 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Epidemic Models with Mixtures
Jan 07, 2022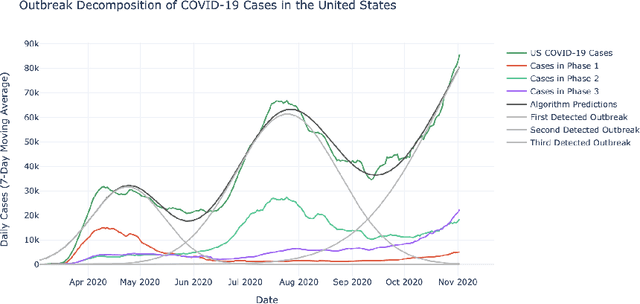
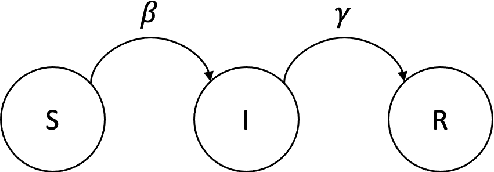
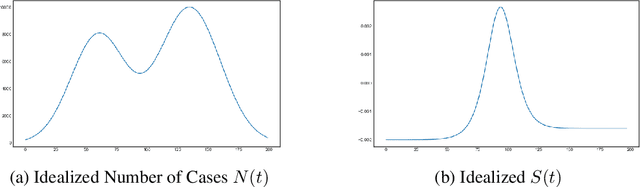
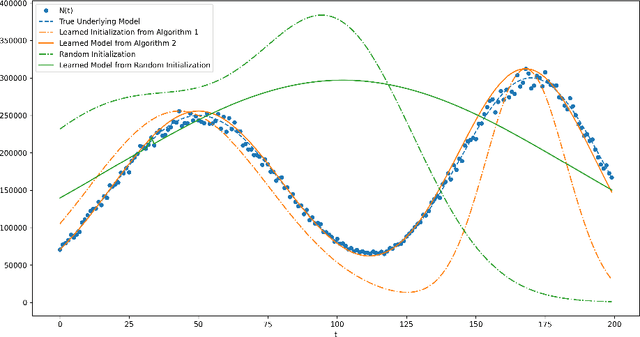
The COVID-19 pandemic has emphasized the need for a robust understanding of epidemic models. Current models of epidemics are classified as either mechanistic or non-mechanistic: mechanistic models make explicit assumptions on the dynamics of disease, whereas non-mechanistic models make assumptions on the form of observed time series. Here, we introduce a simple mixture-based model which bridges the two approaches while retaining benefits of both. The model represents time series of cases and fatalities as a mixture of Gaussian curves, providing a flexible function class to learn from data compared to traditional mechanistic models. Although the model is non-mechanistic, we show that it arises as the natural outcome of a stochastic process based on a networked SIR framework. This allows learned parameters to take on a more meaningful interpretation compared to similar non-mechanistic models, and we validate the interpretations using auxiliary mobility data collected during the COVID-19 pandemic. We provide a simple learning algorithm to identify model parameters and establish theoretical results which show the model can be efficiently learned from data. Empirically, we find the model to have low prediction error. The model is available live at covidpredictions.mit.edu. Ultimately, this allows us to systematically understand the impacts of interventions on COVID-19, which is critical in developing data-driven solutions to controlling epidemics.
Federated Optimization of Smooth Loss Functions
Jan 06, 2022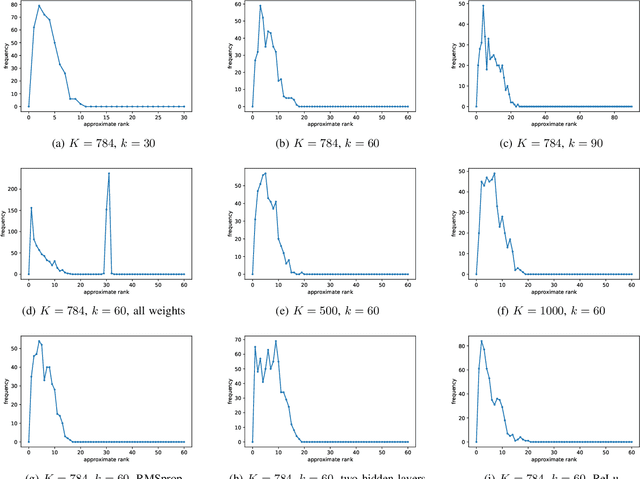
In this work, we study empirical risk minimization (ERM) within a federated learning framework, where a central server minimizes an ERM objective function using training data that is stored across $m$ clients. In this setting, the Federated Averaging (FedAve) algorithm is the staple for determining $\epsilon$-approximate solutions to the ERM problem. Similar to standard optimization algorithms, the convergence analysis of FedAve only relies on smoothness of the loss function in the optimization parameter. However, loss functions are often very smooth in the training data too. To exploit this additional smoothness, we propose the Federated Low Rank Gradient Descent (FedLRGD) algorithm. Since smoothness in data induces an approximate low rank structure on the loss function, our method first performs a few rounds of communication between the server and clients to learn weights that the server can use to approximate clients' gradients. Then, our method solves the ERM problem at the server using inexact gradient descent. To show that FedLRGD can have superior performance to FedAve, we present a notion of federated oracle complexity as a counterpart to canonical oracle complexity. Under some assumptions on the loss function, e.g., strong convexity in parameter, $\eta$-H\"older smoothness in data, etc., we prove that the federated oracle complexity of FedLRGD scales like $\phi m(p/\epsilon)^{\Theta(d/\eta)}$ and that of FedAve scales like $\phi m(p/\epsilon)^{3/4}$ (neglecting sub-dominant factors), where $\phi\gg 1$ is a "communication-to-computation ratio," $p$ is the parameter dimension, and $d$ is the data dimension. Then, we show that when $d$ is small and the loss function is sufficiently smooth in the data, FedLRGD beats FedAve in federated oracle complexity. Finally, in the course of analyzing FedLRGD, we also establish a result on low rank approximation of latent variable models.
CausalSim: Toward a Causal Data-Driven Simulator for Network Protocols
Jan 05, 2022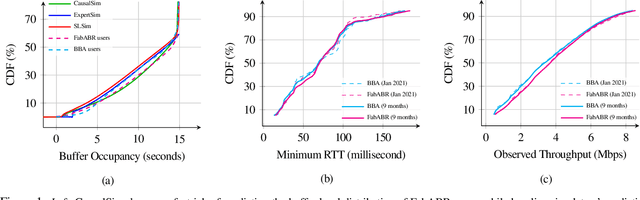
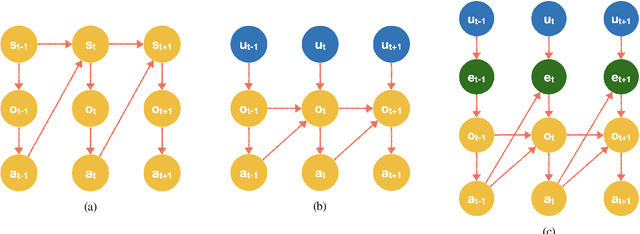
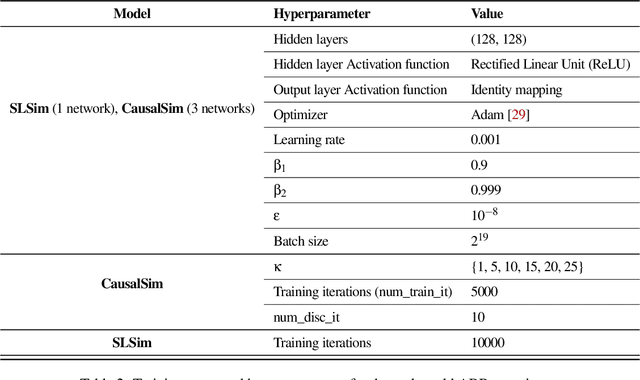
Evaluating the real-world performance of network protocols is challenging. Randomized control trials (RCT) are expensive and inaccessible to most researchers, while expert-designed simulators fail to capture complex behaviors in real networks. We present CausalSim, a data-driven simulator for network protocols that addresses this challenge. Learning network behavior from observational data is complicated due to the bias introduced by the protocols used during data collection. CausalSim uses traces from an initial RCT under a set of protocols to learn a causal network model, effectively removing the biases present in the data. Using this model, CausalSim can then simulate any protocol over the same traces (i.e., for counterfactual predictions). Key to CausalSim is the novel use of adversarial neural network training that exploits distributional invariances that are present due to the training data coming from an RCT. Our extensive evaluation of CausalSim on both real and synthetic datasets and two use cases, including more than nine months of real data from the Puffer video streaming system, shows that it provides accurate counterfactual predictions, reducing prediction error by 44% and 53% on average compared to expert-designed and standard supervised learning baselines.
Time varying regression with hidden linear dynamics
Dec 29, 2021We revisit a model for time-varying linear regression that assumes the unknown parameters evolve according to a linear dynamical system. Counterintuitively, we show that when the underlying dynamics are stable the parameters of this model can be estimated from data by combining just two ordinary least squares estimates. We offer a finite sample guarantee on the estimation error of our method and discuss certain advantages it has over Expectation-Maximization (EM), which is the main approach proposed by prior work.
A Computationally Efficient Method for Learning Exponential Family Distributions
Oct 28, 2021
We consider the question of learning the natural parameters of a $k$ parameter minimal exponential family from i.i.d. samples in a computationally and statistically efficient manner. We focus on the setting where the support as well as the natural parameters are appropriately bounded. While the traditional maximum likelihood estimator for this class of exponential family is consistent, asymptotically normal, and asymptotically efficient, evaluating it is computationally hard. In this work, we propose a computationally efficient estimator that is consistent as well as asymptotically normal under mild conditions. We provide finite sample guarantees to achieve an ($\ell_2$) error of $\alpha$ in the parameter estimation with sample complexity $O(\mathrm{poly}(k/\alpha))$ and computational complexity ${O}(\mathrm{poly}(k/\alpha))$. To establish these results, we show that, at the population level, our method can be viewed as the maximum likelihood estimation of a re-parameterized distribution belonging to the same class of exponential family.
Causal Matrix Completion
Sep 30, 2021
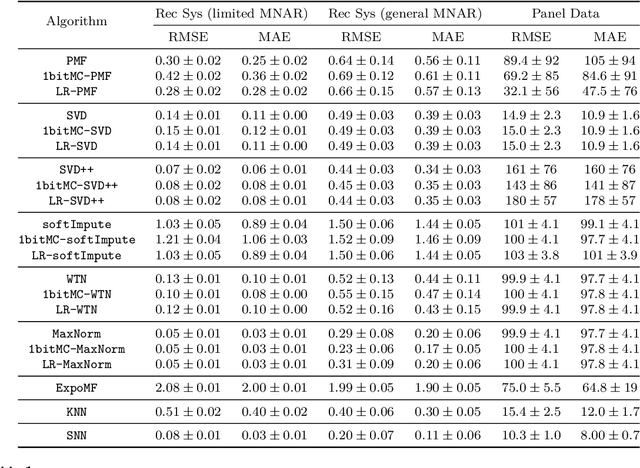
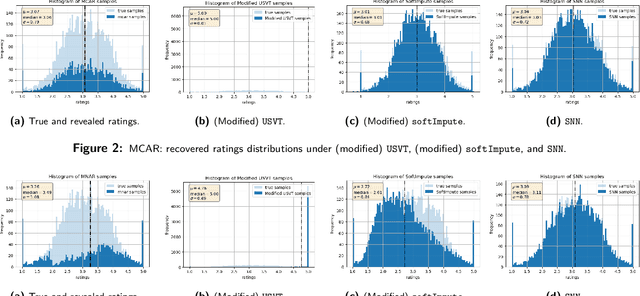
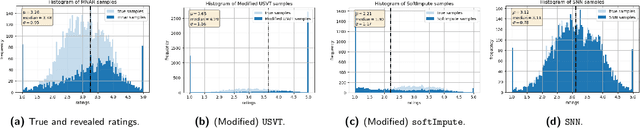
Matrix completion is the study of recovering an underlying matrix from a sparse subset of noisy observations. Traditionally, it is assumed that the entries of the matrix are "missing completely at random" (MCAR), i.e., each entry is revealed at random, independent of everything else, with uniform probability. This is likely unrealistic due to the presence of "latent confounders", i.e., unobserved factors that determine both the entries of the underlying matrix and the missingness pattern in the observed matrix. For example, in the context of movie recommender systems -- a canonical application for matrix completion -- a user who vehemently dislikes horror films is unlikely to ever watch horror films. In general, these confounders yield "missing not at random" (MNAR) data, which can severely impact any inference procedure that does not correct for this bias. We develop a formal causal model for matrix completion through the language of potential outcomes, and provide novel identification arguments for a variety of causal estimands of interest. We design a procedure, which we call "synthetic nearest neighbors" (SNN), to estimate these causal estimands. We prove finite-sample consistency and asymptotic normality of our estimator. Our analysis also leads to new theoretical results for the matrix completion literature. In particular, we establish entry-wise, i.e., max-norm, finite-sample consistency and asymptotic normality results for matrix completion with MNAR data. As a special case, this also provides entry-wise bounds for matrix completion with MCAR data. Across simulated and real data, we demonstrate the efficacy of our proposed estimator.
PerSim: Data-Efficient Offline Reinforcement Learning with Heterogeneous Agents via Personalized Simulators
Mar 17, 2021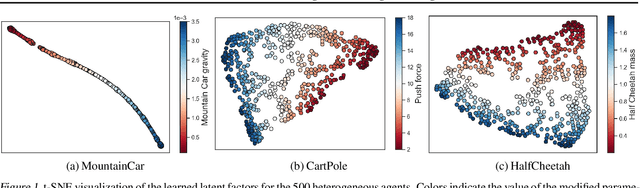

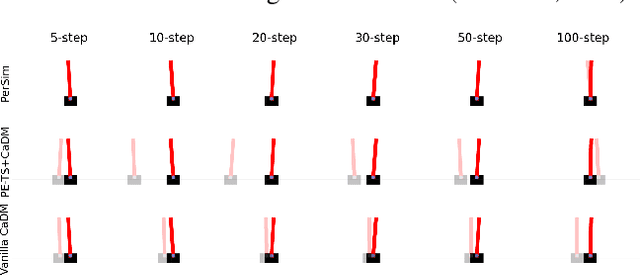
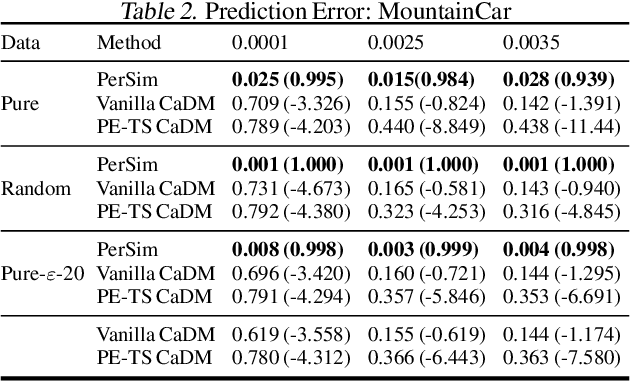
We consider offline reinforcement learning (RL) with heterogeneous agents under severe data scarcity, i.e., we only observe a single historical trajectory for every agent under an unknown, potentially sub-optimal policy. We find that the performance of state-of-the-art offline and model-based RL methods degrade significantly given such limited data availability, even for commonly perceived "solved" benchmark settings such as "MountainCar" and "CartPole". To address this challenge, we propose a model-based offline RL approach, called PerSim, where we first learn a personalized simulator for each agent by collectively using the historical trajectories across all agents prior to learning a policy. We do so by positing that the transition dynamics across agents can be represented as a latent function of latent factors associated with agents, states, and actions; subsequently, we theoretically establish that this function is well-approximated by a "low-rank" decomposition of separable agent, state, and action latent functions. This representation suggests a simple, regularized neural network architecture to effectively learn the transition dynamics per agent, even with scarce, offline data.We perform extensive experiments across several benchmark environments and RL methods. The consistent improvement of our approach, measured in terms of state dynamics prediction and eventual reward, confirms the efficacy of our framework in leveraging limited historical data to simultaneously learn personalized policies across agents.
Approximating the Log-Partition Function
Feb 19, 2021
Variational approximation, such as mean-field (MF) and tree-reweighted (TRW), provide a computationally efficient approximation of the log-partition function for a generic graphical model. TRW provably provides an upper bound, but the approximation ratio is generally not quantified. As the primary contribution of this work, we provide an approach to quantify the approximation ratio through the property of the underlying graph structure. Specifically, we argue that (a variant of) TRW produces an estimate that is within factor $\frac{1}{\sqrt{\kappa(G)}}$ of the true log-partition function for any discrete pairwise graphical model over graph $G$, where $\kappa(G) \in (0,1]$ captures how far $G$ is from tree structure with $\kappa(G) = 1$ for trees and $2/N$ for the complete graph over $N$ vertices. As a consequence, the approximation ratio is $1$ for trees, $\sqrt{(d+1)/2}$ for any graph with maximum average degree $d$, and $\stackrel{\beta\to\infty}{\approx} 1+1/(2\beta)$ for graphs with girth (shortest cycle) at least $\beta \log N$. In general, $\kappa(G)$ is the solution of a max-min problem associated with $G$ that can be evaluated in polynomial time for any graph. Using samples from the uniform distribution over the spanning trees of G, we provide a near linear-time variant that achieves an approximation ratio equal to the inverse of square-root of minimal (across edges) effective resistance of the graph. We connect our results to the graph partition-based approximation method and thus provide a unified perspective. Keywords: variational inference, log-partition function, spanning tree polytope, minimum effective resistance, min-max spanning tree, local inference
Regret, stability, and fairness in matching markets with bandit learners
Feb 11, 2021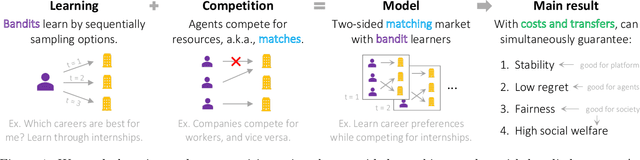
We consider the two-sided matching market with bandit learners. In the standard matching problem, users and providers are matched to ensure incentive compatibility via the notion of stability. However, contrary to the core assumption of the matching problem, users and providers do not know their true preferences a priori and must learn them. To address this assumption, recent works propose to blend the matching and multi-armed bandit problems. They establish that it is possible to assign matchings that are stable (i.e., incentive-compatible) at every time step while also allowing agents to learn enough so that the system converges to matchings that are stable under the agents' true preferences. However, while some agents may incur low regret under these matchings, others can incur high regret -- specifically, $\Omega(T)$ optimal regret where $T$ is the time horizon. In this work, we incorporate costs and transfers in the two-sided matching market with bandit learners in order to faithfully model competition between agents. We prove that, under our framework, it is possible to simultaneously guarantee four desiderata: (1) incentive compatibility, i.e., stability, (2) low regret, i.e., $O(\log(T))$ optimal regret, (3) fairness in the distribution of regret among agents, and (4) high social welfare.
Gradient-Based Empirical Risk Minimization using Local Polynomial Regression
Nov 04, 2020
In this paper, we consider the problem of empirical risk minimization (ERM) of smooth, strongly convex loss functions using iterative gradient-based methods. A major goal of this literature has been to compare different algorithms, such as gradient descent (GD) or stochastic gradient descent (SGD), by analyzing their rates of convergence to $\epsilon$-approximate solutions. For example, the oracle complexity of GD is $O(n\log(\epsilon^{-1}))$, where $n$ is the number of training samples. When $n$ is large, this can be expensive in practice, and SGD is preferred due to its oracle complexity of $O(\epsilon^{-1})$. Such standard analyses only utilize the smoothness of the loss function in the parameter being optimized. In contrast, we demonstrate that when the loss function is smooth in the data, we can learn the oracle at every iteration and beat the oracle complexities of both GD and SGD in important regimes. Specifically, at every iteration, our proposed algorithm performs local polynomial regression to learn the gradient of the loss function, and then estimates the true gradient of the ERM objective function. We establish that the oracle complexity of our algorithm scales like $\tilde{O}((p \epsilon^{-1})^{d/(2\eta)})$ (neglecting sub-dominant factors), where $d$ and $p$ are the data and parameter space dimensions, respectively, and the gradient of the loss function belongs to a $\eta$-H\"{o}lder class with respect to the data. Our proof extends the analysis of local polynomial regression in non-parametric statistics to provide interpolation guarantees in multivariate settings, and also exploits tools from the inexact GD literature. Unlike GD and SGD, the complexity of our method depends on $d$ and $p$. However, when $d$ is small and the loss function exhibits modest smoothness in the data, our algorithm beats GD and SGD in oracle complexity for a very broad range of $p$ and $\epsilon$.