 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNapTune: Efficient Model Tuning for Mood Classification using Previous Night's Sleep Measures along with Wearable Time-series
Sep 07, 2024Sleep is known to be a key factor in emotional regulation and overall mental health. In this study, we explore the integration of sleep measures from the previous night into wearable-based mood recognition. To this end, we propose NapTune, a novel prompt-tuning framework that utilizes sleep-related measures as additional inputs to a frozen pre-trained wearable time-series encoder by adding and training lightweight prompt parameters to each Transformer layer. Through rigorous empirical evaluation, we demonstrate that the inclusion of sleep data using NapTune not only improves mood recognition performance across different wearable time-series namely ECG, PPG, and EDA, but also makes it more sample-efficient. Our method demonstrates significant improvements over the best baselines and unimodal variants. Furthermore, we analyze the impact of adding sleep-related measures on recognizing different moods as well as the influence of individual sleep-related measures.
Speech Emotion Recognition with Distilled Prosodic and Linguistic Affect Representations
Sep 09, 2023



We propose EmoDistill, a novel speech emotion recognition (SER) framework that leverages cross-modal knowledge distillation during training to learn strong linguistic and prosodic representations of emotion from speech. During inference, our method only uses a stream of speech signals to perform unimodal SER thus reducing computation overhead and avoiding run-time transcription and prosodic feature extraction errors. During training, our method distills information at both embedding and logit levels from a pair of pre-trained Prosodic and Linguistic teachers that are fine-tuned for SER. Experiments on the IEMOCAP benchmark demonstrate that our method outperforms other unimodal and multimodal techniques by a considerable margin, and achieves state-of-the-art performance of 77.49% unweighted accuracy and 78.91% weighted accuracy. Detailed ablation studies demonstrate the impact of each component of our method.
Region-Disentangled Diffusion Model for High-Fidelity PPG-to-ECG Translation
Aug 25, 2023



The high prevalence of cardiovascular diseases (CVDs) calls for accessible and cost-effective continuous cardiac monitoring tools. Despite Electrocardiography (ECG) being the gold standard, continuous monitoring remains a challenge, leading to the exploration of Photoplethysmography (PPG), a promising but more basic alternative available in consumer wearables. This notion has recently spurred interest in translating PPG to ECG signals. In this work, we introduce Region-Disentangled Diffusion Model (RDDM), a novel diffusion model designed to capture the complex temporal dynamics of ECG. Traditional Diffusion models like Denoising Diffusion Probabilistic Models (DDPM) face challenges in capturing such nuances due to the indiscriminate noise addition process across the entire signal. Our proposed RDDM overcomes such limitations by incorporating a novel forward process that selectively adds noise to specific regions of interest (ROI) such as QRS complex in ECG signals, and a reverse process that disentangles the denoising of ROI and non-ROI regions. Quantitative experiments demonstrate that RDDM can generate high-fidelity ECG from PPG in as few as 10 diffusion steps, making it highly effective and computationally efficient. Additionally, to rigorously validate the usefulness of the generated ECG signals, we introduce CardioBench, a comprehensive evaluation benchmark for a variety of cardiac-related tasks including heart rate and blood pressure estimation, stress classification, and the detection of atrial fibrillation and diabetes. Our thorough experiments show that RDDM achieves state-of-the-art performance on CardioBench. To the best of our knowledge, RDDM is the first diffusion model for cross-modal signal-to-signal translation in the bio-signal domain.
EXnet: Efficient In-context Learning for Data-less Text classification
May 24, 2023Large pre-trained language models (PLMs) have made significant progress in encoding world knowledge and spawned a new set of learning paradigms including zero-shot, few-shot, and in-context learning. Many language tasks can be modeled as a set of prompts (for example, is this text about geography?) and language models can provide binary answers, i.e., Yes or No. There is evidence to suggest that the next-word prediction used by many PLMs does not align well with zero-shot paradigms. Therefore, PLMs are fine-tuned as a question-answering system. In-context learning extends zero-shot learning by incorporating prompts and examples, resulting in increased task accuracy. Our paper presents EXnet, a model specifically designed to perform in-context learning without any limitations on the number of examples. We argue that in-context learning is an effective method to increase task accuracy, and providing examples facilitates cross-task generalization, especially when it comes to text classification tasks. With extensive experiments, we show that even our smallest model (15M parameters) generalizes to several unseen classification tasks and domains.
Federated learning and next generation wireless communications: A survey on bidirectional relationship
Oct 14, 2021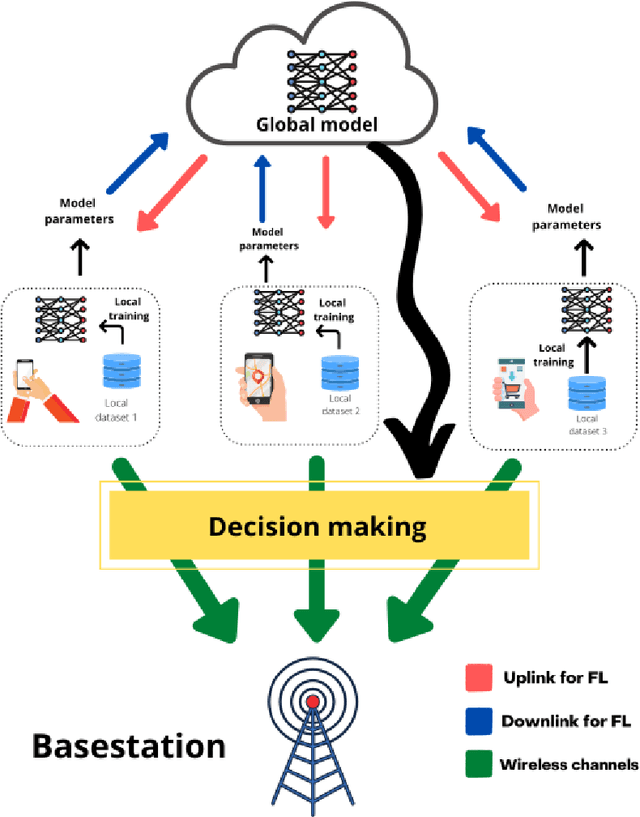
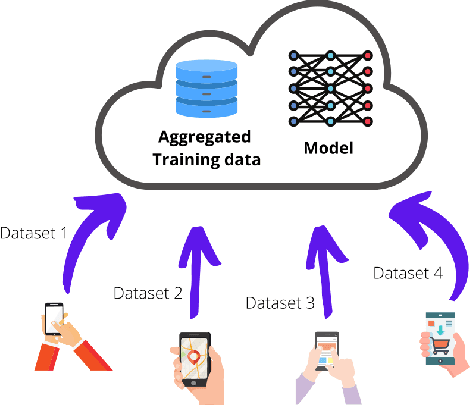
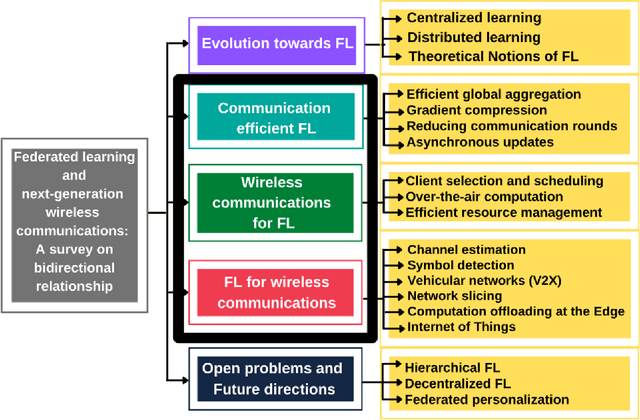
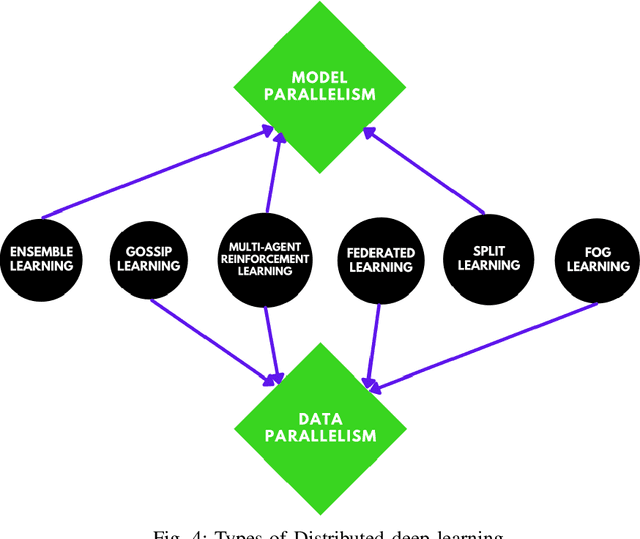
In order to meet the extremely heterogeneous requirements of the next generation wireless communication networks, research community is increasingly dependent on using machine learning solutions for real-time decision-making and radio resource management. Traditional machine learning employs fully centralized architecture in which the entire training data is collected at one node e.g., cloud server, that significantly increases the communication overheads and also raises severe privacy concerns. Towards this end, a distributed machine learning paradigm termed as Federated learning (FL) has been proposed recently. In FL, each participating edge device trains its local model by using its own training data. Then, via the wireless channels the weights or parameters of the locally trained models are sent to the central PS, that aggregates them and updates the global model. On one hand, FL plays an important role for optimizing the resources of wireless communication networks, on the other hand, wireless communications is crucial for FL. Thus, a `bidirectional' relationship exists between FL and wireless communications. Although FL is an emerging concept, many publications have already been published in the domain of FL and its applications for next generation wireless networks. Nevertheless, we noticed that none of the works have highlighted the bidirectional relationship between FL and wireless communications. Therefore, the purpose of this survey paper is to bridge this gap in literature by providing a timely and comprehensive discussion on the interdependency between FL and wireless communications.