 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Classifying Multimodal Sequences
May 02, 2023Often pieces of information are received sequentially over time. When did one collect enough such pieces to classify? Trading wait time for decision certainty leads to early classification problems that have recently gained attention as a means of adapting classification to more dynamic environments. However, so far results have been limited to unimodal sequences. In this pilot study, we expand into early classifying multimodal sequences by combining existing methods. We show our new method yields experimental AUC advantages of up to 8.7%.
A Policy for Early Sequence Classification
Apr 07, 2023Sequences are often not received in their entirety at once, but instead, received incrementally over time, element by element. Early predictions yielding a higher benefit, one aims to classify a sequence as accurately as possible, as soon as possible, without having to wait for the last element. For this early sequence classification, we introduce our novel classifier-induced stopping. While previous methods depend on exploration during training to learn when to stop and classify, ours is a more direct, supervised approach. Our classifier-induced stopping achieves an average Pareto frontier AUC increase of 11.8% over multiple experiments.
Gradient-Boosted Based Structured and Unstructured Learning
Feb 28, 2023



We propose two frameworks to deal with problem settings in which both structured and unstructured data are available. Structured data problems are best solved by traditional machine learning models such as boosting and tree-based algorithms, whereas deep learning has been widely applied to problems dealing with images, text, audio, and other unstructured data sources. However, for the setting in which both structured and unstructured data are accessible, it is not obvious what the best modeling approach is to enhance performance on both data sources simultaneously. Our proposed frameworks allow joint learning on both kinds of data by integrating the paradigms of boosting models and deep neural networks. The first framework, the boosted-feature-vector deep learning network, learns features from the structured data using gradient boosting and combines them with embeddings from unstructured data via a two-branch deep neural network. Secondly, the two-weak-learner boosting framework extends the boosting paradigm to the setting with two input data sources. We present and compare first- and second-order methods of this framework. Our experimental results on both public and real-world datasets show performance gains achieved by the frameworks over selected baselines by magnitudes of 0.1% - 4.7%.
Multi-Layer Attention-Based Explainability via Transformers for Tabular Data
Feb 28, 2023



We propose a graph-oriented attention-based explainability method for tabular data. Tasks involving tabular data have been solved mostly using traditional tree-based machine learning models which have the challenges of feature selection and engineering. With that in mind, we consider a transformer architecture for tabular data, which is amenable to explainability, and present a novel way to leverage self-attention mechanism to provide explanations by taking into account the attention matrices of all layers as a whole. The matrices are mapped to a graph structure where groups of features correspond to nodes and attention values to arcs. By finding the maximum probability paths in the graph, we identify groups of features providing larger contributions to explain the model's predictions. To assess the quality of multi-layer attention-based explanations, we compare them with popular attention-, gradient-, and perturbation-based explanability methods.
Feature Acquisition using Monte Carlo Tree Search
Dec 21, 2022Feature acquisition algorithms address the problem of acquiring informative features while balancing the costs of acquisition to improve the learning performances of ML models. Previous approaches have focused on calculating the expected utility values of features to determine the acquisition sequences. Other approaches formulated the problem as a Markov Decision Process (MDP) and applied reinforcement learning based algorithms. In comparison to previous approaches, we focus on 1) formulating the feature acquisition problem as a MDP and applying Monte Carlo Tree Search, 2) calculating the intermediary rewards for each acquisition step based on model improvements and acquisition costs and 3) simultaneously optimizing model improvement and acquisition costs with multi-objective Monte Carlo Tree Search. With Proximal Policy Optimization and Deep Q-Network algorithms as benchmark, we show the effectiveness of our proposed approach with experimental study.
Pareto Regret Analyses in Multi-objective Multi-armed Bandit
Dec 01, 2022

We study Pareto optimality in multi-objective multi-armed bandit by providing a formulation of adversarial multi-objective multi-armed bandit and properly defining its Pareto regrets that can be generalized to stochastic settings as well. The regrets do not rely on any scalarization functions and reflect Pareto optimality compared to scalarized regrets. We also present new algorithms assuming both with and without prior information of the multi-objective multi-armed bandit setting. The algorithms are shown optimal in adversarial settings and nearly optimal in stochastic settings simultaneously by our established upper bounds and lower bounds on Pareto regrets. Moreover, the lower bound analyses show that the new regrets are consistent with the existing Pareto regret for stochastic settings and extend an adversarial attack mechanism from bandit to the multi-objective one.
A Primal-Dual Algorithm for Hybrid Federated Learning
Oct 14, 2022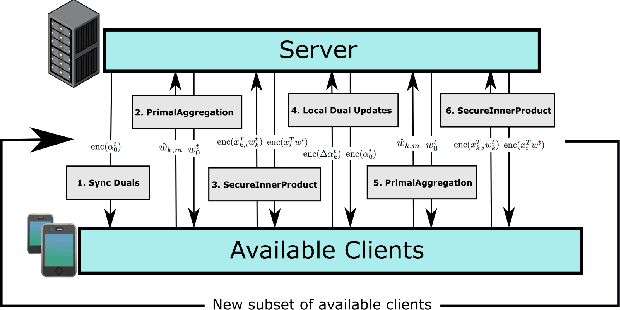

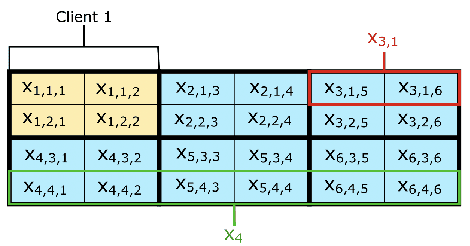
Very few methods for hybrid federated learning, where clients only hold subsets of both features and samples, exist. Yet, this scenario is very important in practical settings. We provide a fast, robust algorithm for hybrid federated learning that hinges on Fenchel Duality. We prove the convergence of the algorithm to the same solution as if the model was trained centrally in a variety of practical regimes. Furthermore, we provide experimental results that demonstrate the performance improvements of the algorithm over a commonly used method in federated learning, FedAvg. We also provide privacy considerations and necessary steps to protect client data.
Divergence Results and Convergence of a Variance Reduced Version of ADAM
Oct 11, 2022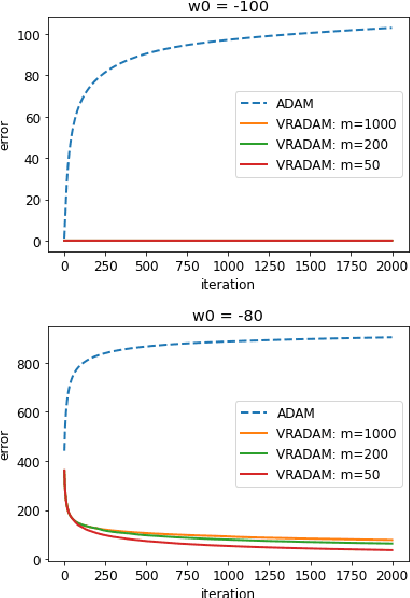
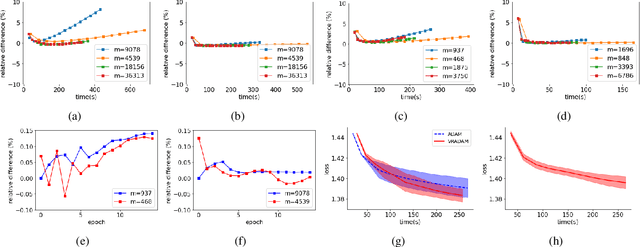
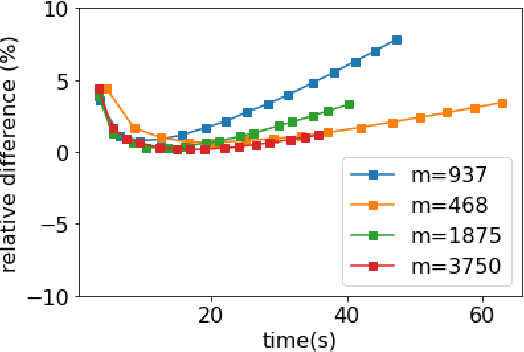
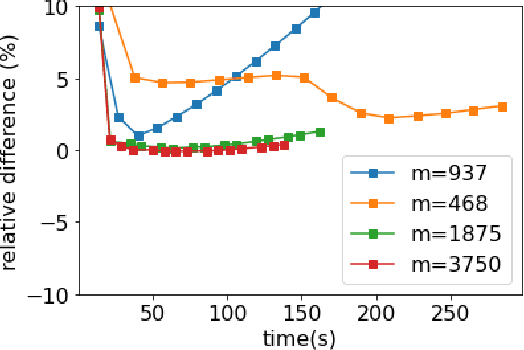
Stochastic optimization algorithms using exponential moving averages of the past gradients, such as ADAM, RMSProp and AdaGrad, have been having great successes in many applications, especially in training deep neural networks. ADAM in particular stands out as efficient and robust. Despite of its outstanding performance, ADAM has been proved to be divergent for some specific problems. We revisit the divergent question and provide divergent examples under stronger conditions such as in expectation or high probability. Under a variance reduction assumption, we show that an ADAM-type algorithm converges, which means that it is the variance of gradients that causes the divergence of original ADAM. To this end, we propose a variance reduced version of ADAM and provide a convergent analysis of the algorithm. Numerical experiments show that the proposed algorithm has as good performance as ADAM. Our work suggests a new direction for fixing the convergence issues.
Large-Scale Multi-Document Summarization with Information Extraction and Compression
May 01, 2022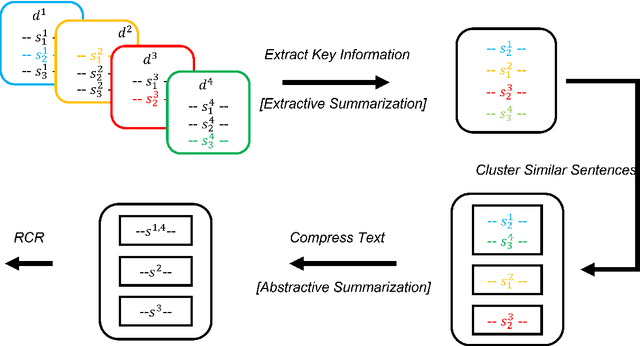
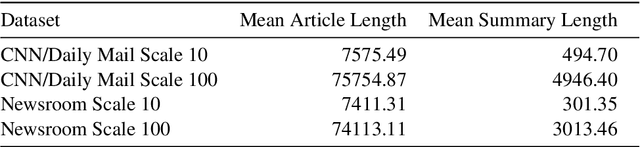
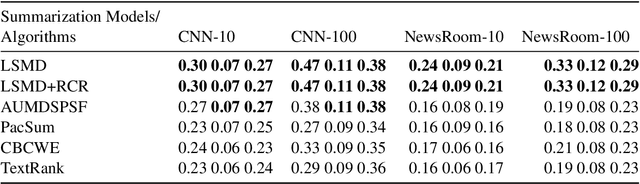
We develop an abstractive summarization framework independent of labeled data for multiple heterogeneous documents. Unlike existing multi-document summarization methods, our framework processes documents telling different stories instead of documents on the same topic. We also enhance an existing sentence fusion method with a uni-directional language model to prioritize fused sentences with higher sentence probability with the goal of increasing readability. Lastly, we construct a total of twelve dataset variations based on CNN/Daily Mail and the NewsRoom datasets, where each document group contains a large and diverse collection of documents to evaluate the performance of our model in comparison with other baseline systems. Our experiments demonstrate that our framework outperforms current state-of-the-art methods in this more generic setting.
Topic Analysis for Text with Side Data
Mar 01, 2022


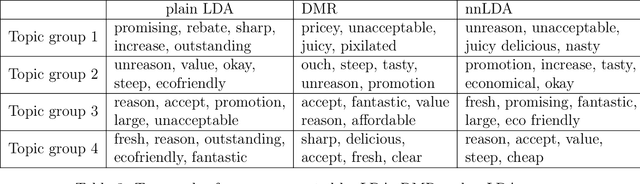
Although latent factor models (e.g., matrix factorization) obtain good performance in predictions, they suffer from several problems including cold-start, non-transparency, and suboptimal recommendations. In this paper, we employ text with side data to tackle these limitations. We introduce a hybrid generative probabilistic model that combines a neural network with a latent topic model, which is a four-level hierarchical Bayesian model. In the model, each document is modeled as a finite mixture over an underlying set of topics and each topic is modeled as an infinite mixture over an underlying set of topic probabilities. Furthermore, each topic probability is modeled as a finite mixture over side data. In the context of text, the neural network provides an overview distribution about side data for the corresponding text, which is the prior distribution in LDA to help perform topic grouping. The approach is evaluated on several different datasets, where the model is shown to outperform standard LDA and Dirichlet-multinomial regression (DMR) in terms of topic grouping, model perplexity, classification and comment generation.