 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Supervision for Walmart's Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Apr 10, 2026Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
Unified Supervision for Walmarts Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Apr 09, 2026Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
A Survey on Data Curation for Visual Contrastive Learning: Why Crafting Effective Positive and Negative Pairs Matters
Feb 12, 2025Visual contrastive learning aims to learn representations by contrasting similar (positive) and dissimilar (negative) pairs of data samples. The design of these pairs significantly impacts representation quality, training efficiency, and computational cost. A well-curated set of pairs leads to stronger representations and faster convergence. As contrastive pre-training sees wider adoption for solving downstream tasks, data curation becomes essential for optimizing its effectiveness. In this survey, we attempt to create a taxonomy of existing techniques for positive and negative pair curation in contrastive learning, and describe them in detail.
Active Learning for Improved Semi-Supervised Semantic Segmentation in Satellite Images
Oct 15, 2021

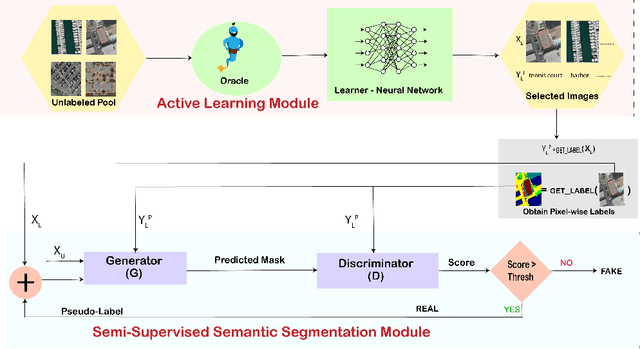

Remote sensing data is crucial for applications ranging from monitoring forest fires and deforestation to tracking urbanization. Most of these tasks require dense pixel-level annotations for the model to parse visual information from limited labeled data available for these satellite images. Due to the dearth of high-quality labeled training data in this domain, there is a need to focus on semi-supervised techniques. These techniques generate pseudo-labels from a small set of labeled examples which are used to augment the labeled training set. This makes it necessary to have a highly representative and diverse labeled training set. Therefore, we propose to use an active learning-based sampling strategy to select a highly representative set of labeled training data. We demonstrate our proposed method's effectiveness on two existing semantic segmentation datasets containing satellite images: UC Merced Land Use Classification Dataset and DeepGlobe Land Cover Classification Dataset. We report a 27% improvement in mIoU with as little as 2% labeled data using active learning sampling strategies over randomly sampling the small set of labeled training data.