 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Transformer Transducer Based Speech Recognition Using Non-Causal Convolution
Oct 07, 2021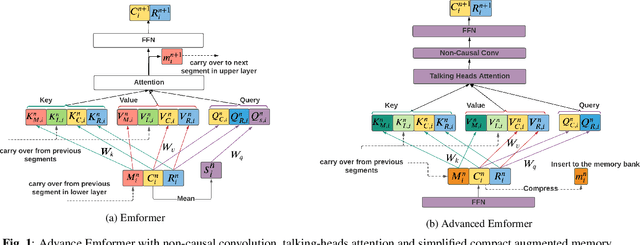
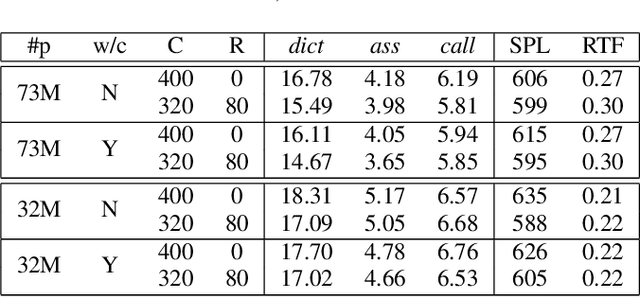
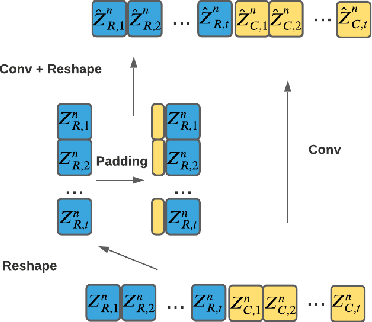
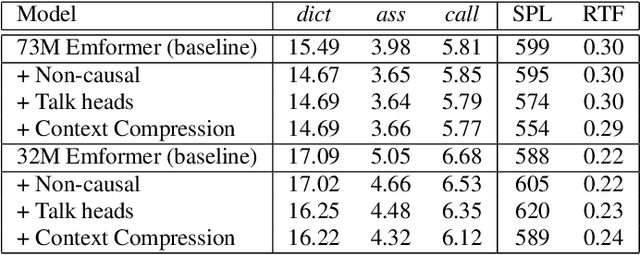
This paper improves the streaming transformer transducer for speech recognition by using non-causal convolution. Many works apply the causal convolution to improve streaming transformer ignoring the lookahead context. We propose to use non-causal convolution to process the center block and lookahead context separately. This method leverages the lookahead context in convolution and maintains similar training and decoding efficiency. Given the similar latency, using the non-causal convolution with lookahead context gives better accuracy than causal convolution, especially for open-domain dictation scenarios. Besides, this paper applies talking-head attention and a novel history context compression scheme to further improve the performance. The talking-head attention improves the multi-head self-attention by transferring information among different heads. The history context compression method introduces more extended history context compactly. On our in-house data, the proposed methods improve a small Emformer baseline with lookahead context by relative WERR 5.1\%, 14.5\%, 8.4\% on open-domain dictation, assistant general scenarios, and assistant calling scenarios, respectively.
Noisy Training Improves E2E ASR for the Edge
Jul 09, 2021
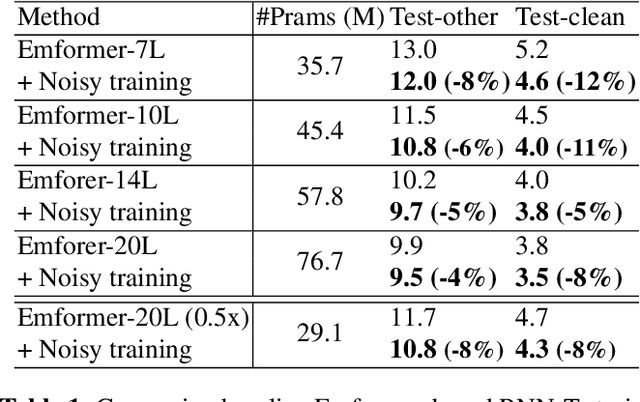
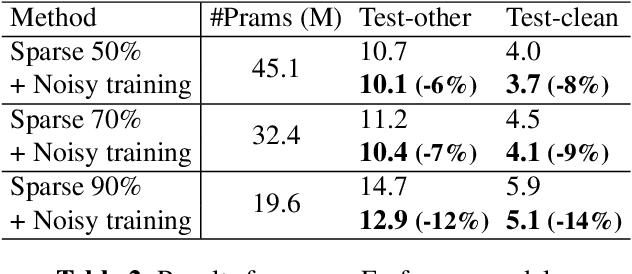
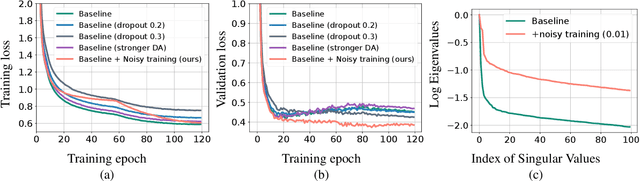
Automatic speech recognition (ASR) has become increasingly ubiquitous on modern edge devices. Past work developed streaming End-to-End (E2E) all-neural speech recognizers that can run compactly on edge devices. However, E2E ASR models are prone to overfitting and have difficulties in generalizing to unseen testing data. Various techniques have been proposed to regularize the training of ASR models, including layer normalization, dropout, spectrum data augmentation and speed distortions in the inputs. In this work, we present a simple yet effective noisy training strategy to further improve the E2E ASR model training. By introducing random noise to the parameter space during training, our method can produce smoother models at convergence that generalize better. We apply noisy training to improve both dense and sparse state-of-the-art Emformer models and observe consistent WER reduction. Specifically, when training Emformers with 90% sparsity, we achieve 12% and 14% WER improvements on the LibriSpeech Test-other and Test-clean data set, respectively.
Improve Vision Transformers Training by Suppressing Over-smoothing
Apr 26, 2021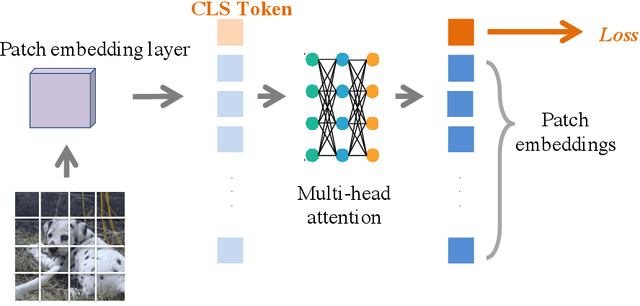

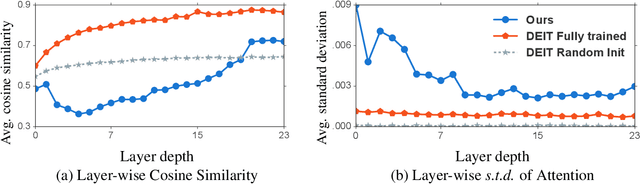
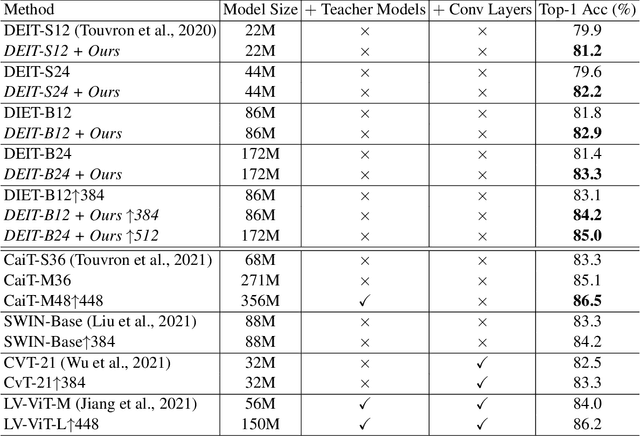
Introducing the transformer structure into computer vision tasks holds the promise of yielding a better speed-accuracy trade-off than traditional convolution networks. However, directly training vanilla transformers on vision tasks has been shown to yield unstable and sub-optimal results. As a result, recent works propose to modify transformer structures by incorporating convolutional layers to improve the performance on vision tasks. This work investigates how to stabilize the training of vision transformers \emph{without} special structure modification. We observe that the instability of transformer training on vision tasks can be attributed to the over-smoothing problem, that the self-attention layers tend to map the different patches from the input image into a similar latent representation, hence yielding the loss of information and degeneration of performance, especially when the number of layers is large. We then propose a number of techniques to alleviate this problem, including introducing additional loss functions to encourage diversity, prevent loss of information, and discriminate different patches by additional patch classification loss for Cutmix. We show that our proposed techniques stabilize the training and allow us to train wider and deeper vision transformers, achieving 85.0\% top-1 accuracy on ImageNet validation set without introducing extra teachers or additional convolution layers. Our code will be made publicly available at https://github.com/ChengyueGongR/PatchVisionTransformer .
AlphaNet: Improved Training of Supernet with Alpha-Divergence
Feb 16, 2021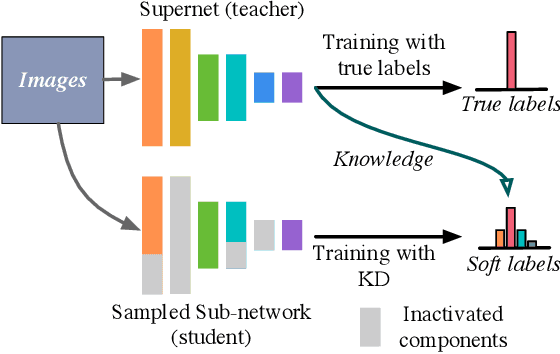
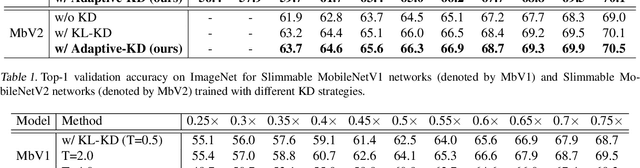
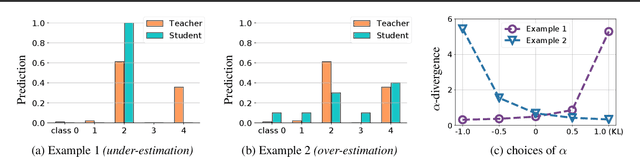
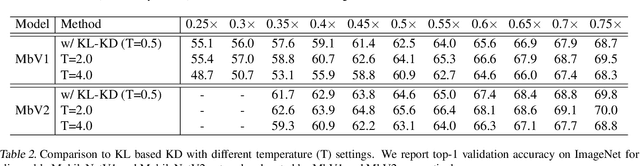
Weight-sharing neural architecture search (NAS) is an effective technique for automating efficient neural architecture design. Weight-sharing NAS builds a supernet that assembles all the architectures as its sub-networks and jointly trains the supernet with the sub-networks. The success of weight-sharing NAS heavily relies on distilling the knowledge of the supernet to the sub-networks. However, we find that the widely used distillation divergence, i.e., KL divergence, may lead to student sub-networks that over-estimate or under-estimate the uncertainty of the teacher supernet, leading to inferior performance of the sub-networks. In this work, we propose to improve the supernet training with a more generalized alpha-divergence. By adaptively selecting the alpha-divergence, we simultaneously prevent the over-estimation or under-estimation of the uncertainty of the teacher model. We apply the proposed alpha-divergence based supernet training to both slimmable neural networks and weight-sharing NAS, and demonstrate significant improvements. Specifically, our discovered model family, AlphaNet, outperforms prior-art models on a wide range of FLOPs regimes, including BigNAS, Once-for-All networks, FBNetV3, and AttentiveNAS. We achieve ImageNet top-1 accuracy of 80.0% with only 444 MFLOPs.
AlphaMatch: Improving Consistency for Semi-supervised Learning with Alpha-divergence
Nov 23, 2020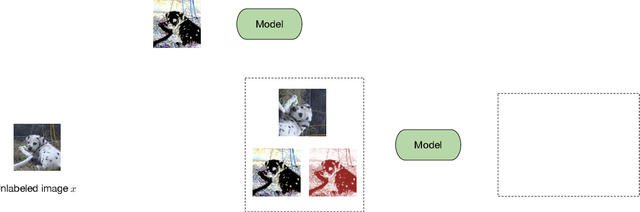
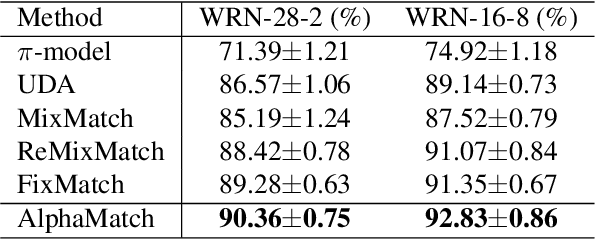
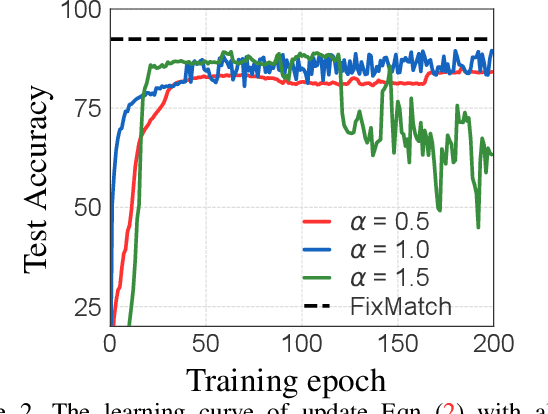
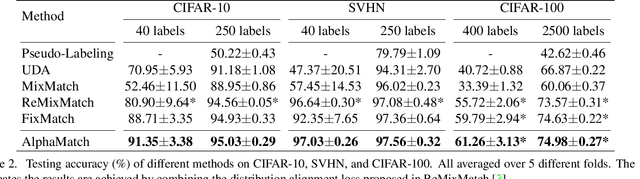
Semi-supervised learning (SSL) is a key approach toward more data-efficient machine learning by jointly leverage both labeled and unlabeled data. We propose AlphaMatch, an efficient SSL method that leverages data augmentations, by efficiently enforcing the label consistency between the data points and the augmented data derived from them. Our key technical contribution lies on: 1) using alpha-divergence to prioritize the regularization on data with high confidence, achieving a similar effect as FixMatch but in a more flexible fashion, and 2) proposing an optimization-based, EM-like algorithm to enforce the consistency, which enjoys better convergence than iterative regularization procedures used in recent SSL methods such as FixMatch, UDA, and MixMatch. AlphaMatch is simple and easy to implement, and consistently outperforms prior arts on standard benchmarks, e.g. CIFAR-10, SVHN, CIFAR-100, STL-10. Specifically, we achieve 91.3% test accuracy on CIFAR-10 with just 4 labelled data per class, substantially improving over the previously best 88.7% accuracy achieved by FixMatch.
KeepAugment: A Simple Information-Preserving Data Augmentation Approach
Nov 23, 2020
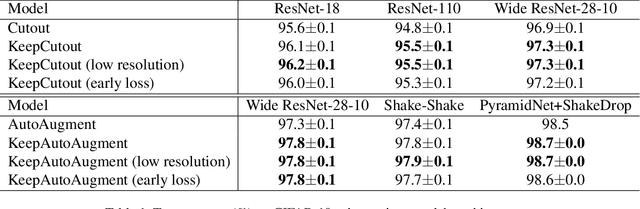
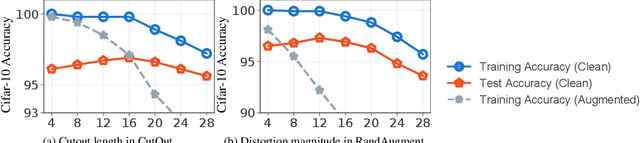
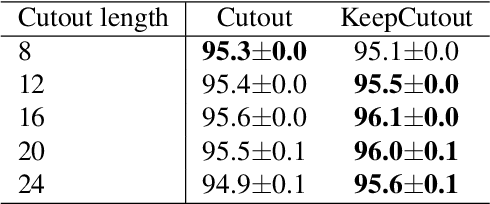
Data augmentation (DA) is an essential technique for training state-of-the-art deep learning systems. In this paper, we empirically show data augmentation might introduce noisy augmented examples and consequently hurt the performance on unaugmented data during inference. To alleviate this issue, we propose a simple yet highly effective approach, dubbed \emph{KeepAugment}, to increase augmented images fidelity. The idea is first to use the saliency map to detect important regions on the original images and then preserve these informative regions during augmentation. This information-preserving strategy allows us to generate more faithful training examples. Empirically, we demonstrate our method significantly improves on a number of prior art data augmentation schemes, e.g. AutoAugment, Cutout, random erasing, achieving promising results on image classification, semi-supervised image classification, multi-view multi-camera tracking and object detection.
AttentiveNAS: Improving Neural Architecture Search via Attentive Sampling
Nov 18, 2020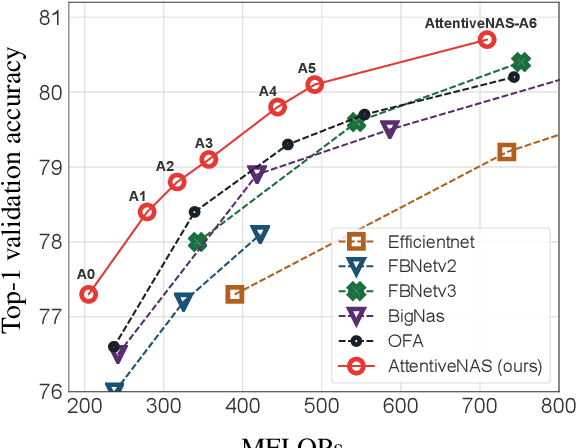
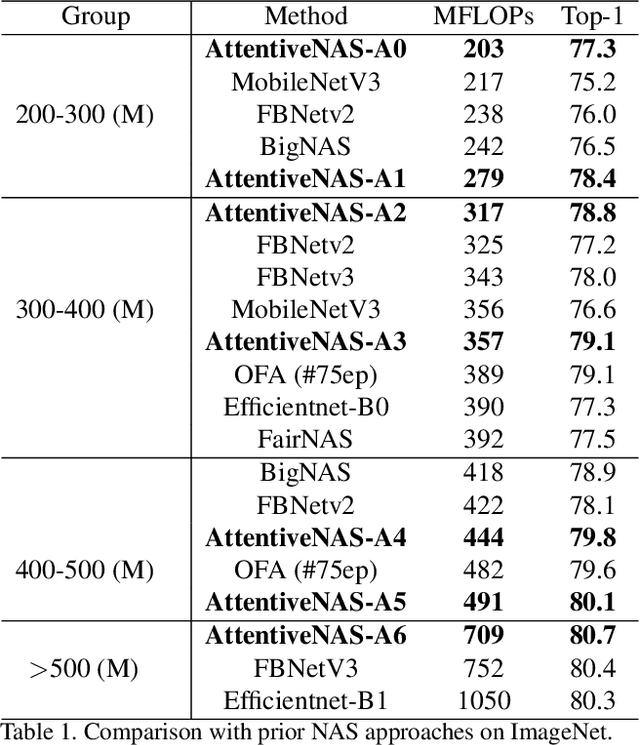
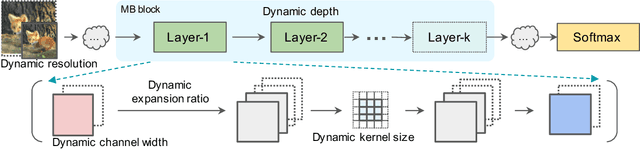

Neural architecture search (NAS) has shown great promise designing state-of-the-art (SOTA) models that are both accurate and fast. Recently, two-stage NAS, e.g. BigNAS, decouples the model training and searching process and achieves good search efficiency. Two-stage NAS requires sampling from the search space during training, which directly impacts the accuracy of the final searched models. While uniform sampling has been widely used for simplicity, it is agnostic of the model performance Pareto front, which are the main focus in the search process, and thus, misses opportunities to further improve the model accuracy. In this work, we propose AttentiveNAS that focuses on sampling the networks to improve the performance Pareto. We also propose algorithms to efficiently and effectively identify the networks on the Pareto during training. Without extra re-training or post-processing, we can simultaneously obtain a large number of networks across a wide range of FLOPs. Our discovered model family, AttentiveNAS models, achieves top-1 accuracy from 77.3% to 80.7% on ImageNet, and outperforms SOTA models, including BigNAS, Once-for-All networks and FBNetV3. We also achieve ImageNet accuracy of 80.1% with only 491 MFLOPs.
Stein Variational Gradient Descent With Matrix-Valued Kernels
Nov 05, 2019
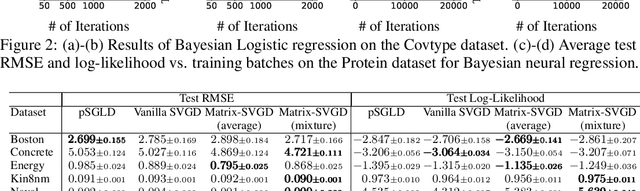
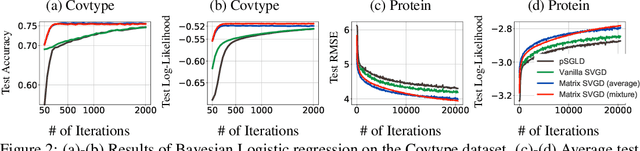
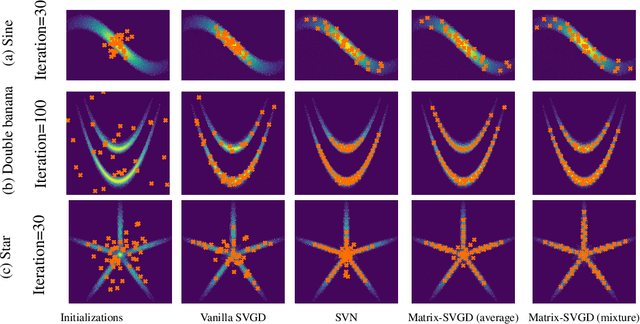
Stein variational gradient descent (SVGD) is a particle-based inference algorithm that leverages gradient information for efficient approximate inference. In this work, we enhance SVGD by leveraging preconditioning matrices, such as the Hessian and Fisher information matrix, to incorporate geometric information into SVGD updates. We achieve this by presenting a generalization of SVGD that replaces the scalar-valued kernels in vanilla SVGD with more general matrix-valued kernels. This yields a significant extension of SVGD, and more importantly, allows us to flexibly incorporate various preconditioning matrices to accelerate the exploration in the probability landscape. Empirical results show that our method outperforms vanilla SVGD and a variety of baseline approaches over a range of real-world Bayesian inference tasks.
Splitting Steepest Descent for Growing Neural Architectures
Nov 04, 2019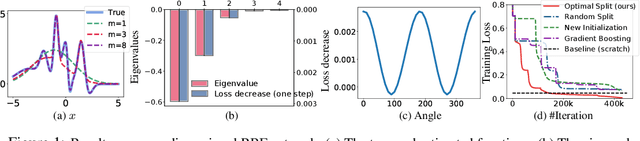
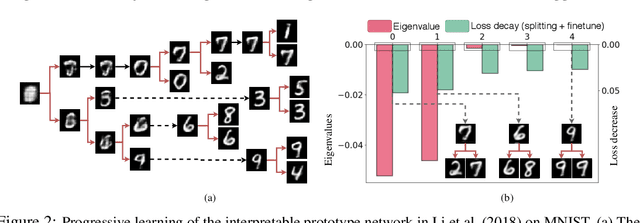
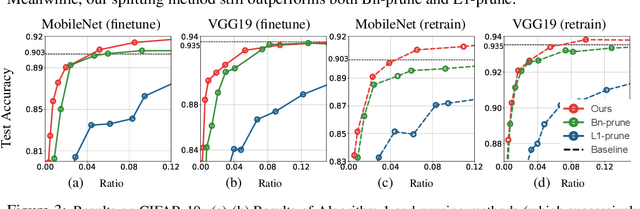
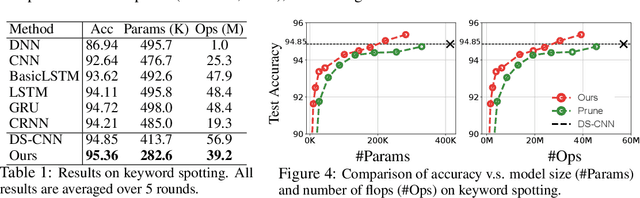
We develop a progressive training approach for neural networks which adaptively grows the network structure by splitting existing neurons to multiple off-springs. By leveraging a functional steepest descent idea, we derive a simple criterion for deciding the best subset of neurons to split and a splitting gradient for optimally updating the off-springs. Theoretically, our splitting strategy is a second-order functional steepest descent for escaping saddle points in an $\infty$-Wasserstein metric space, on which the standard parametric gradient descent is a first-order steepest descent. Our method provides a new computationally efficient approach for optimizing neural network structures, especially for learning lightweight neural architectures in resource-constrained settings.
Energy-Aware Neural Architecture Optimization with Fast Splitting Steepest Descent
Oct 07, 2019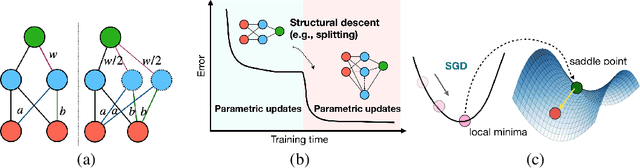
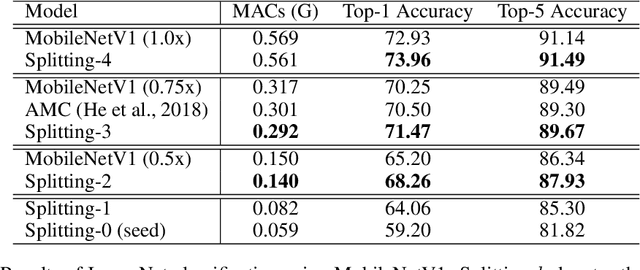
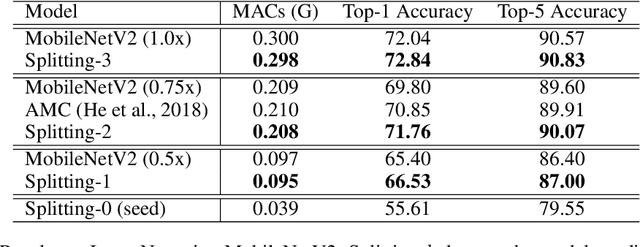
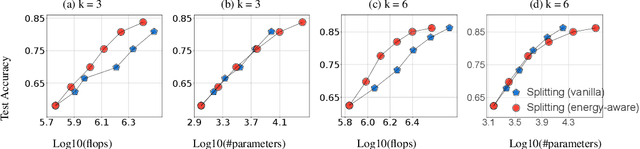
Designing energy-efficient networks is of critical importance for enabling state-of-the-art deep learning in mobile and edge settings where the computation and energy budgets are highly limited. Recently, Wu et al. (2019) framed the search of efficient neural architectures into a continuous splitting process: it iteratively splits existing neurons into multiple off-springs to achieve progressive loss minimization, thus finding novel architectures by gradually growing the neural network. However, this method was not specifically tailored for designing energy-efficient networks, and is computationally expensive on large-scale benchmarks. In this work, we substantially improve Wu et al. (2019) in two significant ways: 1) we incorporate the energy cost of splitting different neurons to better guide the splitting process, thereby discovering more energy-efficient network architectures; 2) we substantially speed up the splitting process of Wu et al. (2019), which requires expensive eigen-decomposition, by proposing a highly scalable Rayleigh-quotient stochastic gradient algorithm. Our fast algorithm allows us to reduce the computational cost of splitting to the same level of typical back-propagation updates and enables efficient implementation on GPU. Extensive empirical results show that our method can train highly accurate and energy-efficient networks on challenging datasets such as ImageNet, improving a variety of baselines, including the pruning-based methods and expert-designed architectures.