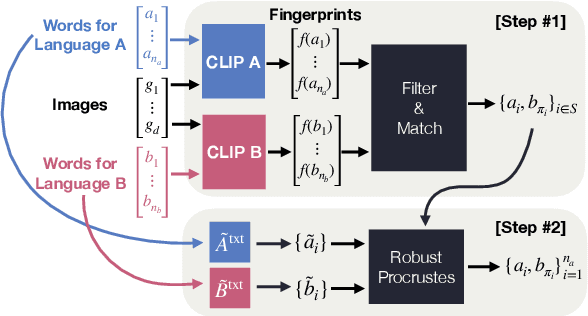
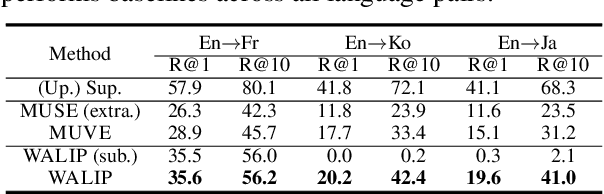
Word translation without parallel corpora has become feasible, rivaling the performance of supervised methods. Recent findings have shown that the accuracy and robustness of unsupervised word translation (UWT) can be improved by making use of visual observations, which are universal representations across languages. In this work, we investigate the potential of using not only visual observations but also pretrained language-image models for enabling a more efficient and robust UWT. Specifically, we develop a novel UWT method dubbed Word Alignment using Language-Image Pretraining (WALIP), which leverages visual observations via the shared embedding space of images and texts provided by CLIP models (Radford et al., 2021). WALIP has a two-step procedure. First, we retrieve word pairs with high confidences of similarity, computed using our proposed image-based fingerprints, which define the initial pivot for the word alignment. Second, we apply our robust Procrustes algorithm to estimate the linear mapping between two embedding spaces, which iteratively corrects and refines the estimated alignment. Our extensive experiments show that WALIP improves upon the state-of-the-art performance of bilingual word alignment for a few language pairs across different word embeddings and displays great robustness to the dissimilarity of language pairs or training corpora for two word embeddings.
Rare Gems: Finding Lottery Tickets at Initialization
Feb 24, 2022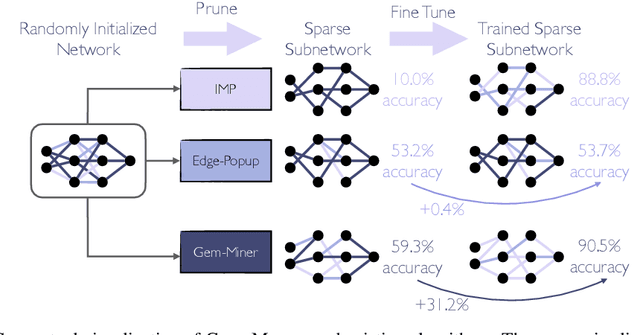

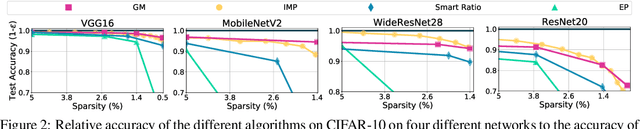

It has been widely observed that large neural networks can be pruned to a small fraction of their original size, with little loss in accuracy, by typically following a time-consuming "train, prune, re-train" approach. Frankle & Carbin (2018) conjecture that we can avoid this by training lottery tickets, i.e., special sparse subnetworks found at initialization, that can be trained to high accuracy. However, a subsequent line of work presents concrete evidence that current algorithms for finding trainable networks at initialization, fail simple baseline comparisons, e.g., against training random sparse subnetworks. Finding lottery tickets that train to better accuracy compared to simple baselines remains an open problem. In this work, we partially resolve this open problem by discovering rare gems: subnetworks at initialization that attain considerable accuracy, even before training. Refining these rare gems - "by means of fine-tuning" - beats current baselines and leads to accuracy competitive or better than magnitude pruning methods.
GenLabel: Mixup Relabeling using Generative Models
Jan 07, 2022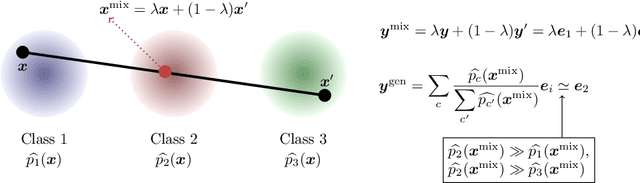

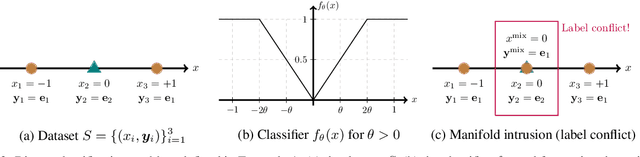

Mixup is a data augmentation method that generates new data points by mixing a pair of input data. While mixup generally improves the prediction performance, it sometimes degrades the performance. In this paper, we first identify the main causes of this phenomenon by theoretically and empirically analyzing the mixup algorithm. To resolve this, we propose GenLabel, a simple yet effective relabeling algorithm designed for mixup. In particular, GenLabel helps the mixup algorithm correctly label mixup samples by learning the class-conditional data distribution using generative models. Via extensive theoretical and empirical analysis, we show that mixup, when used together with GenLabel, can effectively resolve the aforementioned phenomenon, improving the generalization performance and the adversarial robustness.
Finding Everything within Random Binary Networks
Oct 22, 2021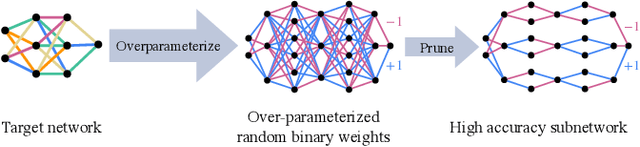

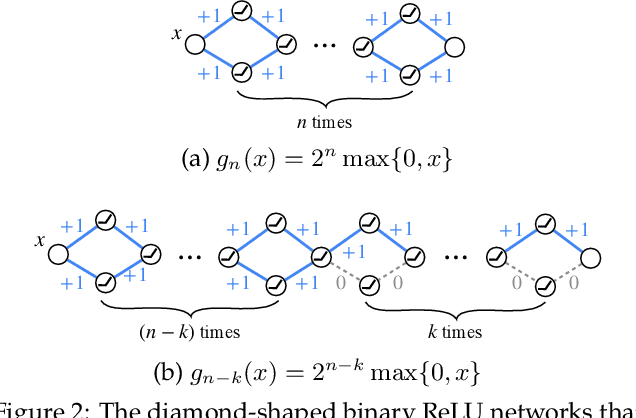
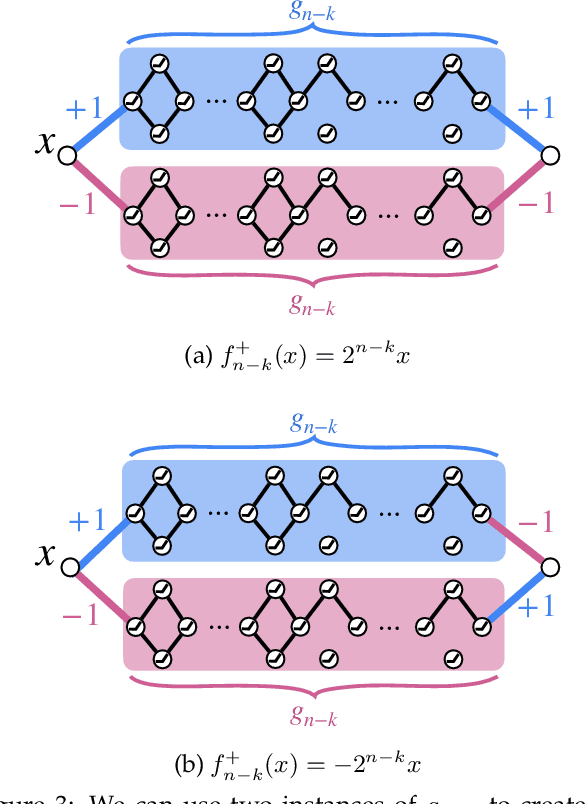
A recent work by Ramanujan et al. (2020) provides significant empirical evidence that sufficiently overparameterized, random neural networks contain untrained subnetworks that achieve state-of-the-art accuracy on several predictive tasks. A follow-up line of theoretical work provides justification of these findings by proving that slightly overparameterized neural networks, with commonly used continuous-valued random initializations can indeed be pruned to approximate any target network. In this work, we show that the amplitude of those random weights does not even matter. We prove that any target network can be approximated up to arbitrary accuracy by simply pruning a random network of binary $\{\pm1\}$ weights that is only a polylogarithmic factor wider and deeper than the target network.
An Exponential Improvement on the Memorization Capacity of Deep Threshold Networks
Jun 14, 2021
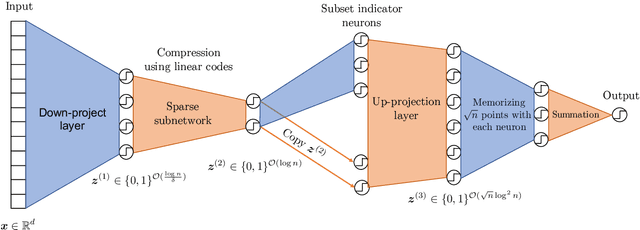
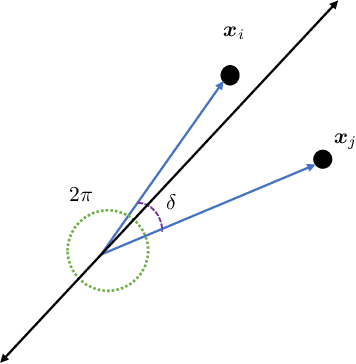
It is well known that modern deep neural networks are powerful enough to memorize datasets even when the labels have been randomized. Recently, Vershynin (2020) settled a long standing question by Baum (1988), proving that \emph{deep threshold} networks can memorize $n$ points in $d$ dimensions using $\widetilde{\mathcal{O}}(e^{1/\delta^2}+\sqrt{n})$ neurons and $\widetilde{\mathcal{O}}(e^{1/\delta^2}(d+\sqrt{n})+n)$ weights, where $\delta$ is the minimum distance between the points. In this work, we improve the dependence on $\delta$ from exponential to almost linear, proving that $\widetilde{\mathcal{O}}(\frac{1}{\delta}+\sqrt{n})$ neurons and $\widetilde{\mathcal{O}}(\frac{d}{\delta}+n)$ weights are sufficient. Our construction uses Gaussian random weights only in the first layer, while all the subsequent layers use binary or integer weights. We also prove new lower bounds by connecting memorization in neural networks to the purely geometric problem of separating $n$ points on a sphere using hyperplanes.