 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreekBarBench: A Challenging Benchmark for Free-Text Legal Reasoning and Citations
May 22, 2025We introduce GreekBarBench, a benchmark that evaluates LLMs on legal questions across five different legal areas from the Greek Bar exams, requiring citations to statutory articles and case facts. To tackle the challenges of free-text evaluation, we propose a three-dimensional scoring system combined with an LLM-as-a-judge approach. We also develop a meta-evaluation benchmark to assess the correlation between LLM-judges and human expert evaluations, revealing that simple, span-based rubrics improve their alignment. Our systematic evaluation of 13 proprietary and open-weight LLMs shows that even though the best models outperform average expert scores, they fall short of the 95th percentile of experts.
LAR-ECHR: A New Legal Argument Reasoning Task and Dataset for Cases of the European Court of Human Rights
Oct 17, 2024



We present Legal Argument Reasoning (LAR), a novel task designed to evaluate the legal reasoning capabilities of Large Language Models (LLMs). The task requires selecting the correct next statement (from multiple choice options) in a chain of legal arguments from court proceedings, given the facts of the case. We constructed a dataset (LAR-ECHR) for this task using cases from the European Court of Human Rights (ECHR). We evaluated seven general-purpose LLMs on LAR-ECHR and found that (a) the ranking of the models is aligned with that of LegalBench, an established US-based legal reasoning benchmark, even though LAR-ECHR is based on EU law, (b) LAR-ECHR distinguishes top models more clearly, compared to LegalBench, (c) even the best model (GPT-4o) obtains 75.8% accuracy on LAR-ECHR, indicating significant potential for further model improvement. The process followed to construct LAR-ECHR can be replicated with cases from other legal systems.
Archimedes-AUEB at SemEval-2024 Task 5: LLM explains Civil Procedure
May 14, 2024



The SemEval task on Argument Reasoning in Civil Procedure is challenging in that it requires understanding legal concepts and inferring complex arguments. Currently, most Large Language Models (LLM) excelling in the legal realm are principally purposed for classification tasks, hence their reasoning rationale is subject to contention. The approach we advocate involves using a powerful teacher-LLM (ChatGPT) to extend the training dataset with explanations and generate synthetic data. The resulting data are then leveraged to fine-tune a small student-LLM. Contrary to previous work, our explanations are not directly derived from the teacher's internal knowledge. Instead they are grounded in authentic human analyses, therefore delivering a superior reasoning signal. Additionally, a new `mutation' method generates artificial data instances inspired from existing ones. We are publicly releasing the explanations as an extension to the original dataset, along with the synthetic dataset and the prompts that were used to generate both. Our system ranked 15th in the SemEval competition. It outperforms its own teacher and can produce explanations aligned with the original human analyses, as verified by legal experts.
Towards an Interoperable Ecosystem of AI and LT Platforms: A Roadmap for the Implementation of Different Levels of Interoperability
Apr 17, 2020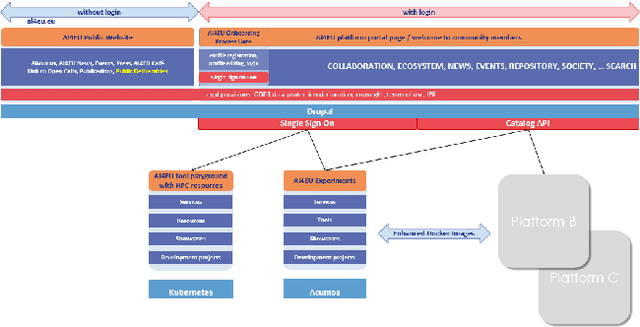
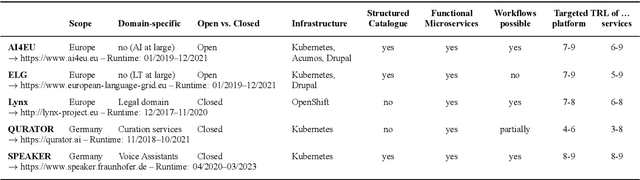

With regard to the wider area of AI/LT platform interoperability, we concentrate on two core aspects: (1) cross-platform search and discovery of resources and services; (2) composition of cross-platform service workflows. We devise five different levels (of increasing complexity) of platform interoperability that we suggest to implement in a wider federation of AI/LT platforms. We illustrate the approach using the five emerging AI/LT platforms AI4EU, ELG, Lynx, QURATOR and SPEAKER.
Making Metadata Fit for Next Generation Language Technology Platforms: The Metadata Schema of the European Language Grid
Mar 30, 2020
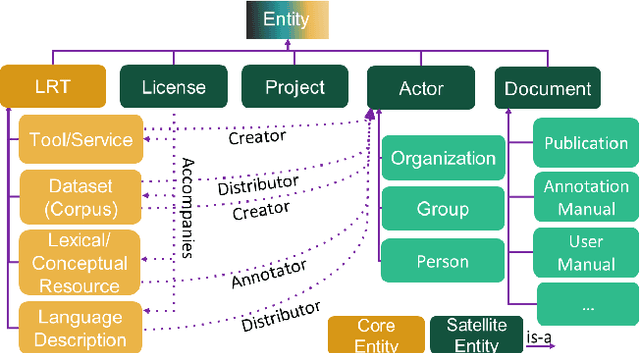
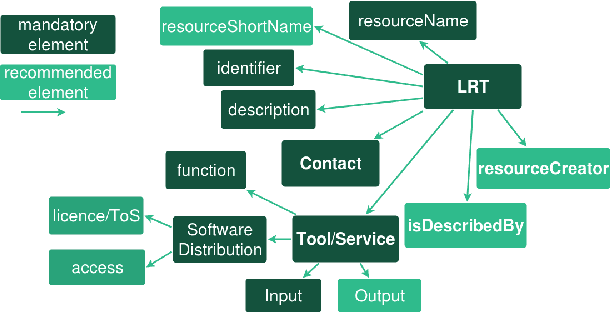

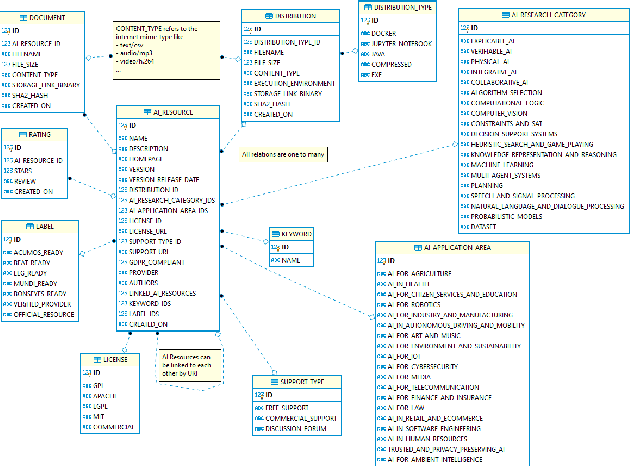
The current scientific and technological landscape is characterised by the increasing availability of data resources and processing tools and services. In this setting, metadata have emerged as a key factor facilitating management, sharing and usage of such digital assets. In this paper we present ELG-SHARE, a rich metadata schema catering for the description of Language Resources and Technologies (processing and generation services and tools, models, corpora, term lists, etc.), as well as related entities (e.g., organizations, projects, supporting documents, etc.). The schema powers the European Language Grid platform that aims to be the primary hub and marketplace for industry-relevant Language Technology in Europe. ELG-SHARE has been based on various metadata schemas, vocabularies, and ontologies, as well as related recommendations and guidelines.
Generating Natural Language Descriptions from OWL Ontologies: the NaturalOWL System
Apr 24, 2014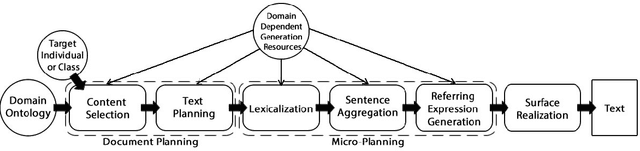
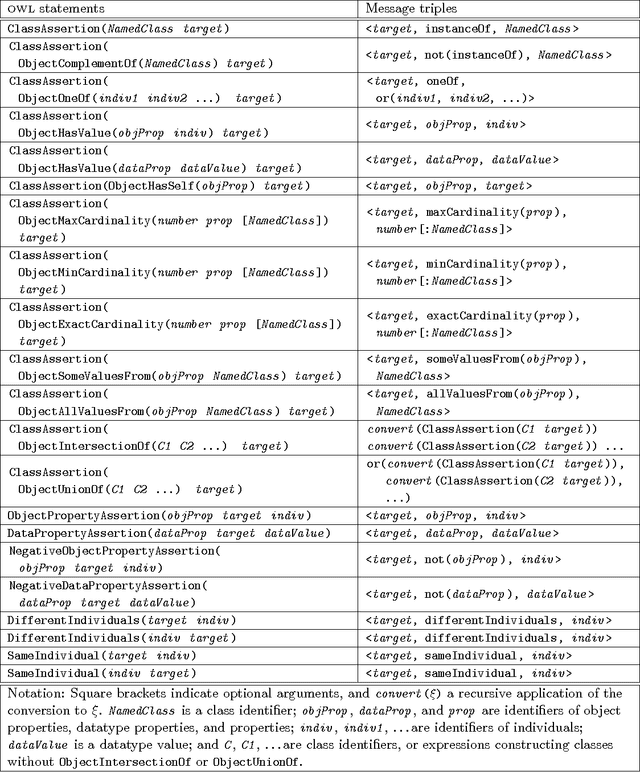
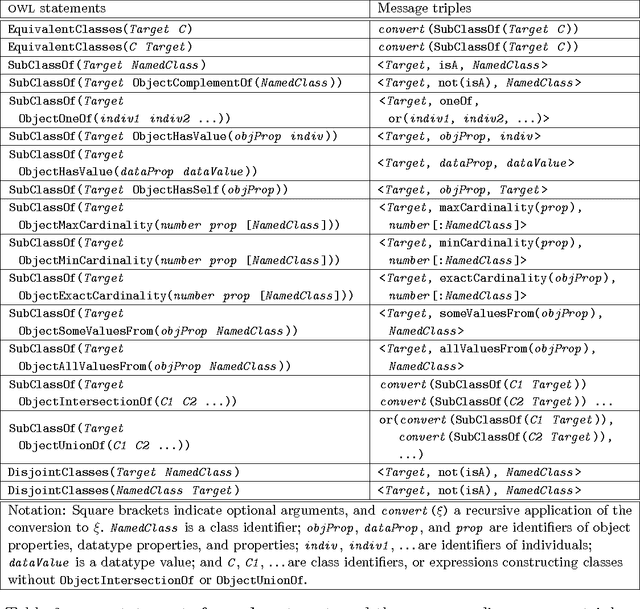
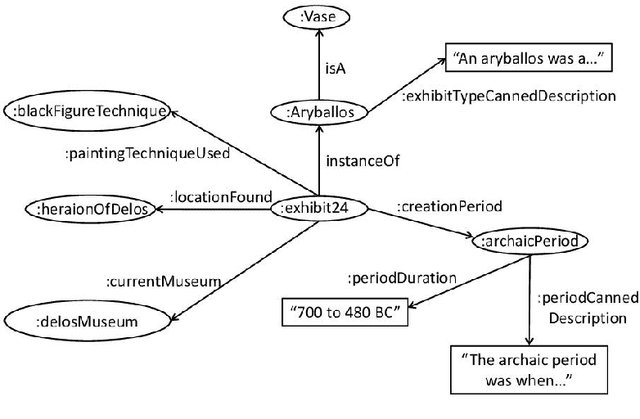
We present NaturalOWL, a natural language generation system that produces texts describing individuals or classes of OWL ontologies. Unlike simpler OWL verbalizers, which typically express a single axiom at a time in controlled, often not entirely fluent natural language primarily for the benefit of domain experts, we aim to generate fluent and coherent multi-sentence texts for end-users. With a system like NaturalOWL, one can publish information in OWL on the Web, along with automatically produced corresponding texts in multiple languages, making the information accessible not only to computer programs and domain experts, but also end-users. We discuss the processing stages of NaturalOWL, the optional domain-dependent linguistic resources that the system can use at each stage, and why they are useful. We also present trials showing that when the domain-dependent llinguistic resources are available, NaturalOWL produces significantly better texts compared to a simpler verbalizer, and that the resources can be created with relatively light effort.