 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTaCK: Sentence Ordering with Temporal Commonsense Knowledge
Sep 06, 2021
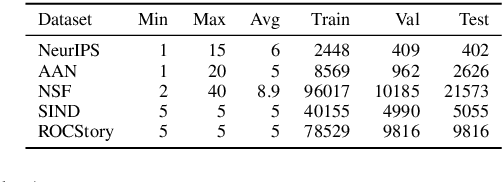
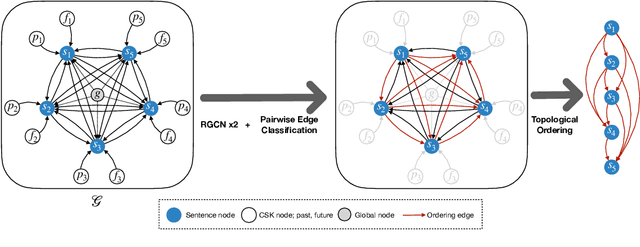
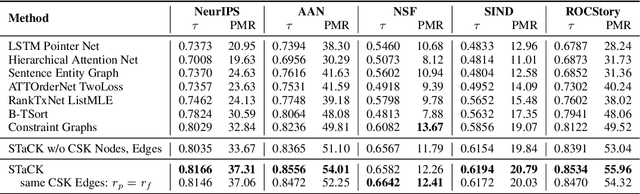
Sentence order prediction is the task of finding the correct order of sentences in a randomly ordered document. Correctly ordering the sentences requires an understanding of coherence with respect to the chronological sequence of events described in the text. Document-level contextual understanding and commonsense knowledge centered around these events are often essential in uncovering this coherence and predicting the exact chronological order. In this paper, we introduce STaCK -- a framework based on graph neural networks and temporal commonsense knowledge to model global information and predict the relative order of sentences. Our graph network accumulates temporal evidence using knowledge of `past' and `future' and formulates sentence ordering as a constrained edge classification problem. We report results on five different datasets, and empirically show that the proposed method is naturally suitable for order prediction. The implementation of this work is publicly available at: https://github.com/declare-lab/sentence-ordering.
Exemplars-guided Empathetic Response Generation Controlled by the Elements of Human Communication
Jun 22, 2021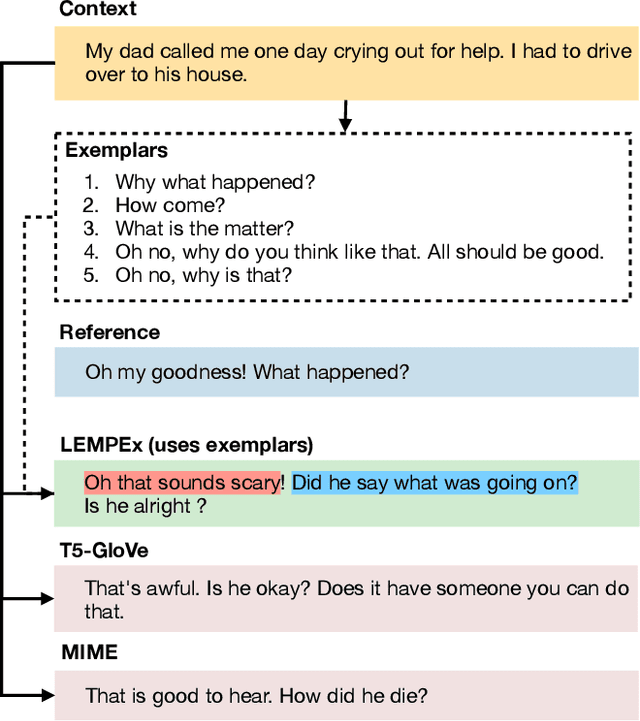
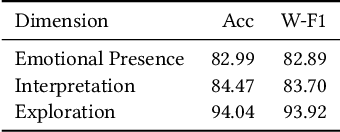
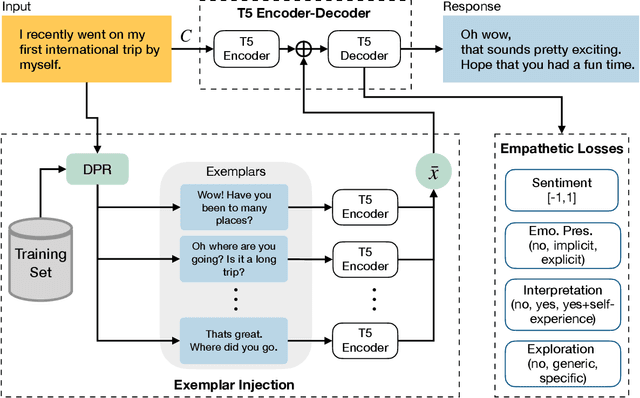
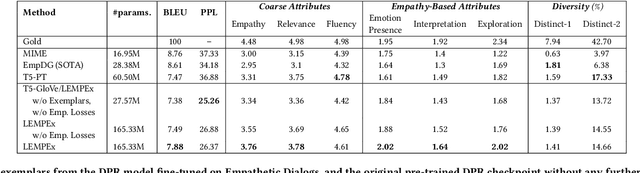
The majority of existing methods for empathetic response generation rely on the emotion of the context to generate empathetic responses. However, empathy is much more than generating responses with an appropriate emotion. It also often entails subtle expressions of understanding and personal resonance with the situation of the other interlocutor. Unfortunately, such qualities are difficult to quantify and the datasets lack the relevant annotations. To address this issue, in this paper we propose an approach that relies on exemplars to cue the generative model on fine stylistic properties that signal empathy to the interlocutor. To this end, we employ dense passage retrieval to extract relevant exemplary responses from the training set. Three elements of human communication -- emotional presence, interpretation, and exploration, and sentiment are additionally introduced using synthetic labels to guide the generation towards empathy. The human evaluation is also extended by these elements of human communication. We empirically show that these approaches yield significant improvements in empathetic response quality in terms of both automated and human-evaluated metrics. The implementation is available at https://github.com/declare-lab/exemplary-empathy.
CIDER: Commonsense Inference for Dialogue Explanation and Reasoning
Jun 01, 2021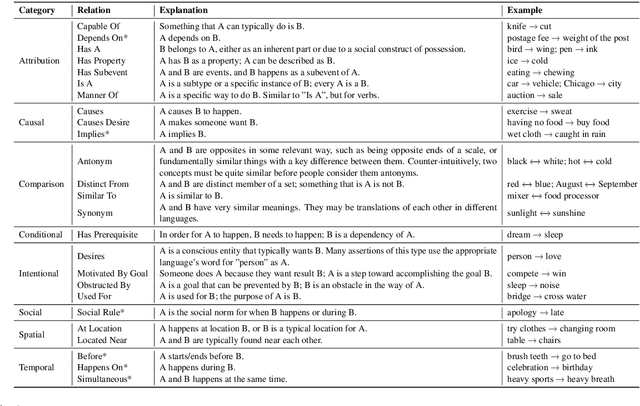

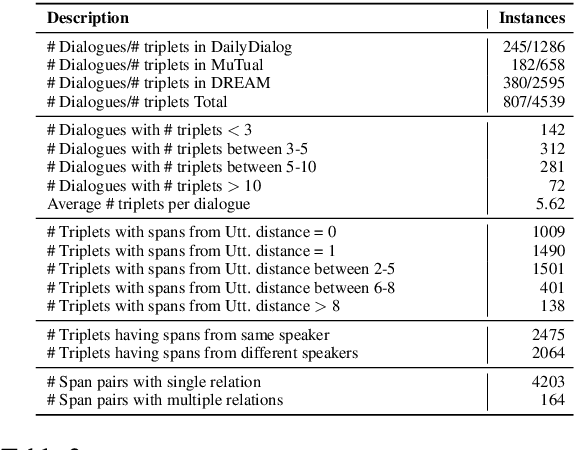

Commonsense inference to understand and explain human language is a fundamental research problem in natural language processing. Explaining human conversations poses a great challenge as it requires contextual understanding, planning, inference, and several aspects of reasoning including causal, temporal, and commonsense reasoning. In this work, we introduce CIDER -- a manually curated dataset that contains dyadic dialogue explanations in the form of implicit and explicit knowledge triplets inferred using contextual commonsense inference. Extracting such rich explanations from conversations can be conducive to improving several downstream applications. The annotated triplets are categorized by the type of commonsense knowledge present (e.g., causal, conditional, temporal). We set up three different tasks conditioned on the annotated dataset: Dialogue-level Natural Language Inference, Span Extraction, and Multi-choice Span Selection. Baseline results obtained with transformer-based models reveal that the tasks are difficult, paving the way for promising future research. The dataset and the baseline implementations are publicly available at https://github.com/declare-lab/CIDER.
Recognizing Emotion Cause in Conversations
Dec 24, 2020
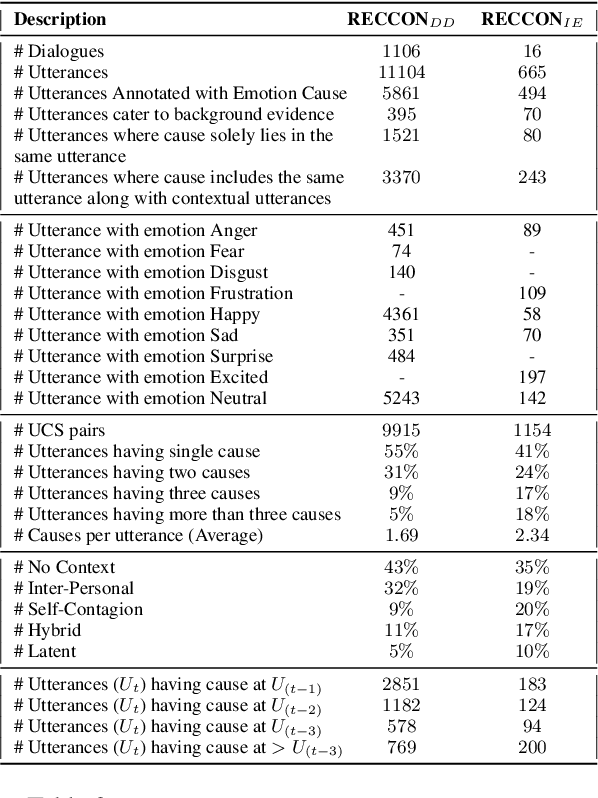

Recognizing the cause behind emotions in text is a fundamental yet under-explored area of research in NLP. Advances in this area hold the potential to improve interpretability and performance in affect-based models. Identifying emotion causes at the utterance level in conversations is particularly challenging due to the intermingling dynamic among the interlocutors. To this end, we introduce the task of recognizing emotion cause in conversations with an accompanying dataset named RECCON. Furthermore, we define different cause types based on the source of the causes and establish strong transformer-based baselines to address two different sub-tasks of RECCON: 1) Causal Span Extraction and 2) Causal Emotion Entailment. The dataset is available at https://github.com/declare-lab/RECCON.
Improving Zero Shot Learning Baselines with Commonsense Knowledge
Dec 11, 2020

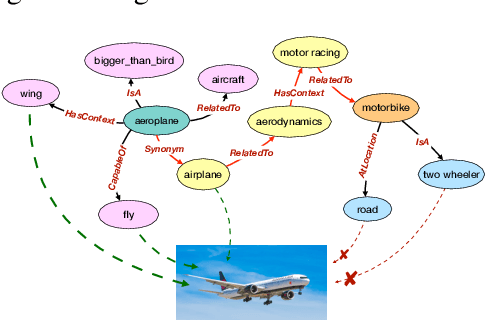

Zero shot learning -- the problem of training and testing on a completely disjoint set of classes -- relies greatly on its ability to transfer knowledge from train classes to test classes. Traditionally semantic embeddings consisting of human defined attributes (HA) or distributed word embeddings (DWE) are used to facilitate this transfer by improving the association between visual and semantic embeddings. In this paper, we take advantage of explicit relations between nodes defined in ConceptNet, a commonsense knowledge graph, to generate commonsense embeddings of the class labels by using a graph convolution network-based autoencoder. Our experiments performed on three standard benchmark datasets surpass the strong baselines when we fuse our commonsense embeddings with existing semantic embeddings i.e. HA and DWE.
Persuasive Dialogue Understanding: the Baselines and Negative Results
Nov 22, 2020
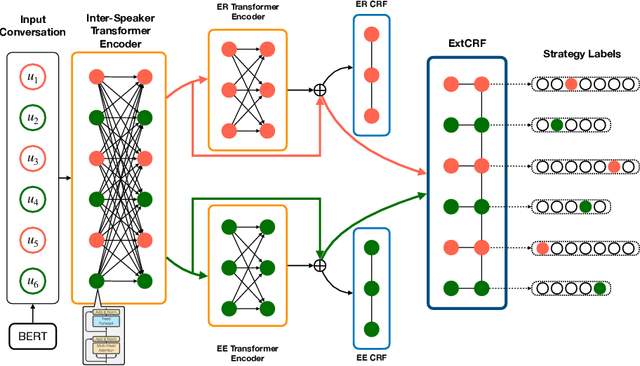
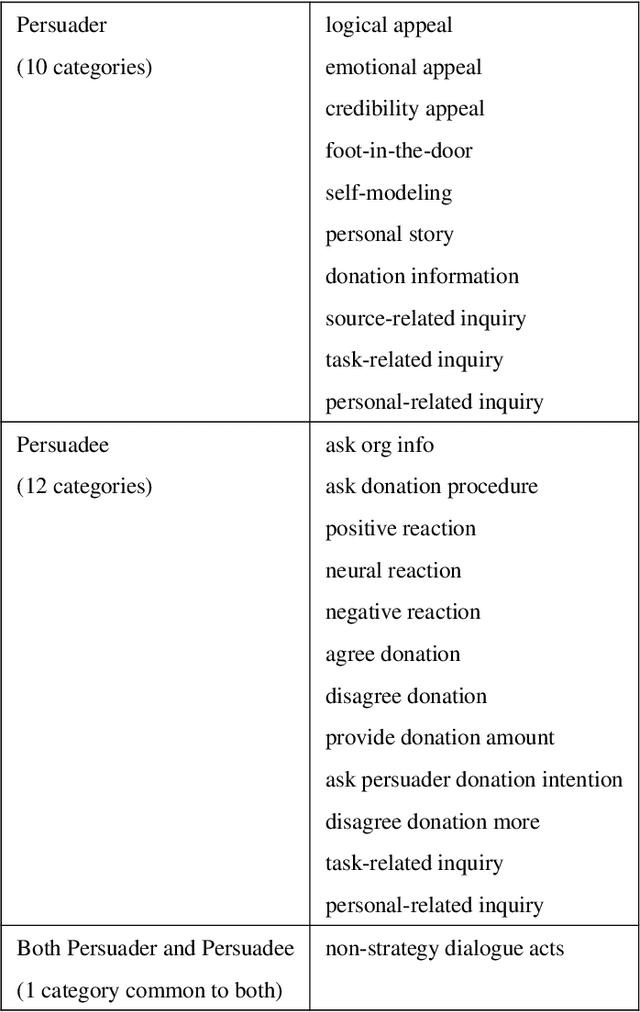
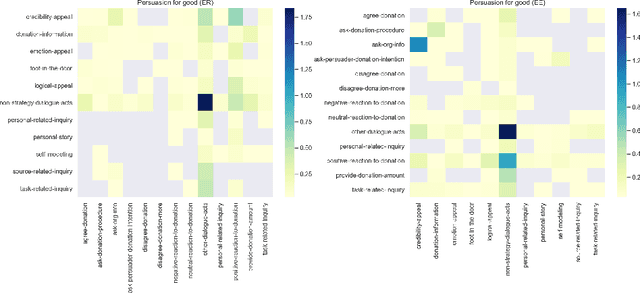
Persuasion aims at forming one's opinion and action via a series of persuasive messages containing persuader's strategies. Due to its potential application in persuasive dialogue systems, the task of persuasive strategy recognition has gained much attention lately. Previous methods on user intent recognition in dialogue systems adopt recurrent neural network (RNN) or convolutional neural network (CNN) to model context in conversational history, neglecting the tactic history and intra-speaker relation. In this paper, we demonstrate the limitations of a Transformer-based approach coupled with Conditional Random Field (CRF) for the task of persuasive strategy recognition. In this model, we leverage inter- and intra-speaker contextual semantic features, as well as label dependencies to improve the recognition. Despite extensive hyper-parameter optimizations, this architecture fails to outperform the baseline methods. We observe two negative results. Firstly, CRF cannot capture persuasive label dependencies, possibly as strategies in persuasive dialogues do not follow any strict grammar or rules as the cases in Named Entity Recognition (NER) or part-of-speech (POS) tagging. Secondly, the Transformer encoder trained from scratch is less capable of capturing sequential information in persuasive dialogues than Long Short-Term Memory (LSTM). We attribute this to the reason that the vanilla Transformer encoder does not efficiently consider relative position information of sequence elements.
Utterance-level Dialogue Understanding: An Empirical Study
Oct 22, 2020
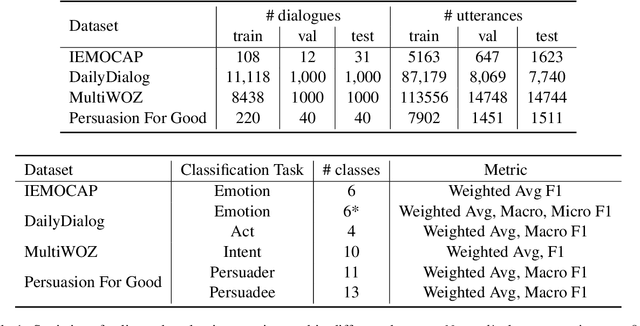
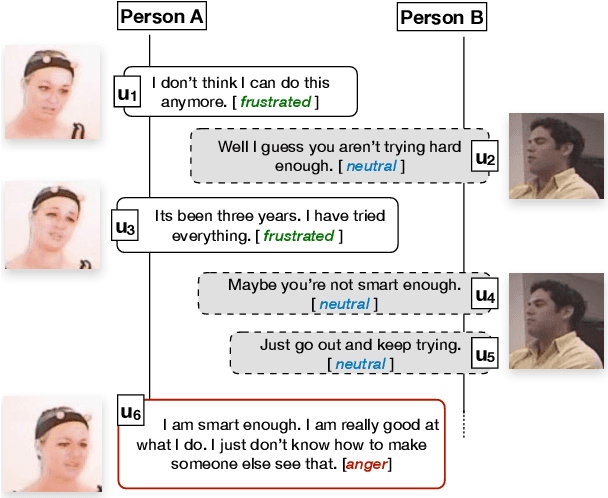

The recent abundance of conversational data on the Web and elsewhere calls for effective NLP systems for dialog understanding. Complete utterance-level understanding often requires context understanding, defined by nearby utterances. In recent years, a number of approaches have been proposed for various utterance-level dialogue understanding tasks. Most of these approaches account for the context for effective understanding. In this paper, we explore and quantify the role of context for different aspects of a dialogue, namely emotion, intent, and dialogue act identification, using state-of-the-art dialog understanding methods as baselines. Specifically, we employ various perturbations to distort the context of a given utterance and study its impact on the different tasks and baselines. This provides us with insights into the fundamental contextual controlling factors of different aspects of a dialogue. Such insights can inspire more effective dialogue understanding models, and provide support for future text generation approaches. The implementation pertaining to this work is available at https://github.com/declare-lab/dialogue-understanding.
COSMIC: COmmonSense knowledge for eMotion Identification in Conversations
Oct 06, 2020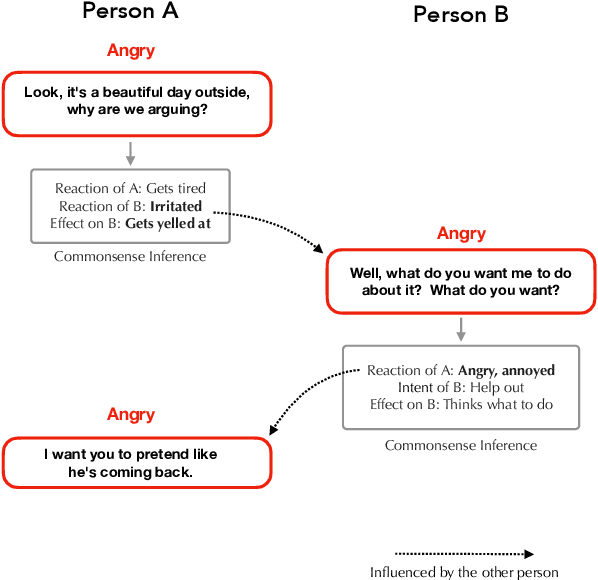
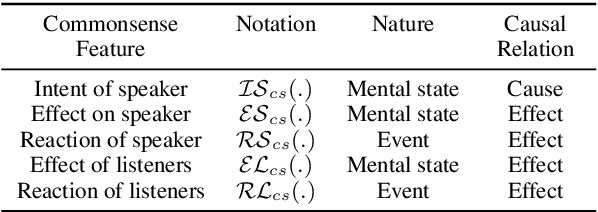
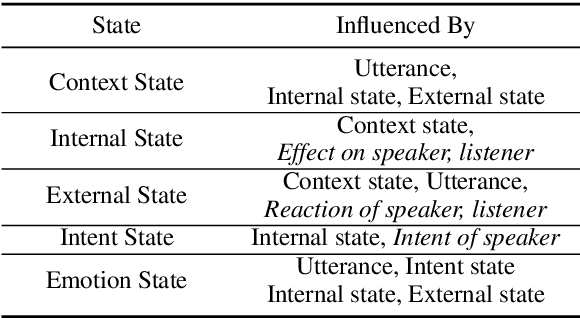
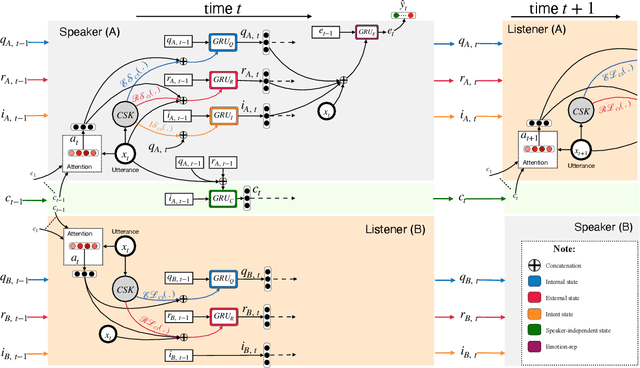
In this paper, we address the task of utterance level emotion recognition in conversations using commonsense knowledge. We propose COSMIC, a new framework that incorporates different elements of commonsense such as mental states, events, and causal relations, and build upon them to learn interactions between interlocutors participating in a conversation. Current state-of-the-art methods often encounter difficulties in context propagation, emotion shift detection, and differentiating between related emotion classes. By learning distinct commonsense representations, COSMIC addresses these challenges and achieves new state-of-the-art results for emotion recognition on four different benchmark conversational datasets. Our code is available at https://github.com/declare-lab/conv-emotion.
MIME: MIMicking Emotions for Empathetic Response Generation
Oct 04, 2020

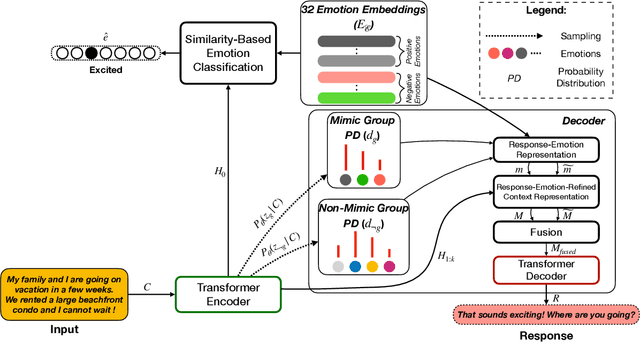
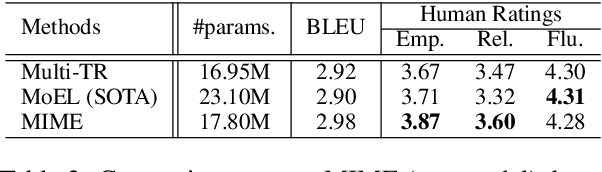
Current approaches to empathetic response generation view the set of emotions expressed in the input text as a flat structure, where all the emotions are treated uniformly. We argue that empathetic responses often mimic the emotion of the user to a varying degree, depending on its positivity or negativity and content. We show that the consideration of this polarity-based emotion clusters and emotional mimicry results in improved empathy and contextual relevance of the response as compared to the state-of-the-art. Also, we introduce stochasticity into the emotion mixture that yields emotionally more varied empathetic responses than the previous work. We demonstrate the importance of these factors to empathetic response generation using both automatic- and human-based evaluations. The implementation of MIME is publicly available at https://github.com/declare-lab/MIME.
Visual Interest Prediction with Attentive Multi-Task Transfer Learning
May 27, 2020
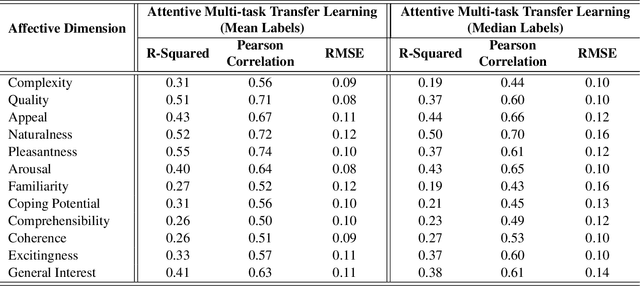
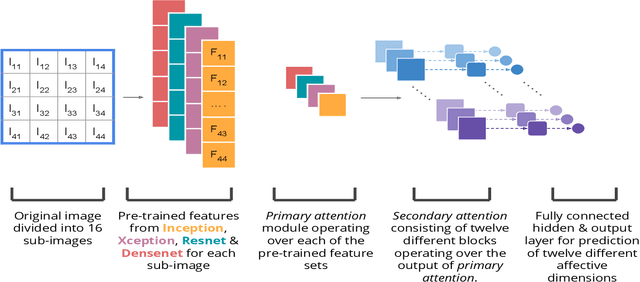
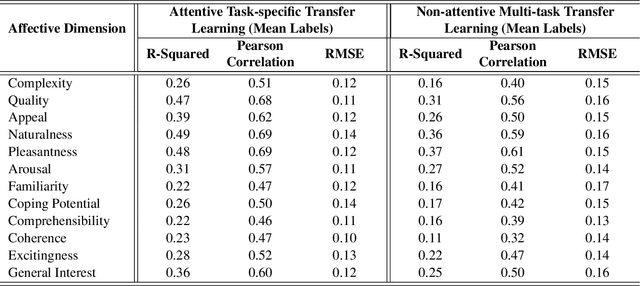
Visual interest & affect prediction is a very interesting area of research in the area of computer vision. In this paper, we propose a transfer learning and attention mechanism based neural network model to predict visual interest & affective dimensions in digital photos. Learning the multi-dimensional affects is addressed through a multi-task learning framework. With various experiments we show the effectiveness of the proposed approach. Evaluation of our model on the benchmark dataset shows large improvement over current state-of-the-art systems.