 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Manhattan Room Layout Reconstruction from a Single 360 Image
Oct 24, 2019

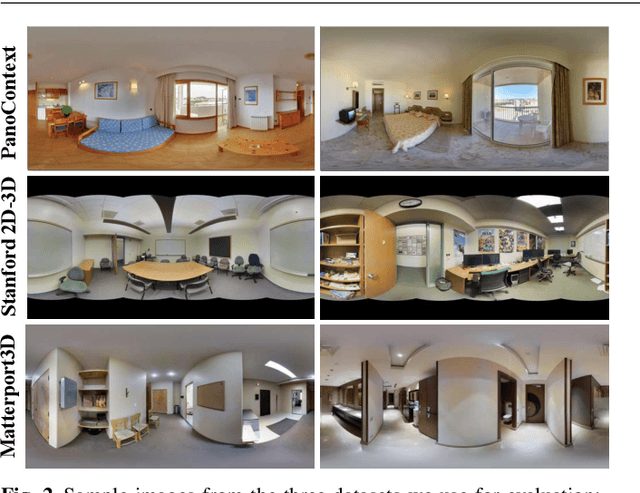

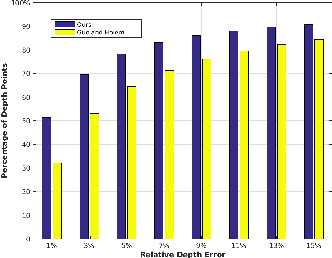
Recent approaches for predicting layouts from 360 panoramas produce excellent results. These approaches build on a common framework consisting of three steps: a pre-processing step based on edge-based alignment, prediction of layout elements, and a post-processing step by fitting a 3D layout to the layout elements. Until now, it has been difficult to compare the methods due to multiple different design decisions, such as the encoding network (e.g. SegNet or ResNet), type of elements predicted (e.g. corners, wall/floor boundaries, or semantic segmentation), or method of fitting the 3D layout. To address this challenge, we summarize and describe the common framework, the variants, and the impact of the design decisions. For a complete evaluation, we also propose extended annotations for the Matterport3D dataset, and introduce two depth-based evaluation metrics.
ViCo: Word Embeddings from Visual Co-occurrences
Aug 22, 2019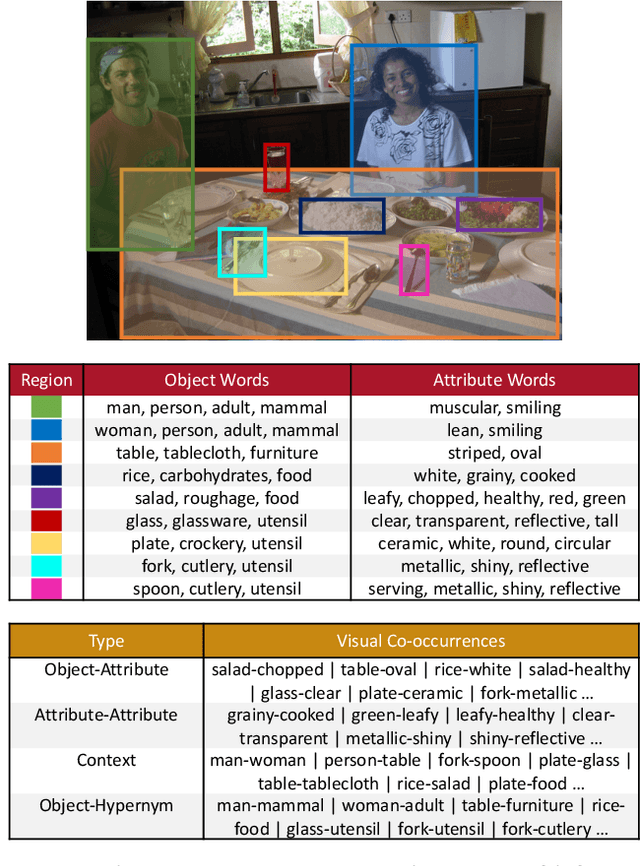
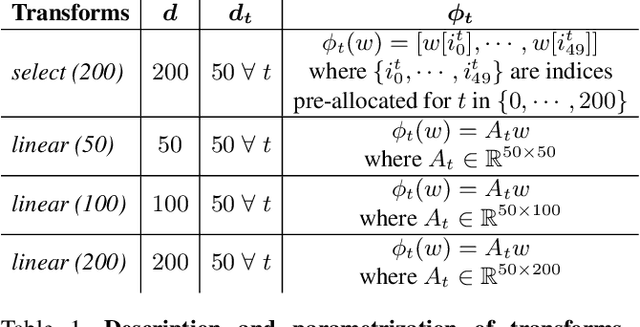
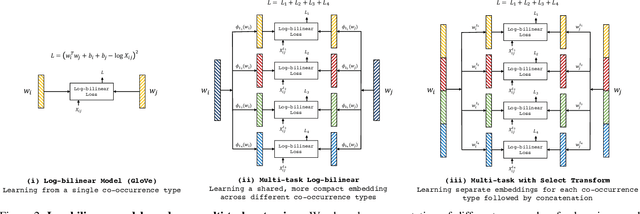
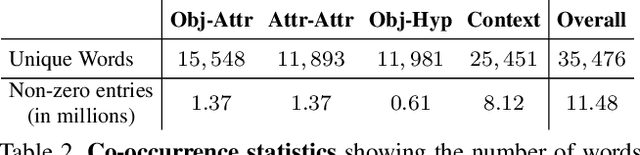
We propose to learn word embeddings from visual co-occurrences. Two words co-occur visually if both words apply to the same image or image region. Specifically, we extract four types of visual co-occurrences between object and attribute words from large-scale, textually-annotated visual databases like VisualGenome and ImageNet. We then train a multi-task log-bilinear model that compactly encodes word "meanings" represented by each co-occurrence type into a single visual word-vector. Through unsupervised clustering, supervised partitioning, and a zero-shot-like generalization analysis we show that our word embeddings complement text-only embeddings like GloVe by better representing similarities and differences between visual concepts that are difficult to obtain from text corpora alone. We further evaluate our embeddings on five downstream applications, four of which are vision-language tasks. Augmenting GloVe with our embeddings yields gains on all tasks. We also find that random embeddings perform comparably to learned embeddings on all supervised vision-language tasks, contrary to conventional wisdom.
Anchor Tasks: Inexpensive, Shared, and Aligned Tasks for Domain Adaptation
Aug 16, 2019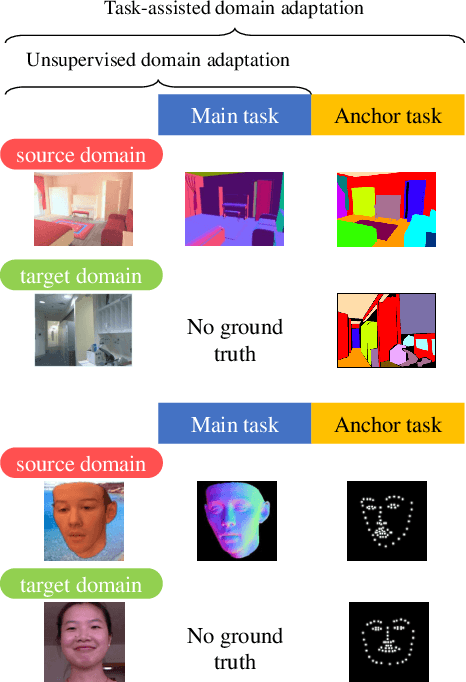
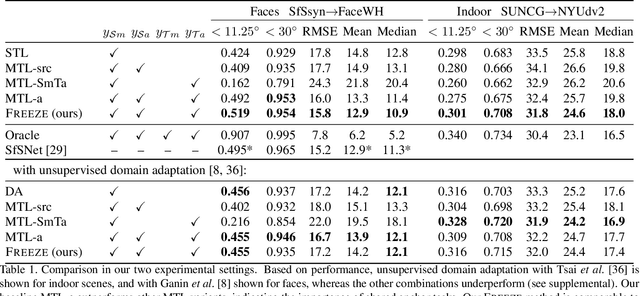
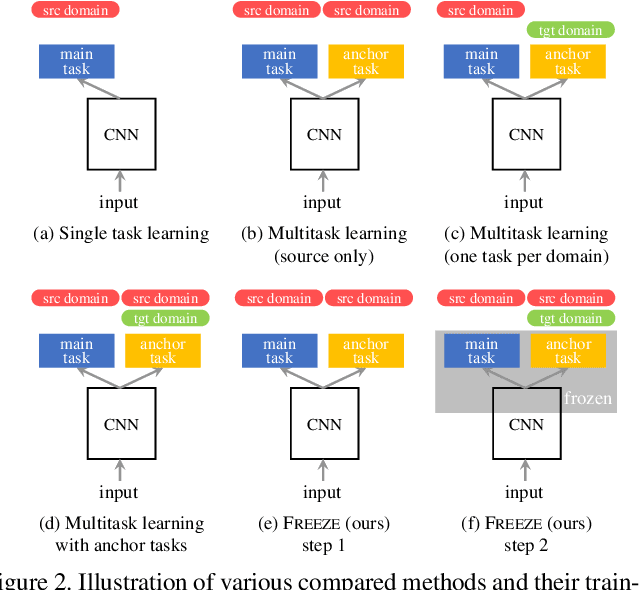
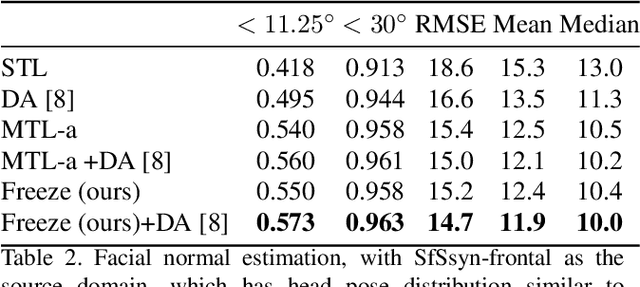
We introduce a novel domain adaptation formulation from synthetic dataset (source domain) to real dataset (target domain) for the category of tasks with per-pixel predictions. The annotations of these tasks are relatively hard to acquire in the real world, such as single-view depth estimation or surface normal estimation. Our key idea is to introduce anchor tasks, whose annotations are (1) less expensive to acquire than the main task, such as facial landmarks and semantic segmentations; and (2) shared in availability for both synthetic and real datasets so that it serves as "anchor" between tasks; and finally (3) aligned spatially with main task annotations on a per-pixel basis so that it also serves as spatial anchor between tasks' outputs. To further utilize spatial alignment between the anchor and main tasks, we introduce a novel freeze approach that freezes the final layers of our network after training on the source domain so that spatial and contextual relationship between tasks are maintained when adapting on the target domain. We evaluate our methods on two pairs of datasets, performing surface normal estimation in indoor scenes and faces, using semantic segmentation and facial landmarks as anchor tasks separately. We show the importance of using anchor tasks in both synthetic and real domains, and that the freeze approach outperforms competing approaches, reaching results in facial images on par with the state-of-the-art system that leverages detailed facial appearance model.
Silhouette Guided Point Cloud Reconstruction beyond Occlusion
Jul 29, 2019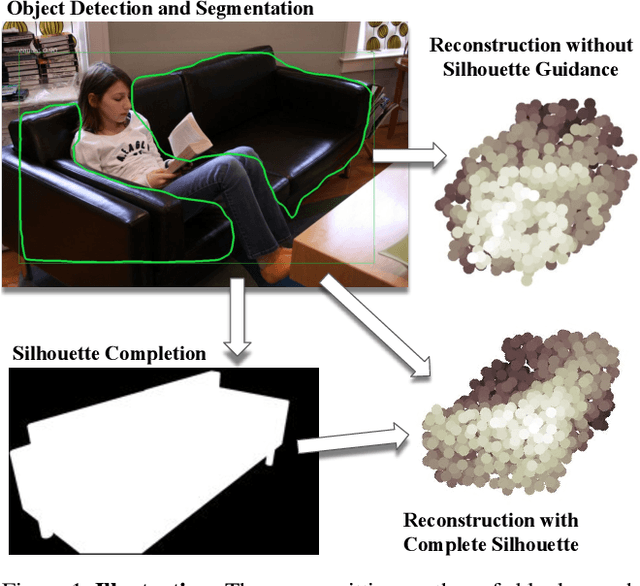
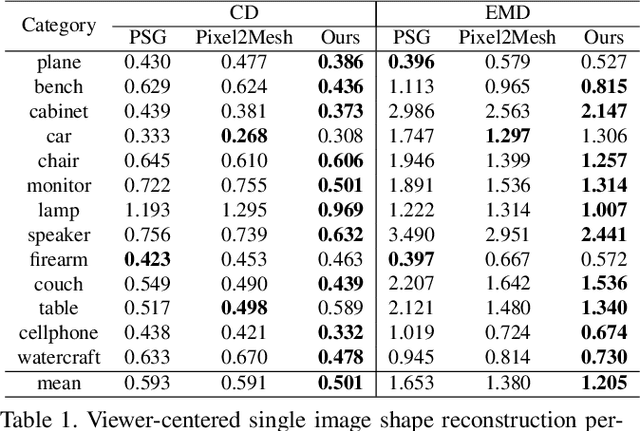
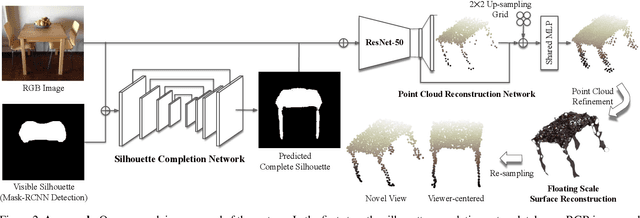

One major challenge in 3D reconstruction is to infer the complete shape geometry from partial foreground occlusions. In this paper, we propose a method to reconstruct the complete 3D shape of an object from a single RGB image, with robustness to occlusion. Given the image and a silhouette of the visible region, our approach completes the silhouette of the occluded region and then generates a point cloud. We show improvements for reconstruction of non-occluded and partially occluded objects by providing the predicted complete silhouette as guidance. We also improve state-of-the-art for 3D shape prediction with a 2D reprojection loss from multiple synthetic views and a surface-based smoothing and refinement step. Experiments demonstrate the efficacy of our approach both quantitatively and qualitatively on synthetic and real scene datasets.
No-Frills Human-Object Interaction Detection: Factorization, Appearance and Layout Encodings, and Training Techniques
Nov 14, 2018
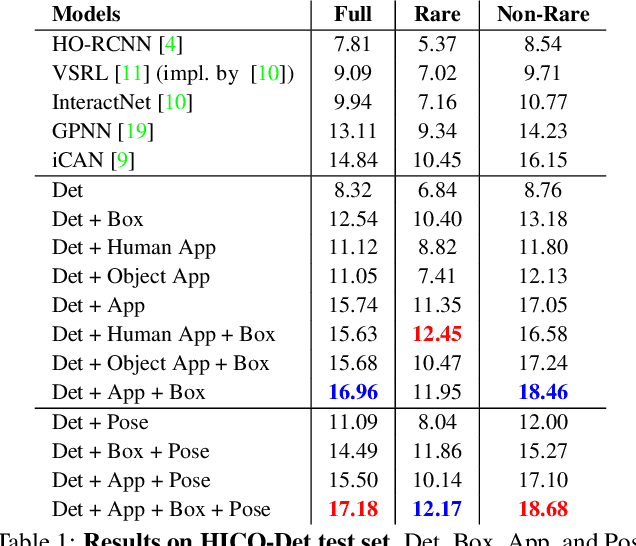
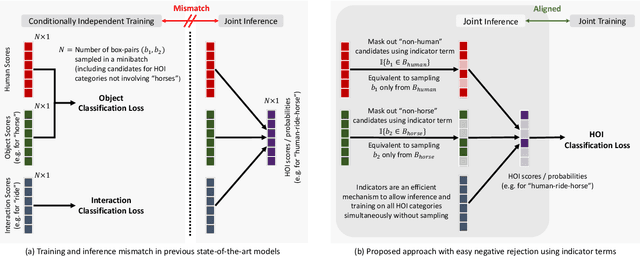

We show that with an appropriate factorization, and encodings of layout and appearance constructed from outputs of pretrained object detectors, a relatively simple model outperforms more sophisticated approaches on human-object interaction detection. Our model includes factors for detection scores, human and object appearance, and coarse (box-pair configuration) and optionally fine-grained layout (human pose). We also develop training techniques that improve learning efficiency by: (i) eliminating train-inference mismatch; (ii) rejecting easy negatives during mini-batch training; and (iii) using a ratio of negatives to positives that is two orders of magnitude larger than existing approaches while constructing training mini-batches. We conduct a thorough ablation study to understand the importance of different factors and training techniques using the challenging HICO-Det dataset.
Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction
Jun 12, 2018


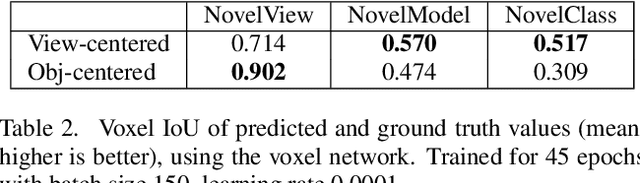
The goal of this paper is to compare surface-based and volumetric 3D object shape representations, as well as viewer-centered and object-centered reference frames for single-view 3D shape prediction. We propose a new algorithm for predicting depth maps from multiple viewpoints, with a single depth or RGB image as input. By modifying the network and the way models are evaluated, we can directly compare the merits of voxels vs. surfaces and viewer-centered vs. object-centered for familiar vs. unfamiliar objects, as predicted from RGB or depth images. Among our findings, we show that surface-based methods outperform voxel representations for objects from novel classes and produce higher resolution outputs. We also find that using viewer-centered coordinates is advantageous for novel objects, while object-centered representations are better for more familiar objects. Interestingly, the coordinate frame significantly affects the shape representation learned, with object-centered placing more importance on implicitly recognizing the object category and viewer-centered producing shape representations with less dependence on category recognition.
Imagine This! Scripts to Compositions to Videos
Apr 10, 2018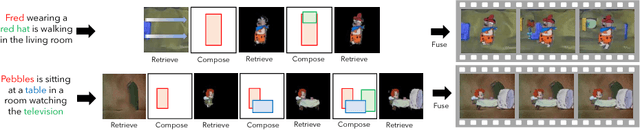

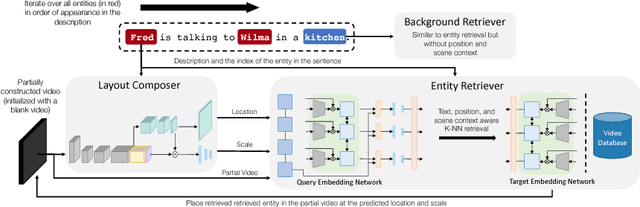
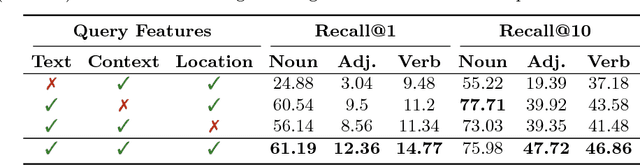
Imagining a scene described in natural language with realistic layout and appearance of entities is the ultimate test of spatial, visual, and semantic world knowledge. Towards this goal, we present the Composition, Retrieval, and Fusion Network (CRAFT), a model capable of learning this knowledge from video-caption data and applying it while generating videos from novel captions. CRAFT explicitly predicts a temporal-layout of mentioned entities (characters and objects), retrieves spatio-temporal entity segments from a video database and fuses them to generate scene videos. Our contributions include sequential training of components of CRAFT while jointly modeling layout and appearances, and losses that encourage learning compositional representations for retrieval. We evaluate CRAFT on semantic fidelity to caption, composition consistency, and visual quality. CRAFT outperforms direct pixel generation approaches and generalizes well to unseen captions and to unseen video databases with no text annotations. We demonstrate CRAFT on FLINTSTONES, a new richly annotated video-caption dataset with over 25000 videos. For a glimpse of videos generated by CRAFT, see https://youtu.be/688Vv86n0z8.
$\mathcal{G}$-Distillation: Reducing Overconfident Errors on Novel Samples
Apr 09, 2018

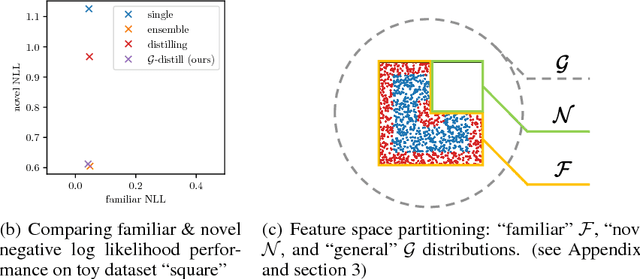

Counter to the intuition that unfamiliarity should lead to lack of confidence, current algorithms often make highly confident yet wrong predictions when faced with unexpected test samples from an unknown distribution different from training. Unlike all domain adaptation methods, we cannot gather an "unexpected dataset" prior to test. We propose a simple solution that reduces overconfident errors of samples from an unknown novel distribution without increasing evaluation time: train an ensemble of classifiers and then distill into a single model using both labeled and unlabeled examples. Experimentally, we investigate the overconfidence problem and evaluate our solution by creating "familiar" and "novel" test splits, where "familiar" are identically distributed with training and "novel" are not. We show that our solution yields more appropriate prediction confidences, on familiar and novel data, compared to single models and ensembles distilled on training data only. For example, we reduce confident errors in gender recognition by 94% on demographic groups different from the training data.
LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image
Mar 23, 2018
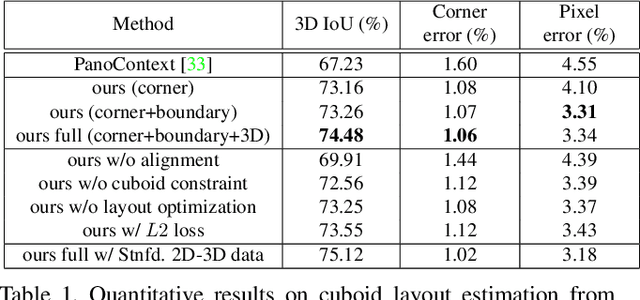
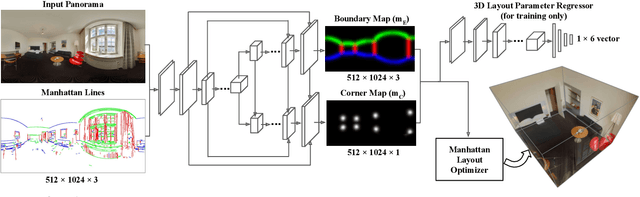
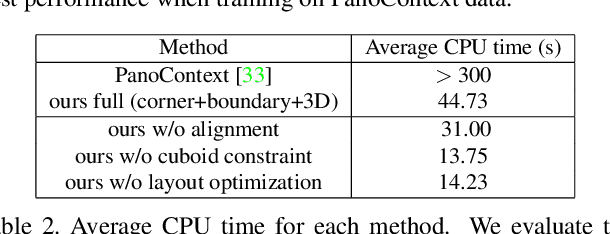
We propose an algorithm to predict room layout from a single image that generalizes across panoramas and perspective images, cuboid layouts and more general layouts (e.g. L-shape room). Our method operates directly on the panoramic image, rather than decomposing into perspective images as do recent works. Our network architecture is similar to that of RoomNet, but we show improvements due to aligning the image based on vanishing points, predicting multiple layout elements (corners, boundaries, size and translation), and fitting a constrained Manhattan layout to the resulting predictions. Our method compares well in speed and accuracy to other existing work on panoramas, achieves among the best accuracy for perspective images, and can handle both cuboid-shaped and more general Manhattan layouts.
Complete 3D Scene Parsing from Single RGBD Image
Oct 25, 2017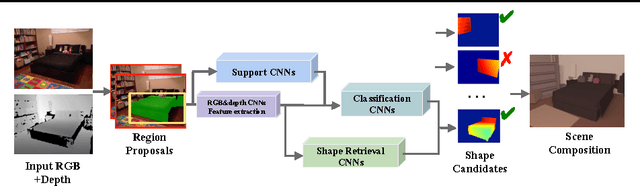


Inferring the location, shape, and class of each object in a single image is an important task in computer vision. In this paper, we aim to predict the full 3D parse of both visible and occluded portions of the scene from one RGBD image. We parse the scene by modeling objects as detailed CAD models with class labels and layouts as 3D planes. Such an interpretation is useful for visual reasoning and robotics, but difficult to produce due to the high degree of occlusion and the diversity of object classes. We follow the recent approaches that retrieve shape candidates for each RGBD region proposal, transfer and align associated 3D models to compose a scene that is consistent with observations. We propose to use support inference to aid interpretation and propose a retrieval scheme that uses convolutional neural networks (CNNs) to classify regions and retrieve objects with similar shapes. We demonstrate the performance of our method compared with the state-of-the-art on our new NYUd v2 dataset annotations which are semi-automatically labelled with detailed 3D shapes for all the objects.