 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random Matrix Theory for Deep Networks
Jun 13, 2020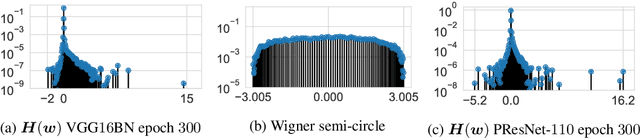



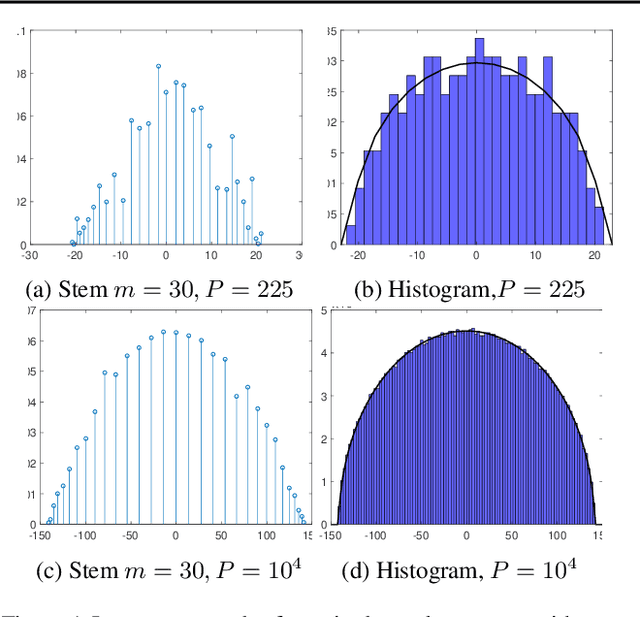
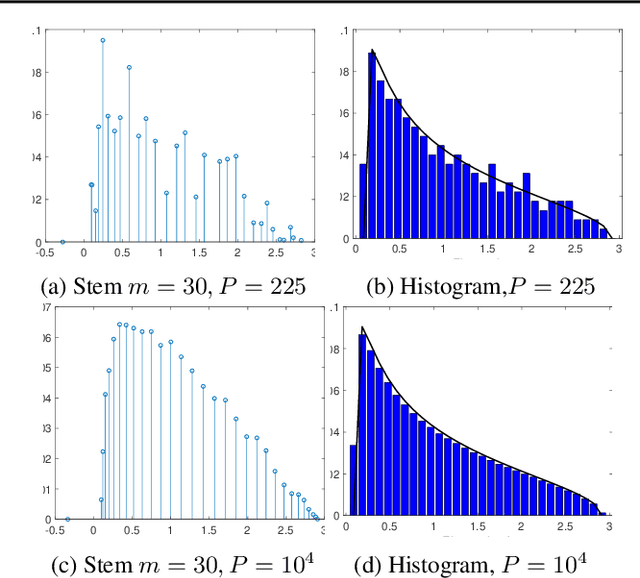
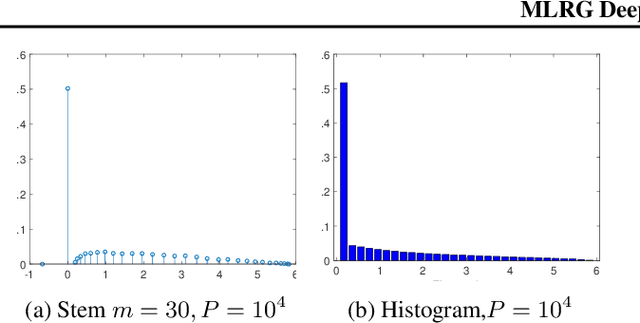
We investigate whether the Wigner semi-circle and Marcenko-Pastur distributions, often used for deep neural network theoretical analysis, match empirically observed spectral densities. We find that even allowing for outliers, the observed spectral shapes strongly deviate from such theoretical predictions. This raises major questions about the usefulness of these models in deep learning. We further show that theoretical results, such as the layered nature of critical points, are strongly dependent on the use of the exact form of these limiting spectral densities. We consider two new classes of matrix ensembles; random Wigner/Wishart ensemble products and percolated Wigner/Wishart ensembles, both of which better match observed spectra. They also give large discrete spectral peaks at the origin, providing a theoretical explanation for the observation that various optima can be connected by one dimensional of low loss values. We further show that, in the case of a random matrix product, the weight of the discrete spectral component at $0$ depends on the ratio of the dimensions of the weight matrices.
Iterate Averaging Helps: An Alternative Perspective in Deep Learning
Mar 02, 2020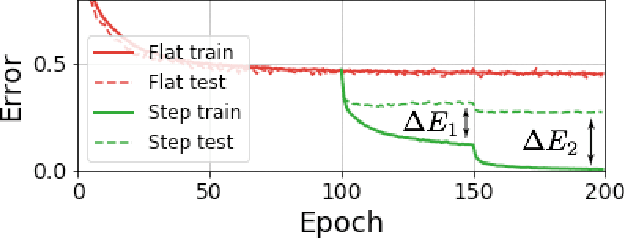

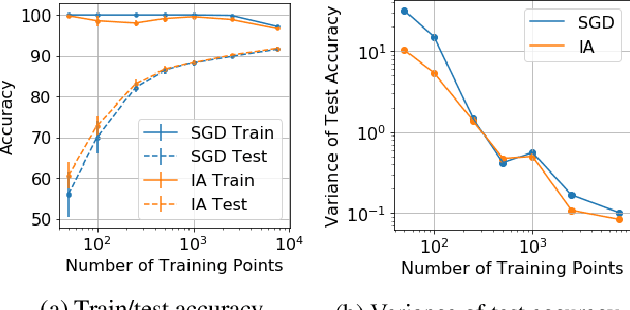
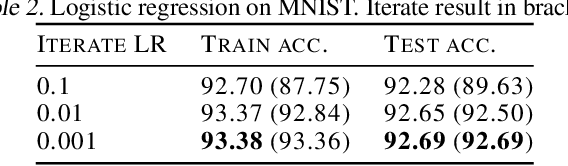
Iterate averaging has a rich history in optimisation, but has only very recently been popularised in deep learning. We investigate its effects in a deep learning context, and argue that previous explanations on its efficacy, which place a high importance on the local geometry (flatness vs sharpness) of final solutions, are not necessarily relevant. We instead argue that the robustness of iterate averaging towards the typically very high estimation noise in deep learning and the various regularisation effects averaging exert, are the key reasons for the performance gain, indeed this effect is made even more prominent due to the over-parameterisation of modern networks. Inspired by this, we propose Gadam, which combines Adam with iterate averaging to address one of key problems of adaptive optimisers that they often generalise worse. Without compromising adaptivity and with minimal additional computational burden, we show that Gadam (and its variant GadamX) achieve a generalisation performance that is consistently superior to tuned SGD and is even on par or better compared to SGD with iterate averaging on various image classification (CIFAR 10/100 and ImageNet 32$\times$32) and language tasks (PTB).
MLRG Deep Curvature
Dec 20, 2019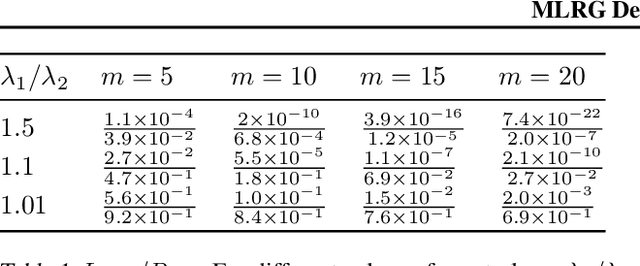
We present MLRG Deep Curvature suite, a PyTorch-based, open-source package for analysis and visualisation of neural network curvature and loss landscape. Despite of providing rich information into properties of neural network and useful for a various designed tasks, curvature information is still not made sufficient use for various reasons, and our method aims to bridge this gap. We present a primer, including its main practical desiderata and common misconceptions, of \textit{Lanczos algorithm}, the theoretical backbone of our package, and present a series of examples based on synthetic toy examples and realistic modern neural networks tested on CIFAR datasets, and show the superiority of our package against existing competing approaches for the similar purposes.
A Maximum Entropy approach to Massive Graph Spectra
Dec 19, 2019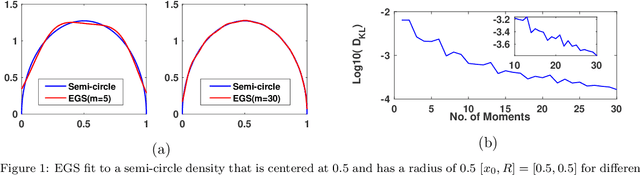

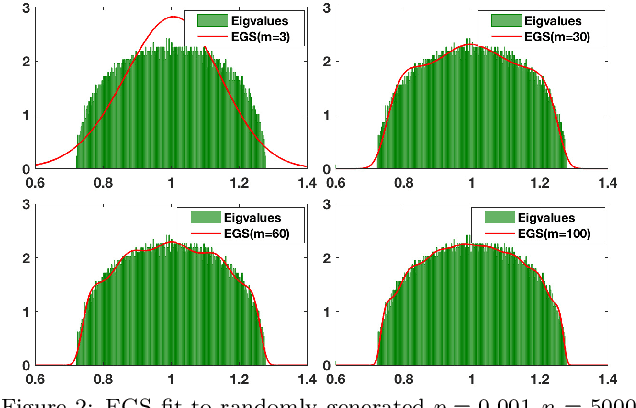
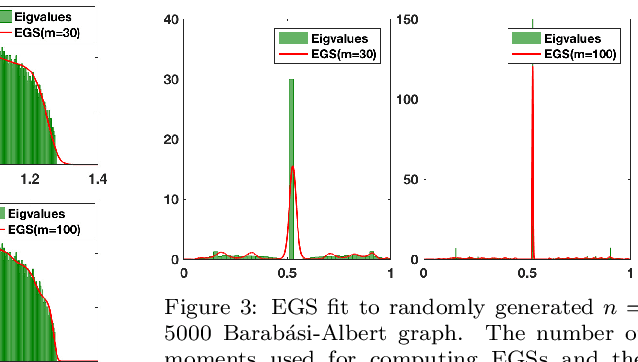
Graph spectral techniques for measuring graph similarity, or for learning the cluster number, require kernel smoothing. The choice of kernel function and bandwidth are typically chosen in an ad-hoc manner and heavily affect the resulting output. We prove that kernel smoothing biases the moments of the spectral density. We propose an information theoretically optimal approach to learn a smooth graph spectral density, which fully respects the moment information. Our method's computational cost is linear in the number of edges, and hence can be applied to large networks, with millions of nodes. We apply our method to the problems to graph similarity and cluster number learning, where we outperform comparable iterative spectral approaches on synthetic and real graphs.
MEMe: An Accurate Maximum Entropy Method for Efficient Approximations in Large-Scale Machine Learning
Jun 03, 2019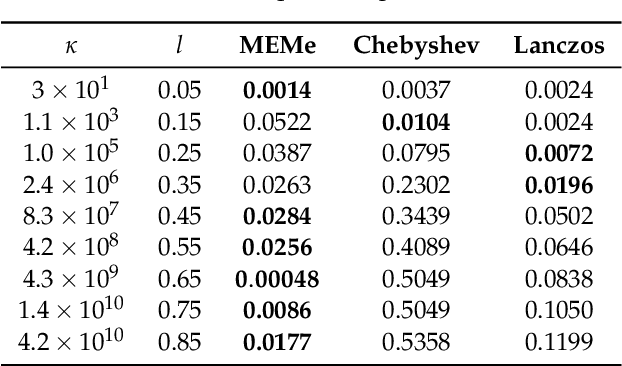
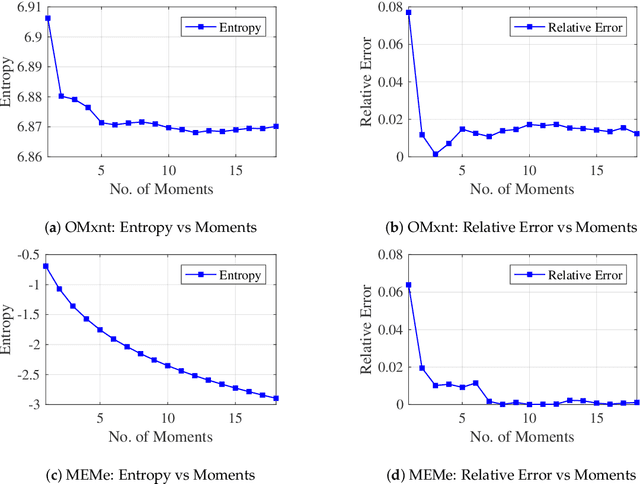
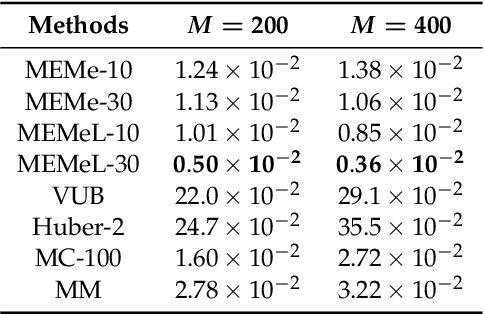
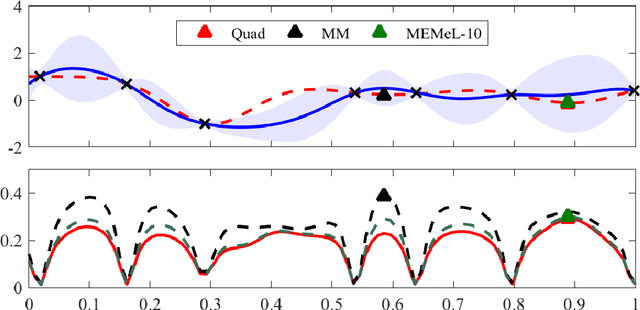
Efficient approximation lies at the heart of large-scale machine learning problems. In this paper, we propose a novel, robust maximum entropy algorithm, which is capable of dealing with hundreds of moments and allows for computationally efficient approximations. We showcase the usefulness of the proposed method, its equivalence to constrained Bayesian variational inference and demonstrate its superiority over existing approaches in two applications, namely, fast log determinant estimation and information-theoretic Bayesian optimisation.
* 18 pages, 3 figures, Published at Entropy 2019: Special Issue Entropy Based Inference and Optimization in Machine Learning
Fast Information-theoretic Bayesian Optimisation
Jun 06, 2018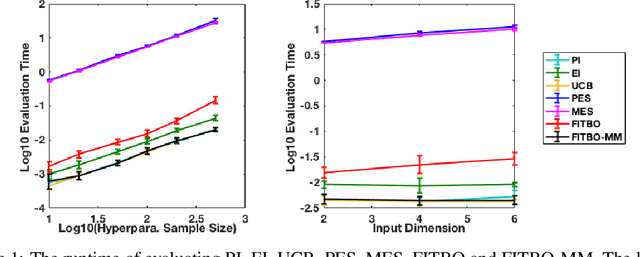
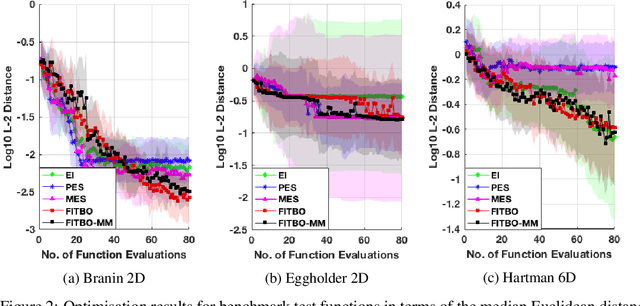
Information-theoretic Bayesian optimisation techniques have demonstrated state-of-the-art performance in tackling important global optimisation problems. However, current information-theoretic approaches require many approximations in implementation, introduce often-prohibitive computational overhead and limit the choice of kernels available to model the objective. We develop a fast information-theoretic Bayesian Optimisation method, FITBO, that avoids the need for sampling the global minimiser, thus significantly reducing computational overhead. Moreover, in comparison with existing approaches, our method faces fewer constraints on kernel choice and enjoys the merits of dealing with the output space. We demonstrate empirically that FITBO inherits the performance associated with information-theoretic Bayesian optimisation, while being even faster than simpler Bayesian optimisation approaches, such as Expected Improvement.
Entropic Spectral Learning in Large Scale Networks
Apr 18, 2018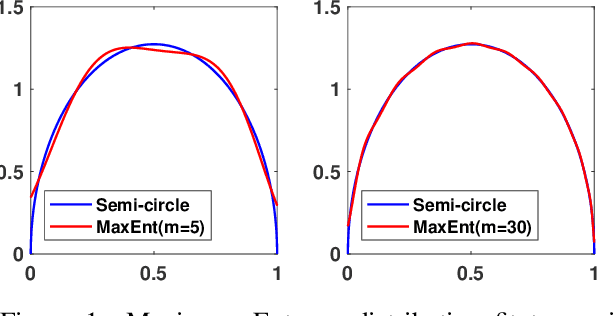

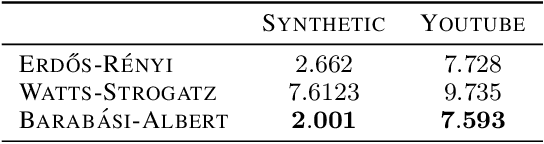
We present a novel algorithm for learning the spectral density of large scale networks using stochastic trace estimation and the method of maximum entropy. The complexity of the algorithm is linear in the number of non-zero elements of the matrix, offering a computational advantage over other algorithms. We apply our algorithm to the problem of community detection in large networks. We show state-of-the-art performance on both synthetic and real datasets.
VBALD - Variational Bayesian Approximation of Log Determinants
Feb 21, 2018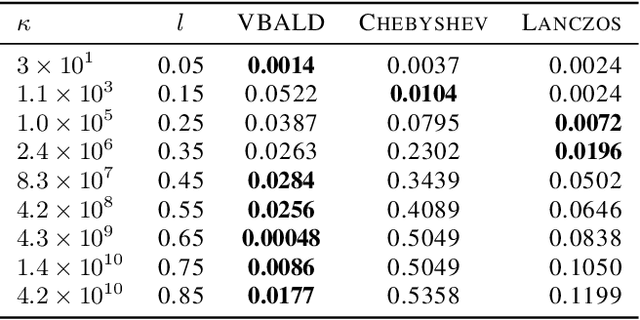
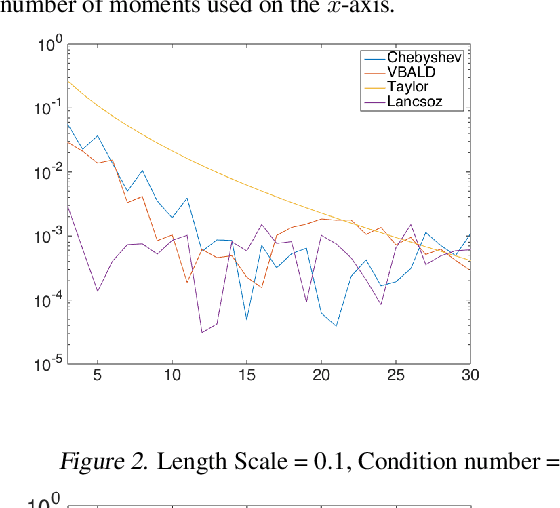
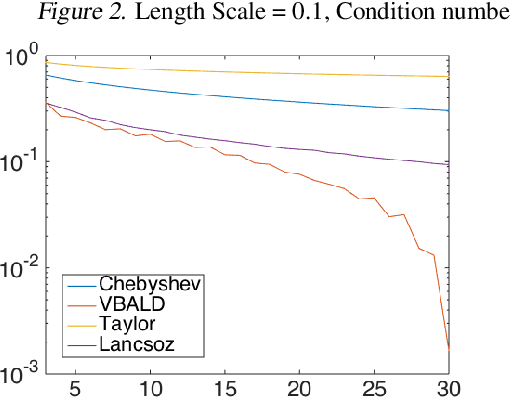

Evaluating the log determinant of a positive definite matrix is ubiquitous in machine learning. Applications thereof range from Gaussian processes, minimum-volume ellipsoids, metric learning, kernel learning, Bayesian neural networks, Determinental Point Processes, Markov random fields to partition functions of discrete graphical models. In order to avoid the canonical, yet prohibitive, Cholesky $\mathcal{O}(n^{3})$ computational cost, we propose a novel approach, with complexity $\mathcal{O}(n^{2})$, based on a constrained variational Bayes algorithm. We compare our method to Taylor, Chebyshev and Lanczos approaches and show state of the art performance on both synthetic and real-world datasets.
Entropic Determinants
Sep 08, 2017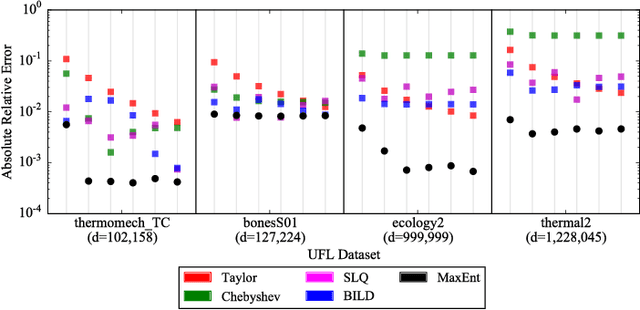
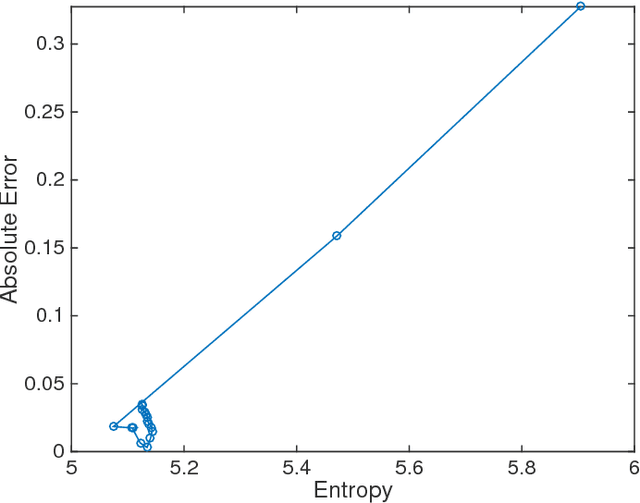
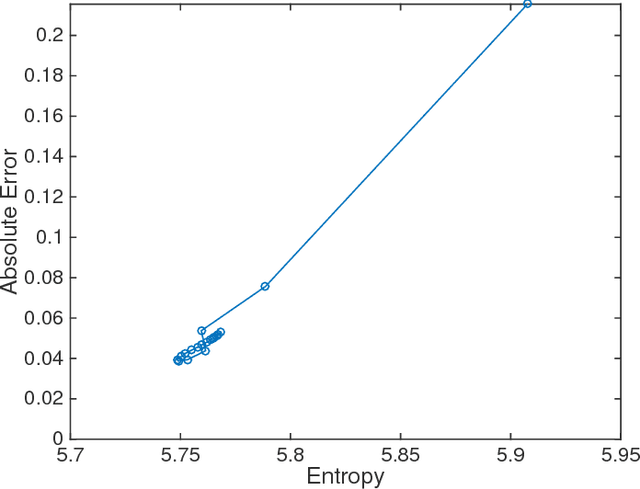
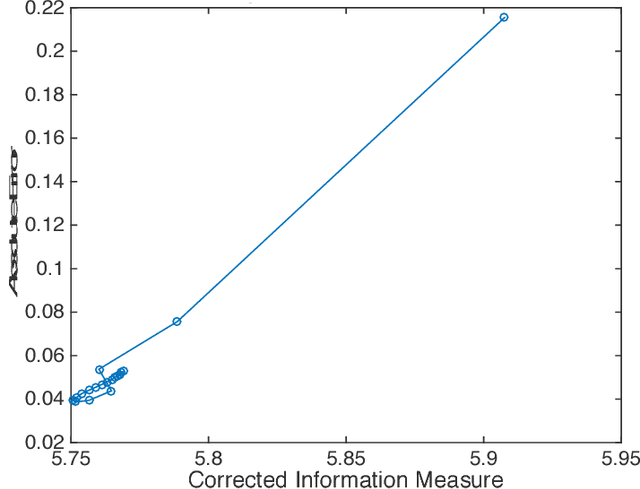
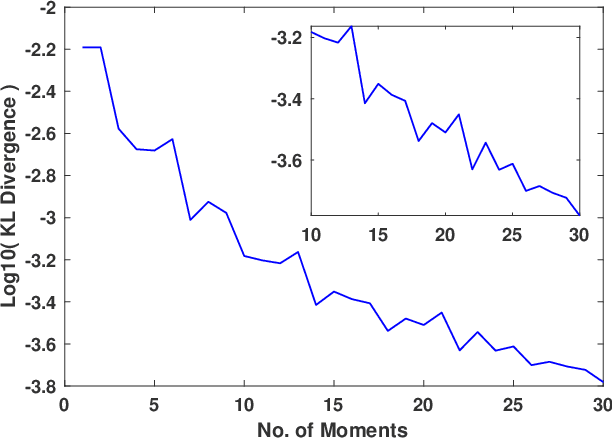
The ability of many powerful machine learning algorithms to deal with large data sets without compromise is often hampered by computationally expensive linear algebra tasks, of which calculating the log determinant is a canonical example. In this paper we demonstrate the optimality of Maximum Entropy methods in approximating such calculations. We prove the equivalence between mean value constraints and sample expectations in the big data limit, that Covariance matrix eigenvalue distributions can be completely defined by moment information and that the reduction of the self entropy of a maximum entropy proposal distribution, achieved by adding more moments reduces the KL divergence between the proposal and true eigenvalue distribution. We empirically verify our results on a variety of SparseSuite matrices and establish best practices.
Entropic Trace Estimates for Log Determinants
Apr 24, 2017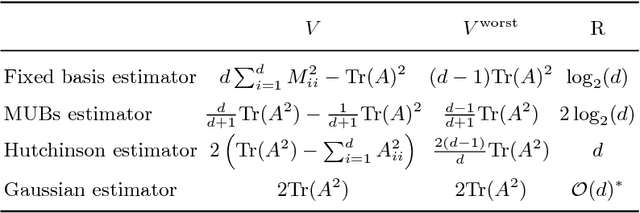
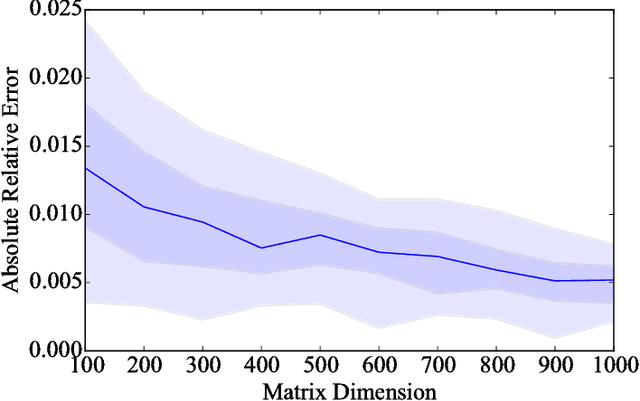
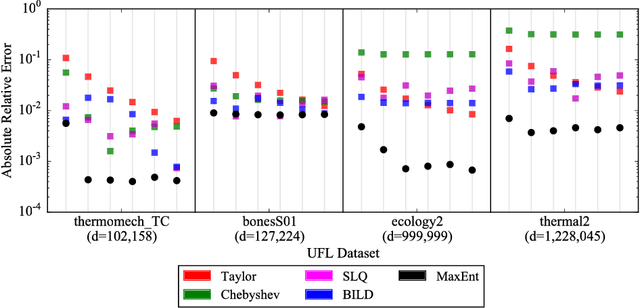
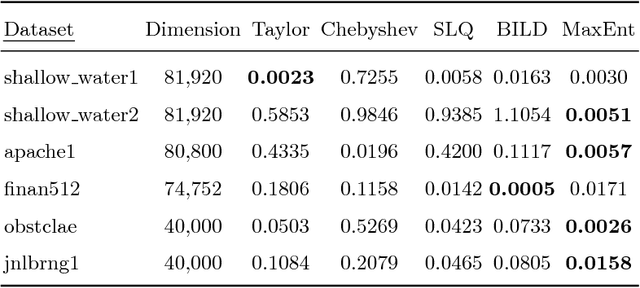
The scalable calculation of matrix determinants has been a bottleneck to the widespread application of many machine learning methods such as determinantal point processes, Gaussian processes, generalised Markov random fields, graph models and many others. In this work, we estimate log determinants under the framework of maximum entropy, given information in the form of moment constraints from stochastic trace estimation. The estimates demonstrate a significant improvement on state-of-the-art alternative methods, as shown on a wide variety of UFL sparse matrices. By taking the example of a general Markov random field, we also demonstrate how this approach can significantly accelerate inference in large-scale learning methods involving the log determinant.