 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNote on Equivalence Between Recurrent Neural Network Time Series Models and Variational Bayesian Models
Jun 18, 2016We observe that the standard log likelihood training objective for a Recurrent Neural Network (RNN) model of time series data is equivalent to a variational Bayesian training objective, given the proper choice of generative and inference models. This perspective may motivate extensions to both RNNs and variational Bayesian models. We propose one such extension, where multiple particles are used for the hidden state of an RNN, allowing a natural representation of uncertainty or multimodality.
Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
Jun 04, 2016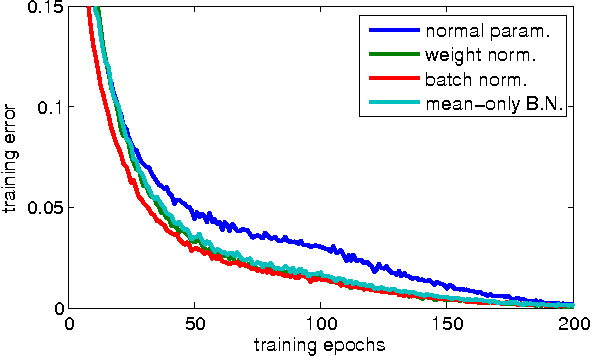
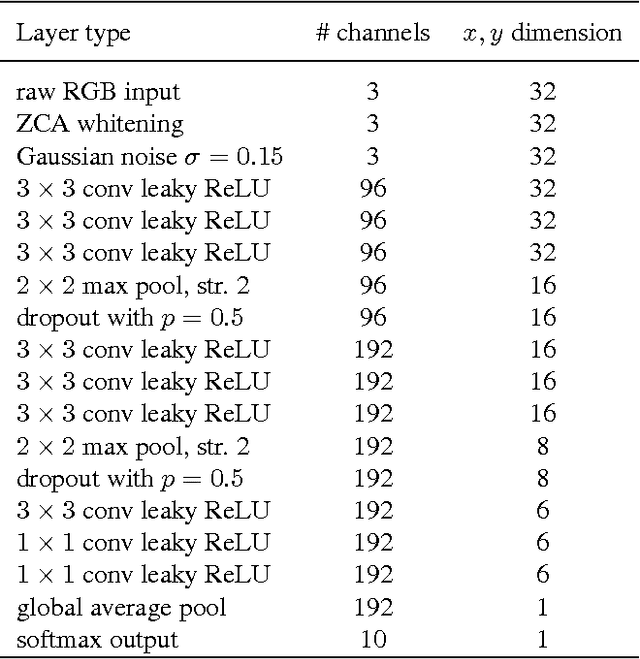

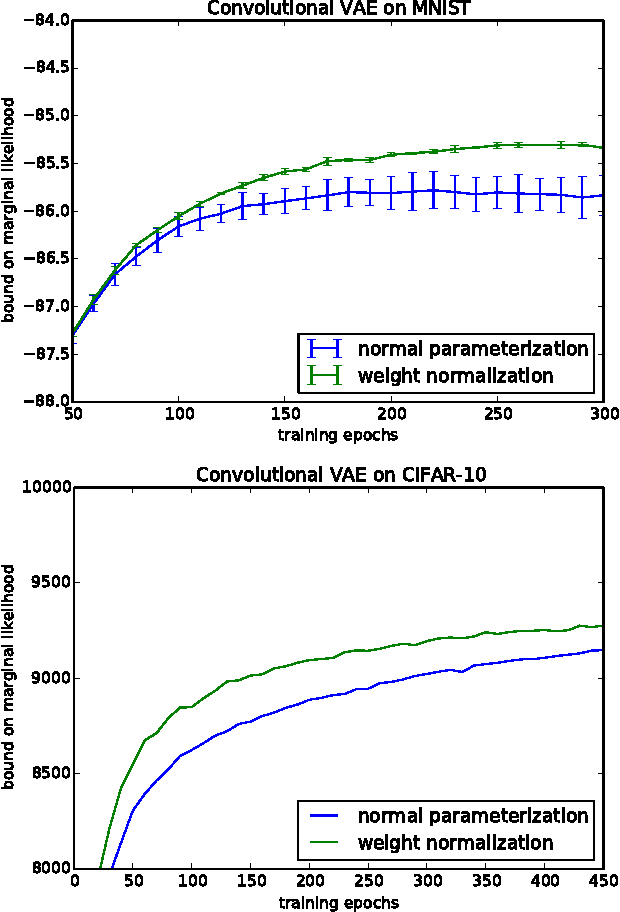
We present weight normalization: a reparameterization of the weight vectors in a neural network that decouples the length of those weight vectors from their direction. By reparameterizing the weights in this way we improve the conditioning of the optimization problem and we speed up convergence of stochastic gradient descent. Our reparameterization is inspired by batch normalization but does not introduce any dependencies between the examples in a minibatch. This means that our method can also be applied successfully to recurrent models such as LSTMs and to noise-sensitive applications such as deep reinforcement learning or generative models, for which batch normalization is less well suited. Although our method is much simpler, it still provides much of the speed-up of full batch normalization. In addition, the computational overhead of our method is lower, permitting more optimization steps to be taken in the same amount of time. We demonstrate the usefulness of our method on applications in supervised image recognition, generative modelling, and deep reinforcement learning.
Variational Dropout and the Local Reparameterization Trick
Dec 20, 2015
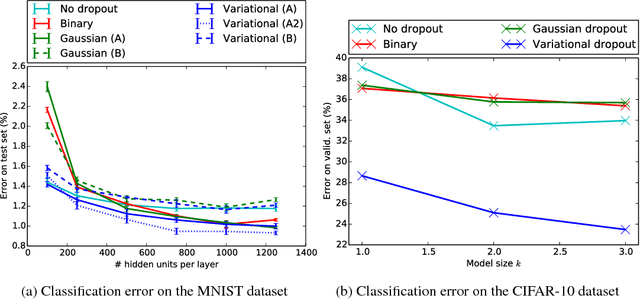
We investigate a local reparameterizaton technique for greatly reducing the variance of stochastic gradients for variational Bayesian inference (SGVB) of a posterior over model parameters, while retaining parallelizability. This local reparameterization translates uncertainty about global parameters into local noise that is independent across datapoints in the minibatch. Such parameterizations can be trivially parallelized and have variance that is inversely proportional to the minibatch size, generally leading to much faster convergence. Additionally, we explore a connection with dropout: Gaussian dropout objectives correspond to SGVB with local reparameterization, a scale-invariant prior and proportionally fixed posterior variance. Our method allows inference of more flexibly parameterized posteriors; specifically, we propose variational dropout, a generalization of Gaussian dropout where the dropout rates are learned, often leading to better models. The method is demonstrated through several experiments.
Markov Chain Monte Carlo and Variational Inference: Bridging the Gap
May 19, 2015

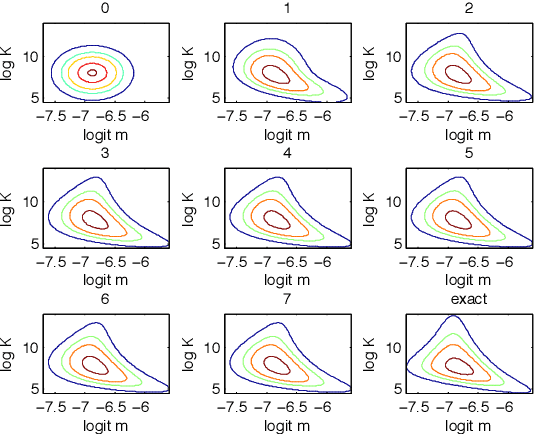
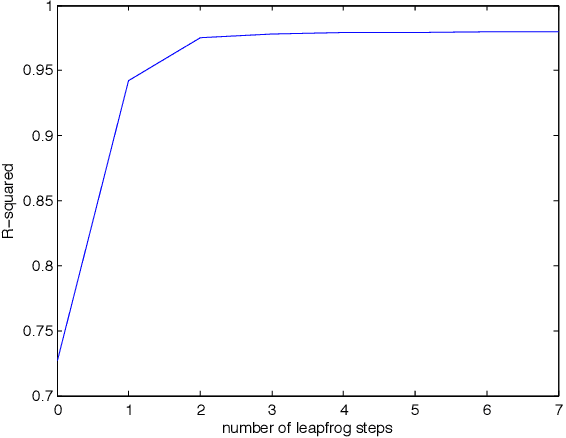
Recent advances in stochastic gradient variational inference have made it possible to perform variational Bayesian inference with posterior approximations containing auxiliary random variables. This enables us to explore a new synthesis of variational inference and Monte Carlo methods where we incorporate one or more steps of MCMC into our variational approximation. By doing so we obtain a rich class of inference algorithms bridging the gap between variational methods and MCMC, and offering the best of both worlds: fast posterior approximation through the maximization of an explicit objective, with the option of trading off additional computation for additional accuracy. We describe the theoretical foundations that make this possible and show some promising first results.
Efficient Gradient-Based Inference through Transformations between Bayes Nets and Neural Nets
Jan 22, 2015
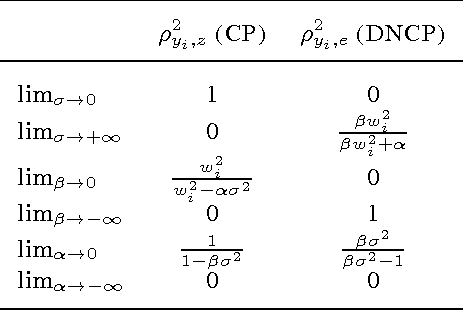
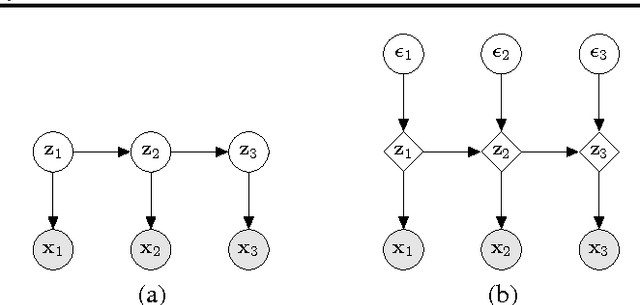
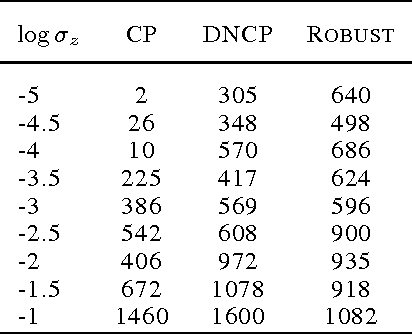
Hierarchical Bayesian networks and neural networks with stochastic hidden units are commonly perceived as two separate types of models. We show that either of these types of models can often be transformed into an instance of the other, by switching between centered and differentiable non-centered parameterizations of the latent variables. The choice of parameterization greatly influences the efficiency of gradient-based posterior inference; we show that they are often complementary to eachother, we clarify when each parameterization is preferred and show how inference can be made robust. In the non-centered form, a simple Monte Carlo estimator of the marginal likelihood can be used for learning the parameters. Theoretical results are supported by experiments.
Semi-Supervised Learning with Deep Generative Models
Oct 31, 2014


The ever-increasing size of modern data sets combined with the difficulty of obtaining label information has made semi-supervised learning one of the problems of significant practical importance in modern data analysis. We revisit the approach to semi-supervised learning with generative models and develop new models that allow for effective generalisation from small labelled data sets to large unlabelled ones. Generative approaches have thus far been either inflexible, inefficient or non-scalable. We show that deep generative models and approximate Bayesian inference exploiting recent advances in variational methods can be used to provide significant improvements, making generative approaches highly competitive for semi-supervised learning.