 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Classification with Limited Budget and Maximum Number of Perturbed Samples
Paper and Code
Sep 29, 2020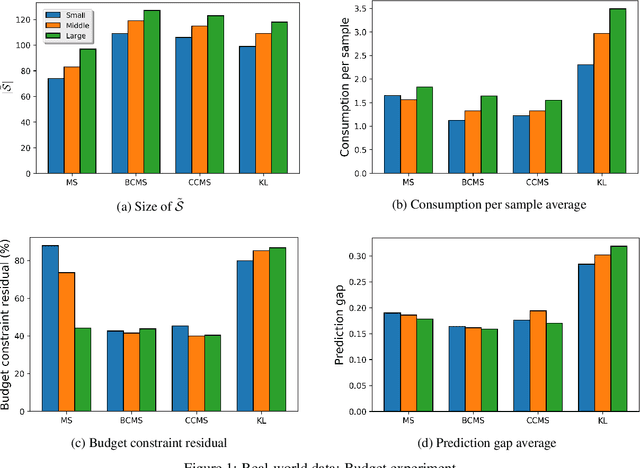

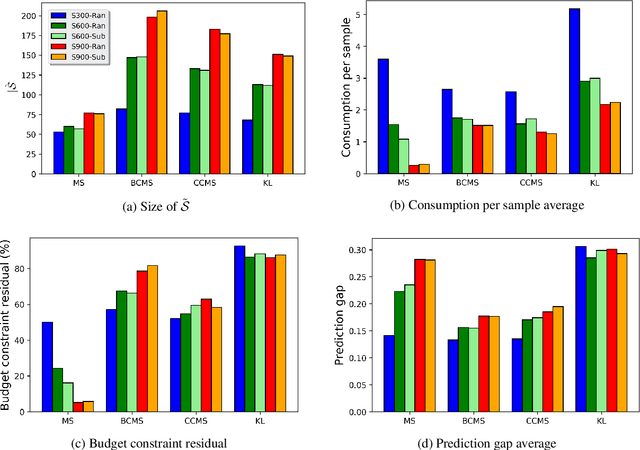
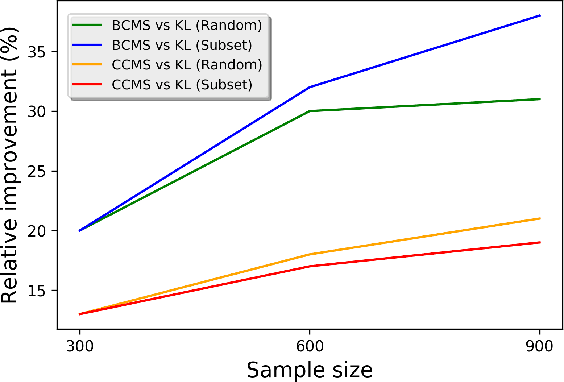
Most recent machine learning research focuses on developing new classifiers for the sake of improving classification accuracy. With many well-performing state-of-the-art classifiers available, there is a growing need for understanding interpretability of a classifier necessitated by practical purposes such as to find the best diet recommendation for a diabetes patient. Inverse classification is a post modeling process to find changes in input features of samples to alter the initially predicted class. It is useful in many business applications to determine how to adjust a sample input data such that the classifier predicts it to be in a desired class. In real world applications, a budget on perturbations of samples corresponding to customers or patients is usually considered, and in this setting, the number of successfully perturbed samples is key to increase benefits. In this study, we propose a new framework to solve inverse classification that maximizes the number of perturbed samples subject to a per-feature-budget limits and favorable classification classes of the perturbed samples. We design algorithms to solve this optimization problem based on gradient methods, stochastic processes, Lagrangian relaxations, and the Gumbel trick. In experiments, we find that our algorithms based on stochastic processes exhibit an excellent performance in different budget settings and they scale well.