 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinBalance: A Multi-Document Accounting Reconciliation Benchmark
Jun 14, 2026Existing financial-NLP benchmarks mostly evaluate prepared artifacts such as filings, tables, or extracted values. Real accounting begins earlier: source documents must be reconciled into cited journal entries, aggregated into a balance sheet, and checked for contradictions. We introduce FinBalance, a multi-document accounting reconciliation benchmark built from source-document bundles across eight industries, three period types, and five difficulty levels. Human-authored business scenarios, accounting policies, tax/FX treatments, document schemas, distractors, and inconsistency templates are composed by a deterministic generator whose ledger produces journal entries,balance sheets, and 23 inconsistency-code labels. On a 710-record evaluation split, six contemporary LLMs reach at most 46% exact final-balance-sheet accuracy. Four models show a 26-41 pp gap between BS_exact, the model's reported balance sheet, and BS_recon, the balance sheet obtained by replaying its entries through our ledger. Models often recover numerically plausible entries but fail to bind them to supporting documents and aggregate them consistently. Citation-pressure prompting barely changes document-linking errors, while ledger-feedback ablations substantially improve reported balance sheets and expose inconsistency-detection trade-offs. Expert finance reviewers validate the benchmark design and labels.
Semantic Anchoring in Agentic Memory: Leveraging Linguistic Structures for Persistent Conversational Context
Aug 18, 2025Large Language Models (LLMs) have demonstrated impressive fluency and task competence in conversational settings. However, their effectiveness in multi-session and long-term interactions is hindered by limited memory persistence. Typical retrieval-augmented generation (RAG) systems store dialogue history as dense vectors, which capture semantic similarity but neglect finer linguistic structures such as syntactic dependencies, discourse relations, and coreference links. We propose Semantic Anchoring, a hybrid agentic memory architecture that enriches vector-based storage with explicit linguistic cues to improve recall of nuanced, context-rich exchanges. Our approach combines dependency parsing, discourse relation tagging, and coreference resolution to create structured memory entries. Experiments on adapted long-term dialogue datasets show that semantic anchoring improves factual recall and discourse coherence by up to 18% over strong RAG baselines. We further conduct ablation studies, human evaluations, and error analysis to assess robustness and interpretability.
Masked Image Modeling Advances 3D Medical Image Analysis
Apr 25, 2022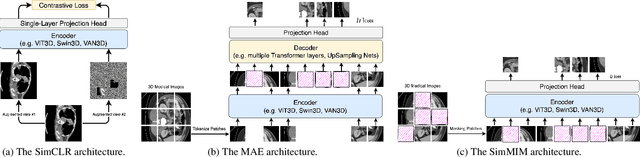
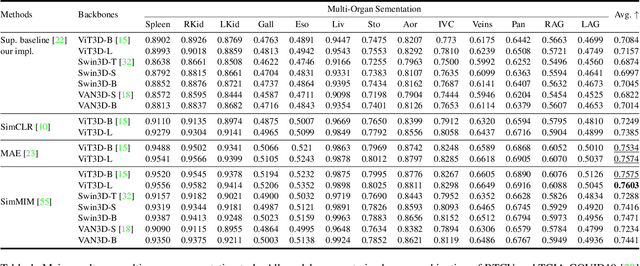
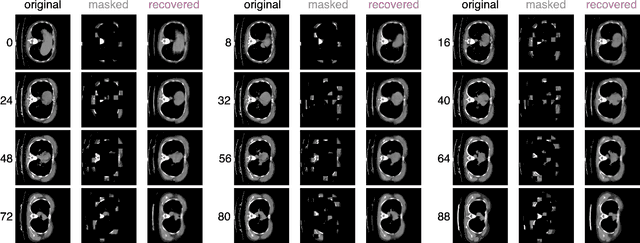
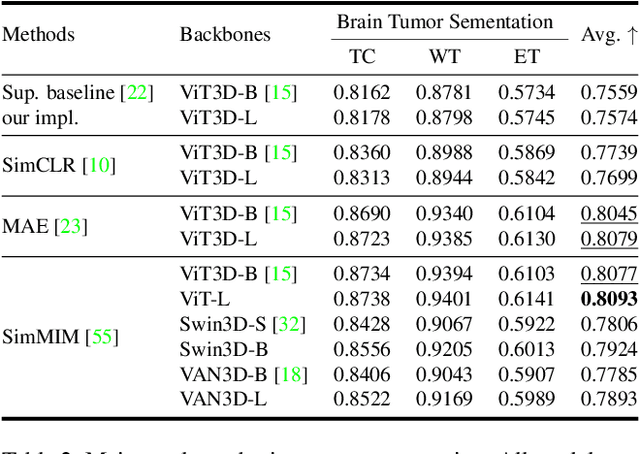
Recently, masked image modeling (MIM) has gained considerable attention due to its capacity to learn from vast amounts of unlabeled data and has been demonstrated to be effective on a wide variety of vision tasks involving natural images. Meanwhile, the potential of self-supervised learning in modeling 3D medical images is anticipated to be immense due to the high quantities of unlabeled images, and the expense and difficulty of quality labels. However, MIM's applicability to medical images remains uncertain. In this paper, we demonstrate that masked image modeling approaches can also advance 3D medical images analysis in addition to natural images. We study how masked image modeling strategies leverage performance from the viewpoints of 3D medical image segmentation as a representative downstream task: i) when compared to naive contrastive learning, masked image modeling approaches accelerate the convergence of supervised training even faster (1.40$\times$) and ultimately produce a higher dice score; ii) predicting raw voxel values with a high masking ratio and a relatively smaller patch size is non-trivial self-supervised pretext-task for medical images modeling; iii) a lightweight decoder or projection head design for reconstruction is powerful for masked image modeling on 3D medical images which speeds up training and reduce cost; iv) finally, we also investigate the effectiveness of MIM methods under different practical scenarios where different image resolutions and labeled data ratios are applied.
An Empirical Study on the Robustness of NAS based Architectures
Jul 16, 2020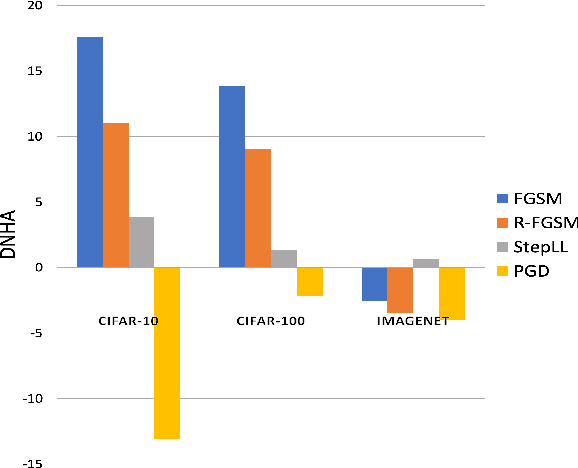
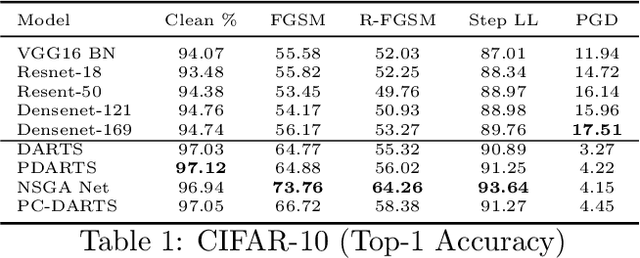
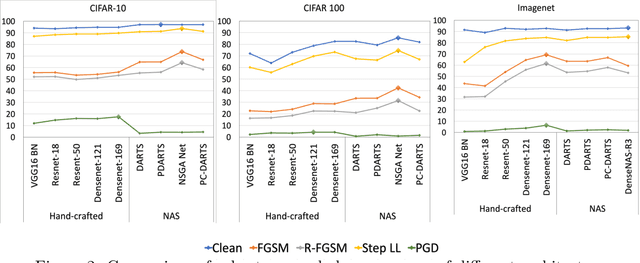
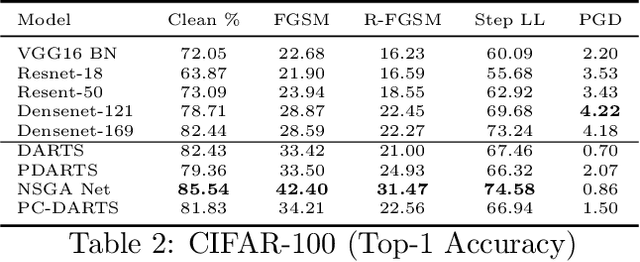
Most existing methods for Neural Architecture Search (NAS) focus on achieving state-of-the-art (SOTA) performance on standard datasets and do not explicitly search for adversarially robust models. In this work, we study the adversarial robustness of existing NAS architectures, comparing it with state-of-the-art handcrafted architectures, and provide reasons for why it is essential. We draw some key conclusions on the capacity of current NAS methods to tackle adversarial attacks through experiments on datasets of different sizes.