 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse, not Short: A Length-Controlled Self-Learning Framework for Improving Response Diversity of Language Models
May 22, 2025



Diverse language model responses are crucial for creative generation, open-ended tasks, and self-improvement training. We show that common diversity metrics, and even reward models used for preference optimization, systematically bias models toward shorter outputs, limiting expressiveness. To address this, we introduce Diverse, not Short (Diverse-NS), a length-controlled self-learning framework that improves response diversity while maintaining length parity. By generating and filtering preference data that balances diversity, quality, and length, Diverse-NS enables effective training using only 3,000 preference pairs. Applied to LLaMA-3.1-8B and the Olmo-2 family, Diverse-NS substantially enhances lexical and semantic diversity. We show consistent improvement in diversity with minor reduction or gains in response quality on four creative generation tasks: Divergent Associations, Persona Generation, Alternate Uses, and Creative Writing. Surprisingly, experiments with the Olmo-2 model family (7B, and 13B) show that smaller models like Olmo-2-7B can serve as effective "diversity teachers" for larger models. By explicitly addressing length bias, our method efficiently pushes models toward more diverse and expressive outputs.
A Survey on Data Curation for Visual Contrastive Learning: Why Crafting Effective Positive and Negative Pairs Matters
Feb 12, 2025Visual contrastive learning aims to learn representations by contrasting similar (positive) and dissimilar (negative) pairs of data samples. The design of these pairs significantly impacts representation quality, training efficiency, and computational cost. A well-curated set of pairs leads to stronger representations and faster convergence. As contrastive pre-training sees wider adoption for solving downstream tasks, data curation becomes essential for optimizing its effectiveness. In this survey, we attempt to create a taxonomy of existing techniques for positive and negative pair curation in contrastive learning, and describe them in detail.
Active Learning for Improved Semi-Supervised Semantic Segmentation in Satellite Images
Oct 15, 2021

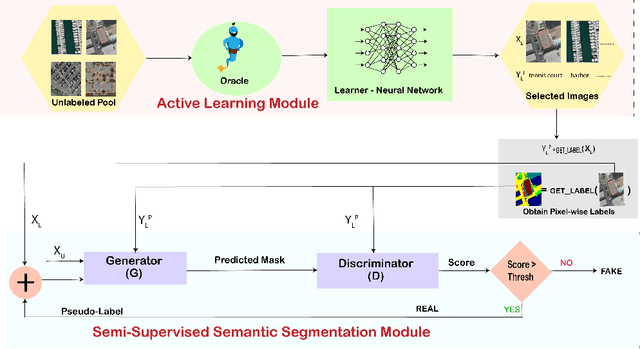

Remote sensing data is crucial for applications ranging from monitoring forest fires and deforestation to tracking urbanization. Most of these tasks require dense pixel-level annotations for the model to parse visual information from limited labeled data available for these satellite images. Due to the dearth of high-quality labeled training data in this domain, there is a need to focus on semi-supervised techniques. These techniques generate pseudo-labels from a small set of labeled examples which are used to augment the labeled training set. This makes it necessary to have a highly representative and diverse labeled training set. Therefore, we propose to use an active learning-based sampling strategy to select a highly representative set of labeled training data. We demonstrate our proposed method's effectiveness on two existing semantic segmentation datasets containing satellite images: UC Merced Land Use Classification Dataset and DeepGlobe Land Cover Classification Dataset. We report a 27% improvement in mIoU with as little as 2% labeled data using active learning sampling strategies over randomly sampling the small set of labeled training data.
Pedestrian Detection in Thermal Images using Saliency Maps
Apr 15, 2019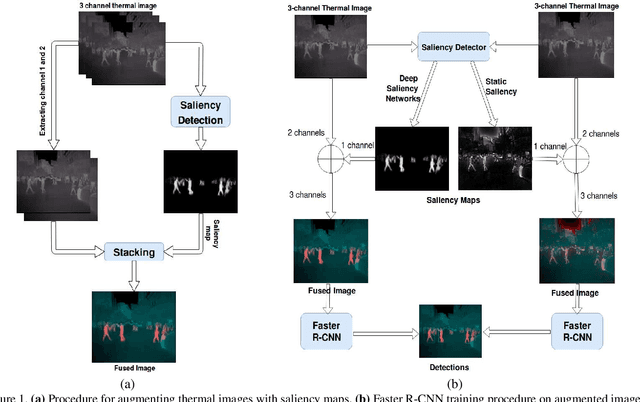
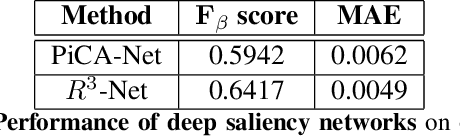

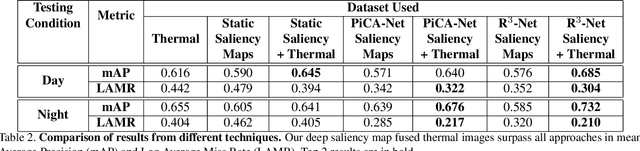
Thermal images are mainly used to detect the presence of people at night or in bad lighting conditions, but perform poorly at daytime. To solve this problem, most state-of-the-art techniques employ a fusion network that uses features from paired thermal and color images. Instead, we propose to augment thermal images with their saliency maps, to serve as an attention mechanism for the pedestrian detector especially during daytime. We investigate how such an approach results in improved performance for pedestrian detection using only thermal images, eliminating the need for paired color images. For our experiments, we train the Faster R-CNN for pedestrian detection and report the added effect of saliency maps generated using static and deep methods (PiCA-Net and R3-Net). Our best performing model results in an absolute reduction of miss rate by 13.4% and 19.4% over the baseline in day and night images respectively. We also annotate and release pixel level masks of pedestrians on a subset of the KAIST Multispectral Pedestrian Detection dataset, which is a first publicly available dataset for salient pedestrian detection.