 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregate Models, Not Explanations: Improving Feature Importance Estimation
Feb 12, 2026Feature-importance methods show promise in transforming machine learning models from predictive engines into tools for scientific discovery. However, due to data sampling and algorithmic stochasticity, expressive models can be unstable, leading to inaccurate variable importance estimates and undermining their utility in critical biomedical applications. Although ensembling offers a solution, deciding whether to explain a single ensemble model or aggregate individual model explanations is difficult due to the nonlinearity of importance measures and remains largely understudied. Our theoretical analysis, developed under assumptions accommodating complex state-of-the-art ML models, reveals that this choice is primarily driven by the model's excess risk. In contrast to prior literature, we show that ensembling at the model level provides more accurate variable-importance estimates, particularly for expressive models, by reducing this leading error term. We validate these findings on classical benchmarks and a large-scale proteomic study from the UK Biobank.
Hierarchical Variable Importance with Statistical Control for Medical Data-Based Prediction
Aug 12, 2025Recent advances in machine learning have greatly expanded the repertoire of predictive methods for medical imaging. However, the interpretability of complex models remains a challenge, which limits their utility in medical applications. Recently, model-agnostic methods have been proposed to measure conditional variable importance and accommodate complex non-linear models. However, they often lack power when dealing with highly correlated data, a common problem in medical imaging. We introduce Hierarchical-CPI, a model-agnostic variable importance measure that frames the inference problem as the discovery of groups of variables that are jointly predictive of the outcome. By exploring subgroups along a hierarchical tree, it remains computationally tractable, yet also enjoys explicit family-wise error rate control. Moreover, we address the issue of vanishing conditional importance under high correlation with a tree-based importance allocation mechanism. We benchmarked Hierarchical-CPI against state-of-the-art variable importance methods. Its effectiveness is demonstrated in two neuroimaging datasets: classifying dementia diagnoses from MRI data (ADNI dataset) and analyzing the Berger effect on EEG data (TDBRAIN dataset), identifying biologically plausible variables.
Measuring Variable Importance in Individual Treatment Effect Estimation with High Dimensional Data
Aug 23, 2024Causal machine learning (ML) promises to provide powerful tools for estimating individual treatment effects. Although causal ML methods are now well established, they still face the significant challenge of interpretability, which is crucial for medical applications. In this work, we propose a new algorithm based on the Conditional Permutation Importance (CPI) method for statistically rigorous variable importance assessment in the context of Conditional Average Treatment Effect (CATE) estimation. Our method termed PermuCATE is agnostic to both the meta-learner and the ML model used. Through theoretical analysis and empirical studies, we show that this approach provides a reliable measure of variable importance and exhibits lower variance compared to the standard Leave-One-Covariate-Out (LOCO) method. We illustrate how this property leads to increased statistical power, which is crucial for the application of explainable ML in small sample sizes or high-dimensional settings. We empirically demonstrate the benefits of our approach in various simulation scenarios, including previously proposed benchmarks as well as more complex settings with high-dimensional and correlated variables that require advanced CATE estimators.
Geodesic Optimization for Predictive Shift Adaptation on EEG data
Jul 04, 2024



Electroencephalography (EEG) data is often collected from diverse contexts involving different populations and EEG devices. This variability can induce distribution shifts in the data $X$ and in the biomedical variables of interest $y$, thus limiting the application of supervised machine learning (ML) algorithms. While domain adaptation (DA) methods have been developed to mitigate the impact of these shifts, such methods struggle when distribution shifts occur simultaneously in $X$ and $y$. As state-of-the-art ML models for EEG represent the data by spatial covariance matrices, which lie on the Riemannian manifold of Symmetric Positive Definite (SPD) matrices, it is appealing to study DA techniques operating on the SPD manifold. This paper proposes a novel method termed Geodesic Optimization for Predictive Shift Adaptation (GOPSA) to address test-time multi-source DA for situations in which source domains have distinct $y$ distributions. GOPSA exploits the geodesic structure of the Riemannian manifold to jointly learn a domain-specific re-centering operator representing site-specific intercepts and the regression model. We performed empirical benchmarks on the cross-site generalization of age-prediction models with resting-state EEG data from a large multi-national dataset (HarMNqEEG), which included $14$ recording sites and more than $1500$ human participants. Compared to state-of-the-art methods, our results showed that GOPSA achieved significantly higher performance on three regression metrics ($R^2$, MAE, and Spearman's $\rho$) for several source-target site combinations, highlighting its effectiveness in tackling multi-source DA with predictive shifts in EEG data analysis. Our method has the potential to combine the advantages of mixed-effects modeling with machine learning for biomedical applications of EEG, such as multicenter clinical trials.
Variable Importance in High-Dimensional Settings Requires Grouping
Dec 18, 2023Explaining the decision process of machine learning algorithms is nowadays crucial for both model's performance enhancement and human comprehension. This can be achieved by assessing the variable importance of single variables, even for high-capacity non-linear methods, e.g. Deep Neural Networks (DNNs). While only removal-based approaches, such as Permutation Importance (PI), can bring statistical validity, they return misleading results when variables are correlated. Conditional Permutation Importance (CPI) bypasses PI's limitations in such cases. However, in high-dimensional settings, where high correlations between the variables cancel their conditional importance, the use of CPI as well as other methods leads to unreliable results, besides prohibitive computation costs. Grouping variables statistically via clustering or some prior knowledge gains some power back and leads to better interpretations. In this work, we introduce BCPI (Block-Based Conditional Permutation Importance), a new generic framework for variable importance computation with statistical guarantees handling both single and group cases. Furthermore, as handling groups with high cardinality (such as a set of observations of a given modality) are both time-consuming and resource-intensive, we also introduce a new stacking approach extending the DNN architecture with sub-linear layers adapted to the group structure. We show that the ensuing approach extended with stacking controls the type-I error even with highly-correlated groups and shows top accuracy across benchmarks. Furthermore, we perform a real-world data analysis in a large-scale medical dataset where we aim to show the consistency between our results and the literature for a biomarker prediction.
Statistically Valid Variable Importance Assessment through Conditional Permutations
Sep 14, 2023



Variable importance assessment has become a crucial step in machine-learning applications when using complex learners, such as deep neural networks, on large-scale data. Removal-based importance assessment is currently the reference approach, particularly when statistical guarantees are sought to justify variable inclusion. It is often implemented with variable permutation schemes. On the flip side, these approaches risk misidentifying unimportant variables as important in the presence of correlations among covariates. Here we develop a systematic approach for studying Conditional Permutation Importance (CPI) that is model agnostic and computationally lean, as well as reusable benchmarks of state-of-the-art variable importance estimators. We show theoretically and empirically that $\textit{CPI}$ overcomes the limitations of standard permutation importance by providing accurate type-I error control. When used with a deep neural network, $\textit{CPI}$ consistently showed top accuracy across benchmarks. An empirical benchmark on real-world data analysis in a large-scale medical dataset showed that $\textit{CPI}$ provides a more parsimonious selection of statistically significant variables. Our results suggest that $\textit{CPI}$ can be readily used as drop-in replacement for permutation-based methods.
Manifold-regression to predict from MEG/EEG brain signals without source modeling
Jun 07, 2019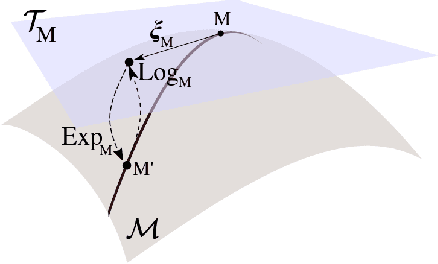
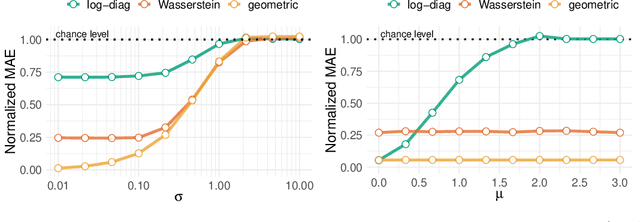
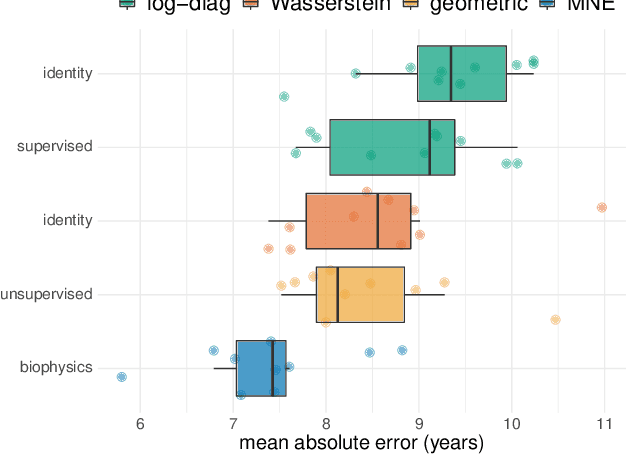
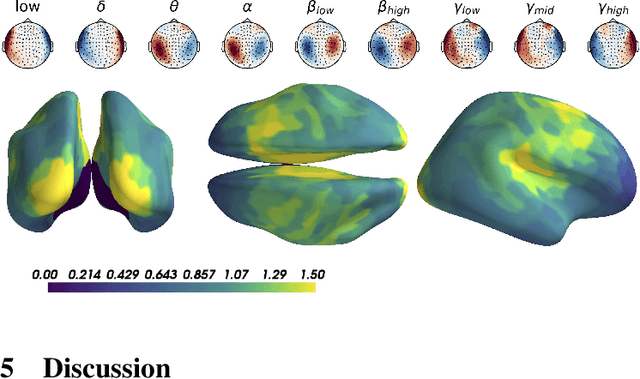
Magnetoencephalography and electroencephalography (M/EEG) can reveal neuronal dynamics non-invasively in real-time and are therefore appreciated methods in medicine and neuroscience. Recent advances in modeling brain-behavior relationships have highlighted the effectiveness of Riemannian geometry for summarizing the spatially correlated time-series from M/EEG in terms of their covariance. However, after artefact-suppression, M/EEG data is often rank deficient which limits the application of Riemannian concepts. In this article, we focus on the task of regression with rank-reduced covariance matrices. We study two Riemannian approaches that vectorize the M/EEG covariance between-sensors through projection into a tangent space. The Wasserstein distance readily applies to rank-reduced data but lacks affine-invariance. This can be overcome by finding a common subspace in which the covariance matrices are full rank, enabling the affine-invariant geometric distance. We investigated the implications of these two approaches in synthetic generative models, which allowed us to control estimation bias of a linear model for prediction. We show that Wasserstein and geometric distances allow perfect out-of-sample prediction on the generative models. We then evaluated the methods on real data with regard to their effectiveness in predicting age from M/EEG covariance matrices. The findings suggest that the data-driven Riemannian methods outperform different sensor-space estimators and that they get close to the performance of biophysics-driven source-localization model that requires MRI acquisitions and tedious data processing. Our study suggests that the proposed Riemannian methods can serve as fundamental building-blocks for automated large-scale analysis of M/EEG.