 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccordion: Adaptive Gradient Communication via Critical Learning Regime Identification
Paper and Code
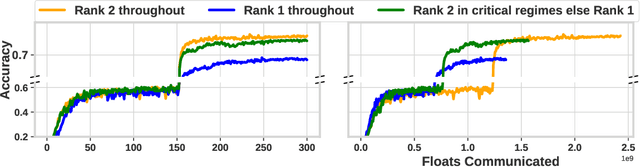
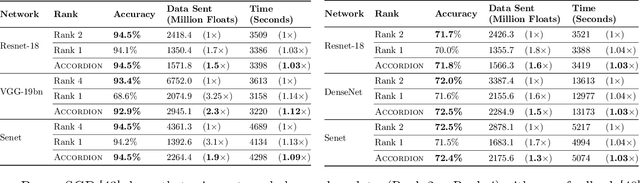
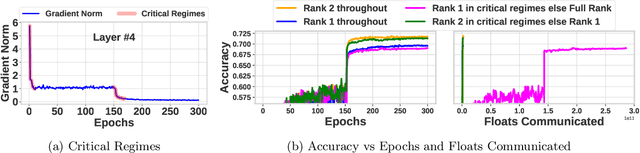
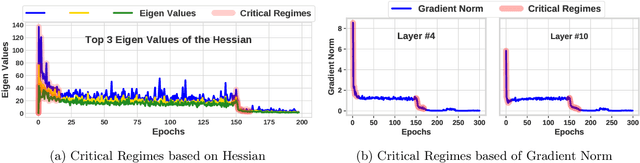
Distributed model training suffers from communication bottlenecks due to frequent model updates transmitted across compute nodes. To alleviate these bottlenecks, practitioners use gradient compression techniques like sparsification, quantization, or low-rank updates. The techniques usually require choosing a static compression ratio, often requiring users to balance the trade-off between model accuracy and per-iteration speedup. In this work, we show that such performance degradation due to choosing a high compression ratio is not fundamental. An adaptive compression strategy can reduce communication while maintaining final test accuracy. Inspired by recent findings on critical learning regimes, in which small gradient errors can have irrecoverable impact on model performance, we propose Accordion a simple yet effective adaptive compression algorithm. While Accordion maintains a high enough compression rate on average, it avoids over-compressing gradients whenever in critical learning regimes, detected by a simple gradient-norm based criterion. Our extensive experimental study over a number of machine learning tasks in distributed environments indicates that Accordion, maintains similar model accuracy to uncompressed training, yet achieves up to 5.5x better compression and up to 4.1x end-to-end speedup over static approaches. We show that Accordion also works for adjusting the batch size, another popular strategy for alleviating communication bottlenecks.