 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Adaptation: Historical Contrastive Learning for Unsupervised Domain Adaptation without Source Data
Oct 31, 2021
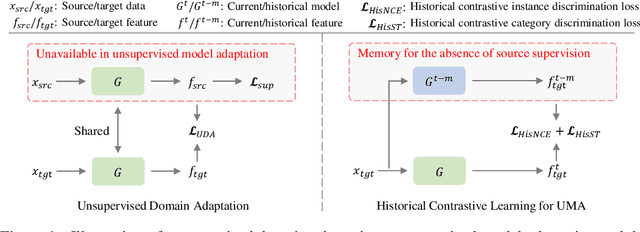
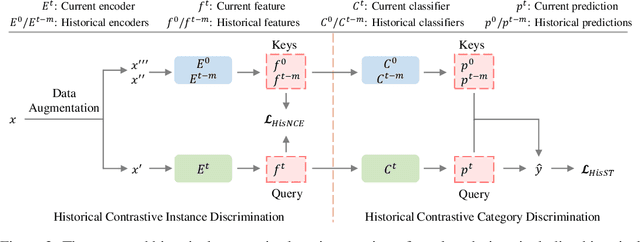
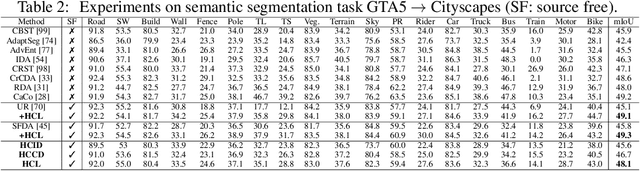
Unsupervised domain adaptation aims to align a labeled source domain and an unlabeled target domain, but it requires to access the source data which often raises concerns in data privacy, data portability and data transmission efficiency. We study unsupervised model adaptation (UMA), or called Unsupervised Domain Adaptation without Source Data, an alternative setting that aims to adapt source-trained models towards target distributions without accessing source data. To this end, we design an innovative historical contrastive learning (HCL) technique that exploits historical source hypothesis to make up for the absence of source data in UMA. HCL addresses the UMA challenge from two perspectives. First, it introduces historical contrastive instance discrimination (HCID) that learns from target samples by contrasting their embeddings which are generated by the currently adapted model and the historical models. With the historical models, HCID encourages UMA to learn instance-discriminative target representations while preserving the source hypothesis. Second, it introduces historical contrastive category discrimination (HCCD) that pseudo-labels target samples to learn category-discriminative target representations. Specifically, HCCD re-weights pseudo labels according to their prediction consistency across the current and historical models. Extensive experiments show that HCL outperforms and state-of-the-art methods consistently across a variety of visual tasks and setups.
Domain Adaptive Video Segmentation via Temporal Consistency Regularization
Jul 23, 2021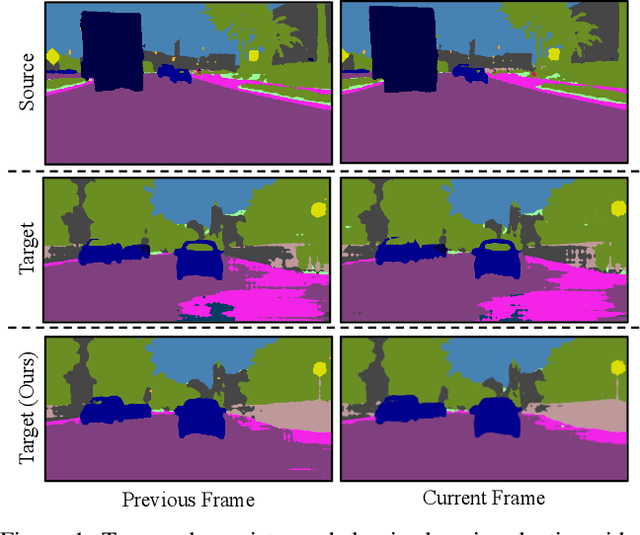

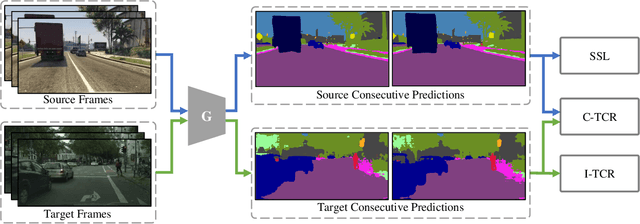

Video semantic segmentation is an essential task for the analysis and understanding of videos. Recent efforts largely focus on supervised video segmentation by learning from fully annotated data, but the learnt models often experience clear performance drop while applied to videos of a different domain. This paper presents DA-VSN, a domain adaptive video segmentation network that addresses domain gaps in videos by temporal consistency regularization (TCR) for consecutive frames of target-domain videos. DA-VSN consists of two novel and complementary designs. The first is cross-domain TCR that guides the prediction of target frames to have similar temporal consistency as that of source frames (learnt from annotated source data) via adversarial learning. The second is intra-domain TCR that guides unconfident predictions of target frames to have similar temporal consistency as confident predictions of target frames. Extensive experiments demonstrate the superiority of our proposed domain adaptive video segmentation network which outperforms multiple baselines consistently by large margins.
SynLiDAR: Learning From Synthetic LiDAR Sequential Point Cloud for Semantic Segmentation
Jul 12, 2021
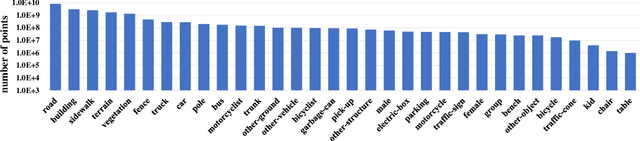
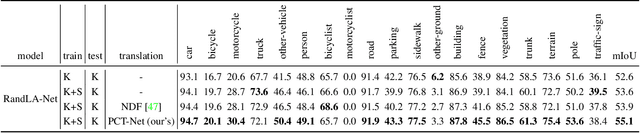
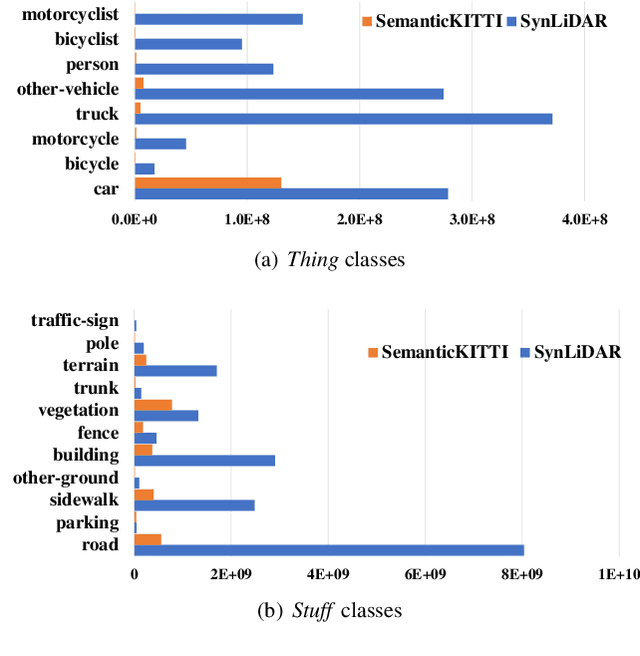
Transfer learning from synthetic to real data has been proved an effective way of mitigating data annotation constraints in various computer vision tasks. However, the developments focused on 2D images but lag far behind for 3D point clouds due to the lack of large-scale high-quality synthetic point cloud data and effective transfer methods. We address this issue by collecting SynLiDAR, a synthetic LiDAR point cloud dataset that contains large-scale point-wise annotated point cloud with accurate geometric shapes and comprehensive semantic classes, and designing PCT-Net, a point cloud translation network that aims to narrow down the gap with real-world point cloud data. For SynLiDAR, we leverage graphic tools and professionals who construct multiple realistic virtual environments with rich scene types and layouts where annotated LiDAR points can be generated automatically. On top of that, PCT-Net disentangles synthetic-to-real gaps into an appearance component and a sparsity component and translates SynLiDAR by aligning the two components with real-world data separately. Extensive experiments over multiple data augmentation and semi-supervised semantic segmentation tasks show very positive outcomes - including SynLiDAR can either train better models or reduce real-world annotated data without sacrificing performance, and PCT-Net translated data further improve model performance consistently.
Category Contrast for Unsupervised Domain Adaptation in Visual Tasks
Jun 08, 2021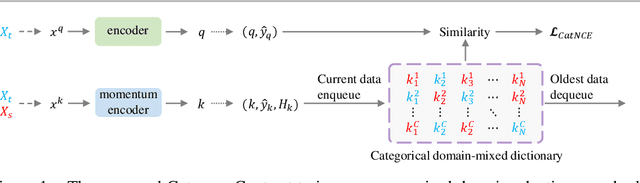
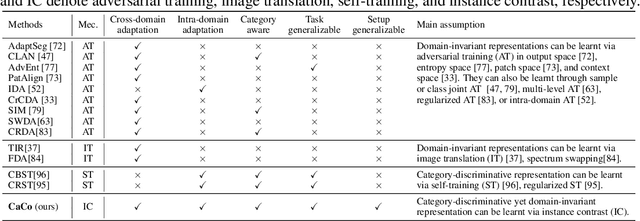
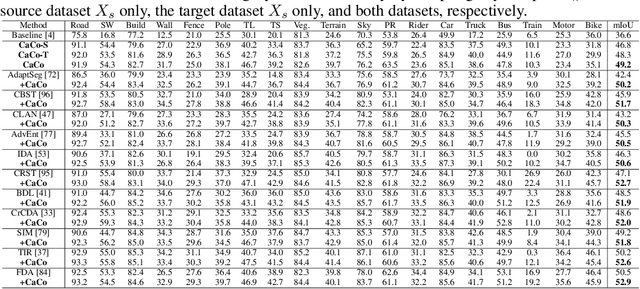
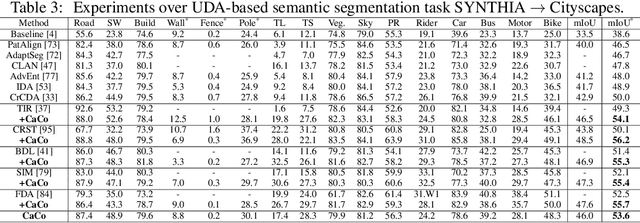
Instance contrast for unsupervised representation learning has achieved great success in recent years. In this work, we explore the idea of instance contrastive learning in unsupervised domain adaptation (UDA) and propose a novel Category Contrast technique (CaCo) that introduces semantic priors on top of instance discrimination for visual UDA tasks. By considering instance contrastive learning as a dictionary look-up operation, we construct a semantics-aware dictionary with samples from both source and target domains where each target sample is assigned a (pseudo) category label based on the category priors of source samples. This allows category contrastive learning (between target queries and the category-level dictionary) for category-discriminative yet domain-invariant feature representations: samples of the same category (from either source or target domain) are pulled closer while those of different categories are pushed apart simultaneously. Extensive UDA experiments in multiple visual tasks ($e.g.$, segmentation, classification and detection) show that the simple implementation of CaCo achieves superior performance as compared with the highly-optimized state-of-the-art methods. Analytically and empirically, the experiments also demonstrate that CaCo is complementary to existing UDA methods and generalizable to other learning setups such as semi-supervised learning, unsupervised model adaptation, etc.
RDA: Robust Domain Adaptation via Fourier Adversarial Attacking
Jun 05, 2021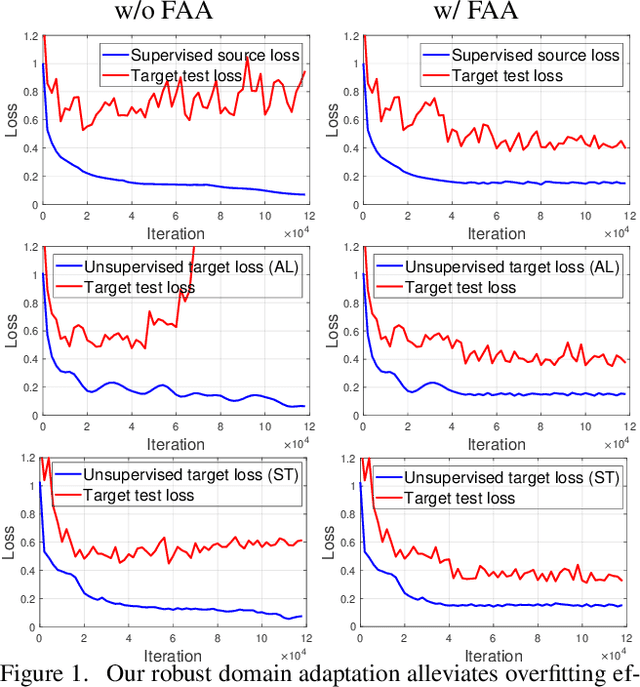
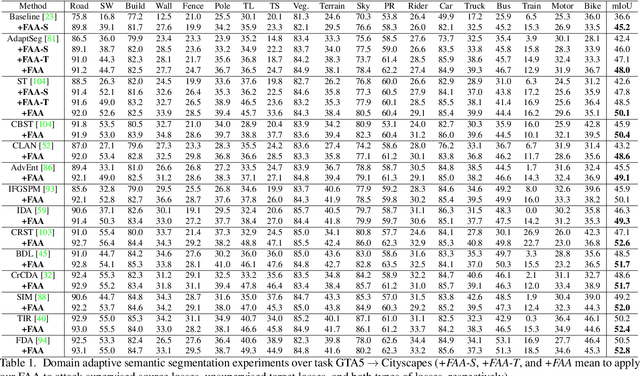
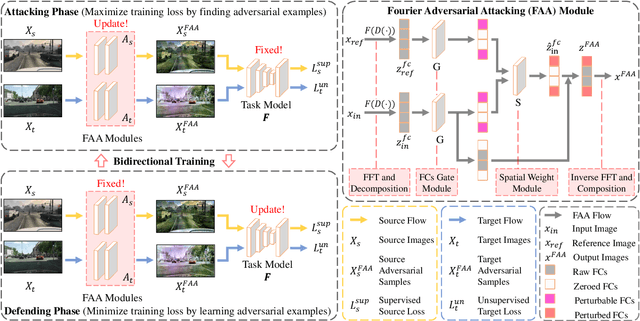
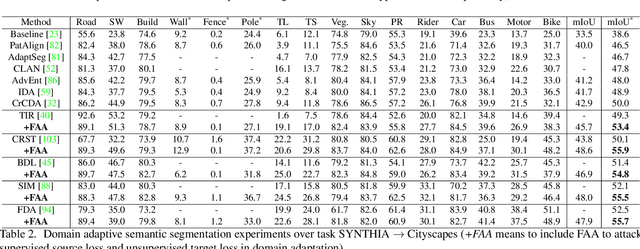
Unsupervised domain adaptation (UDA) involves a supervised loss in a labeled source domain and an unsupervised loss in an unlabeled target domain, which often faces more severe overfitting (than classical supervised learning) as the supervised source loss has clear domain gap and the unsupervised target loss is often noisy due to the lack of annotations. This paper presents RDA, a robust domain adaptation technique that introduces adversarial attacking to mitigate overfitting in UDA. We achieve robust domain adaptation by a novel Fourier adversarial attacking (FAA) method that allows large magnitude of perturbation noises but has minimal modification of image semantics, the former is critical to the effectiveness of its generated adversarial samples due to the existence of 'domain gaps'. Specifically, FAA decomposes images into multiple frequency components (FCs) and generates adversarial samples by just perturbating certain FCs that capture little semantic information. With FAA-generated samples, the training can continue the 'random walk' and drift into an area with a flat loss landscape, leading to more robust domain adaptation. Extensive experiments over multiple domain adaptation tasks show that RDA can work with different computer vision tasks with superior performance.
Semi-Supervised Domain Adaptation via Adaptive and Progressive Feature Alignment
Jun 05, 2021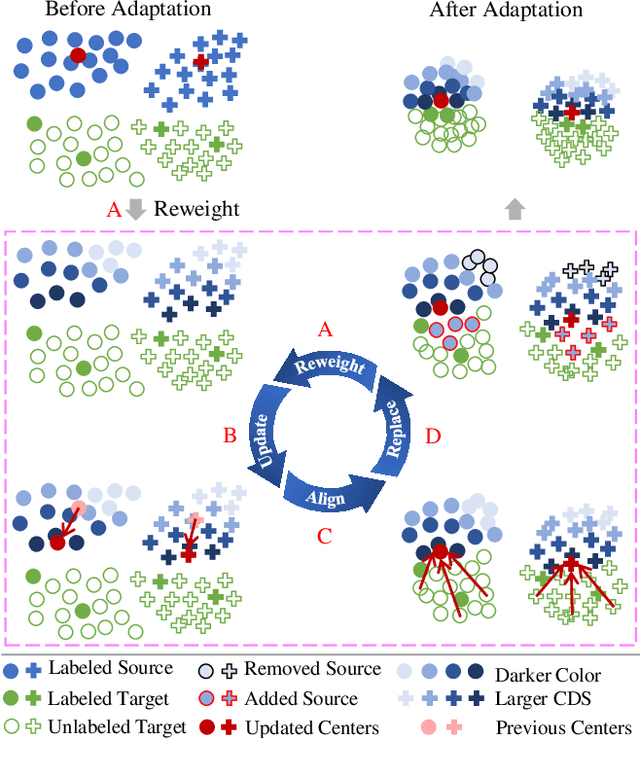
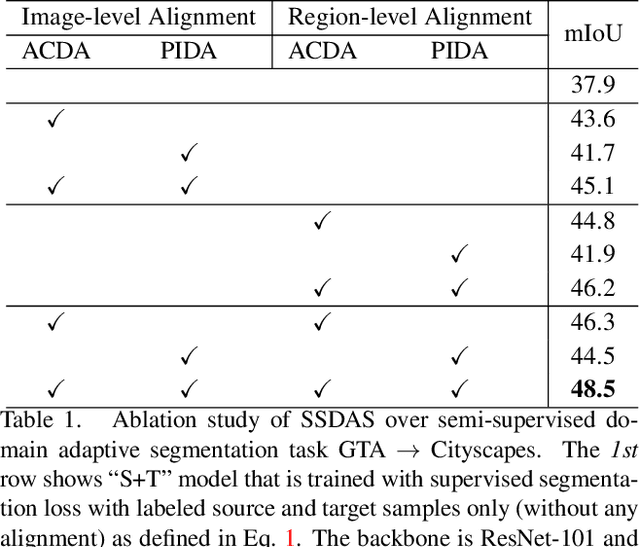
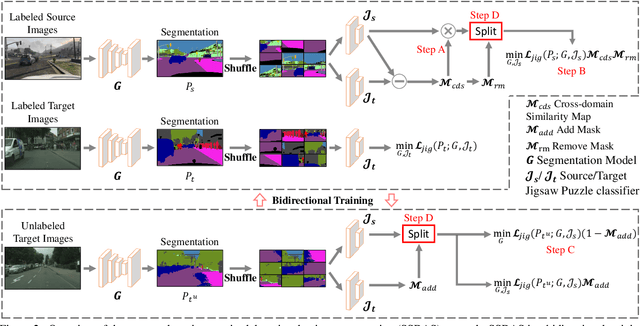
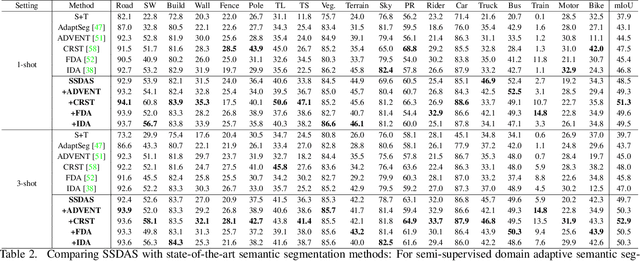
Contemporary domain adaptive semantic segmentation aims to address data annotation challenges by assuming that target domains are completely unannotated. However, annotating a few target samples is usually very manageable and worthwhile especially if it improves the adaptation performance substantially. This paper presents SSDAS, a Semi-Supervised Domain Adaptive image Segmentation network that employs a few labeled target samples as anchors for adaptive and progressive feature alignment between labeled source samples and unlabeled target samples. We position the few labeled target samples as references that gauge the similarity between source and target features and guide adaptive inter-domain alignment for learning more similar source features. In addition, we replace the dissimilar source features by high-confidence target features continuously during the iterative training process, which achieves progressive intra-domain alignment between confident and unconfident target features. Extensive experiments show the proposed SSDAS greatly outperforms a number of baselines, i.e., UDA-based semantic segmentation and SSDA-based image classification. In addition, SSDAS is complementary and can be easily incorporated into UDA-based methods with consistent improvements in domain adaptive semantic segmentation.
MLAN: Multi-Level Adversarial Network for Domain Adaptive Semantic Segmentation
Mar 24, 2021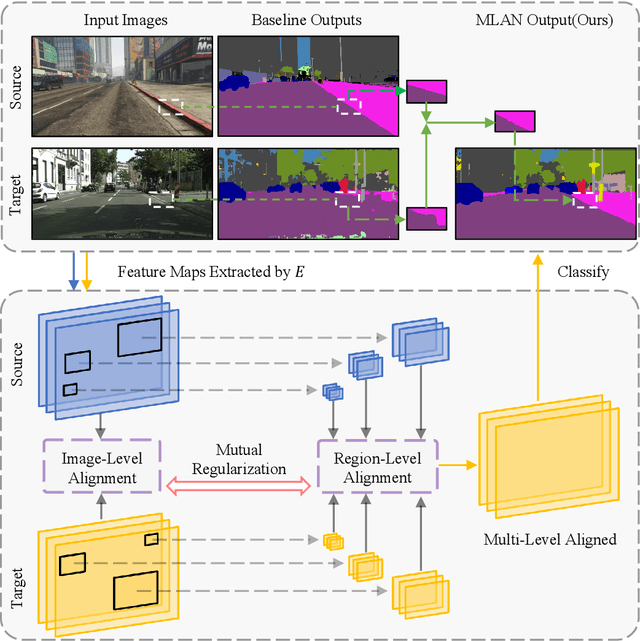

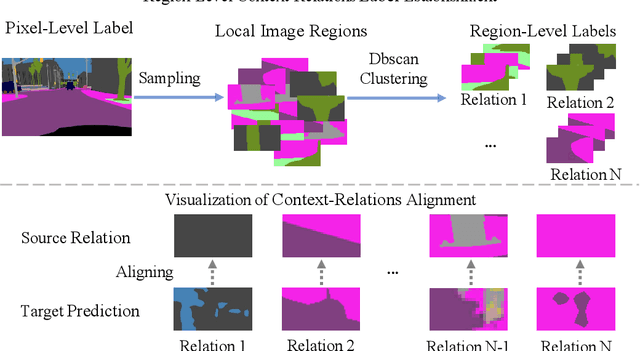

Recent progresses in domain adaptive semantic segmentation demonstrate the effectiveness of adversarial learning (AL) in unsupervised domain adaptation. However, most adversarial learning based methods align source and target distributions at a global image level but neglect the inconsistency around local image regions. This paper presents a novel multi-level adversarial network (MLAN) that aims to address inter-domain inconsistency at both global image level and local region level optimally. MLAN has two novel designs, namely, region-level adversarial learning (RL-AL) and co-regularized adversarial learning (CR-AL). Specifically, RL-AL models prototypical regional context-relations explicitly in the feature space of a labelled source domain and transfers them to an unlabelled target domain via adversarial learning. CR-AL fuses region-level AL and image-level AL optimally via mutual regularization. In addition, we design a multi-level consistency map that can guide domain adaptation in both input space ($i.e.$, image-to-image translation) and output space ($i.e.$, self-training) effectively. Extensive experiments show that MLAN outperforms the state-of-the-art with a large margin consistently across multiple datasets.
Cross-View Regularization for Domain Adaptive Panoptic Segmentation
Mar 03, 2021

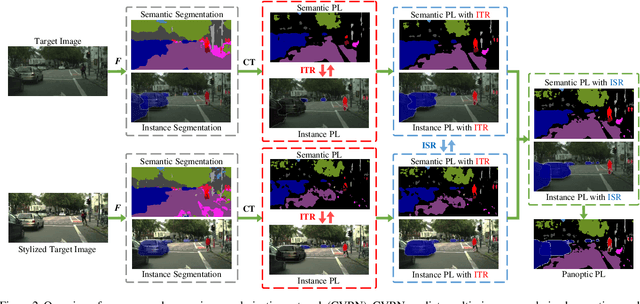
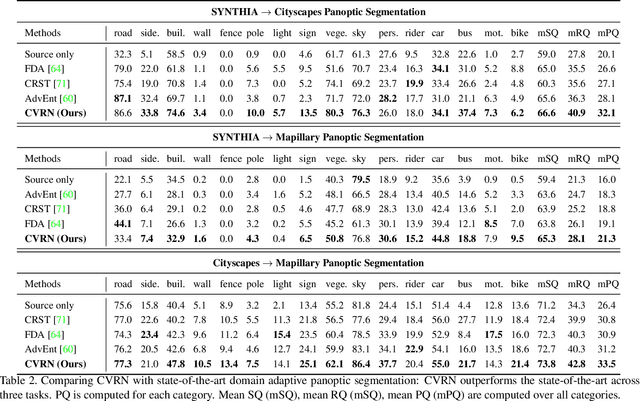
Panoptic segmentation unifies semantic segmentation and instance segmentation which has been attracting increasing attention in recent years. However, most existing research was conducted under a supervised learning setup whereas unsupervised domain adaptive panoptic segmentation which is critical in different tasks and applications is largely neglected. We design a domain adaptive panoptic segmentation network that exploits inter-style consistency and inter-task regularization for optimal domain adaptive panoptic segmentation. The inter-style consistency leverages geometric invariance across the same image of the different styles which fabricates certain self-supervisions to guide the network to learn domain-invariant features. The inter-task regularization exploits the complementary nature of instance segmentation and semantic segmentation and uses it as a constraint for better feature alignment across domains. Extensive experiments over multiple domain adaptive panoptic segmentation tasks (e.g., synthetic-to-real and real-to-real) show that our proposed network achieves superior segmentation performance as compared with the state-of-the-art.
FSDR: Frequency Space Domain Randomization for Domain Generalization
Mar 03, 2021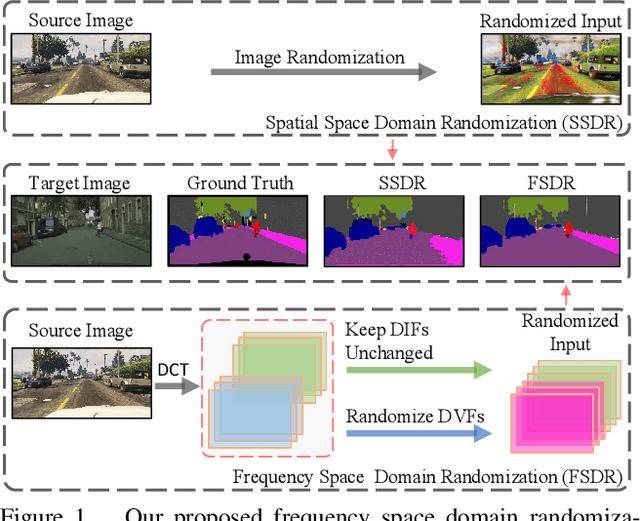


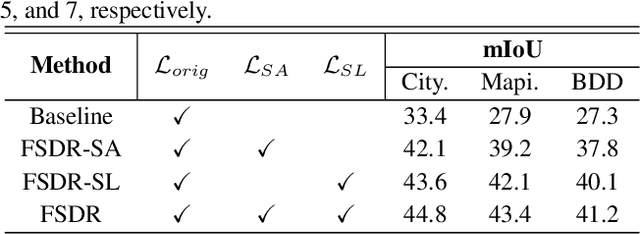
Domain generalization aims to learn a generalizable model from a known source domain for various unknown target domains. It has been studied widely by domain randomization that transfers source images to different styles in spatial space for learning domain-agnostic features. However, most existing randomization uses GANs that often lack of controls and even alter semantic structures of images undesirably. Inspired by the idea of JPEG that converts spatial images into multiple frequency components (FCs), we propose Frequency Space Domain Randomization (FSDR) that randomizes images in frequency space by keeping domain-invariant FCs (DIFs) and randomizing domain-variant FCs (DVFs) only. FSDR has two unique features: 1) it decomposes images into DIFs and DVFs which allows explicit access and manipulation of them and more controllable randomization; 2) it has minimal effects on semantic structures of images and domain-invariant features. We examined domain variance and invariance property of FCs statistically and designed a network that can identify and fuse DIFs and DVFs dynamically through iterative learning. Extensive experiments over multiple domain generalizable segmentation tasks show that FSDR achieves superior segmentation and its performance is even on par with domain adaptation methods that access target data in training.
FPS-Net: A Convolutional Fusion Network for Large-Scale LiDAR Point Cloud Segmentation
Mar 01, 2021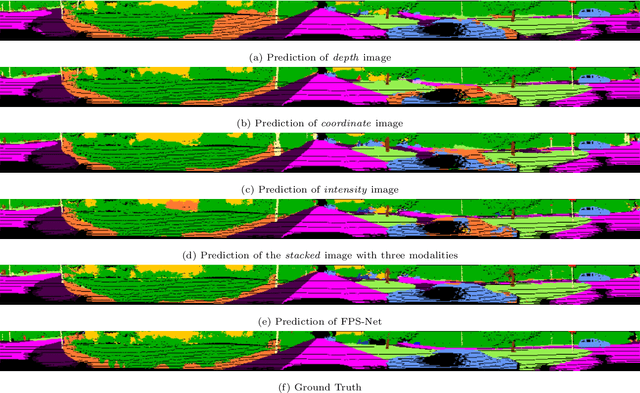
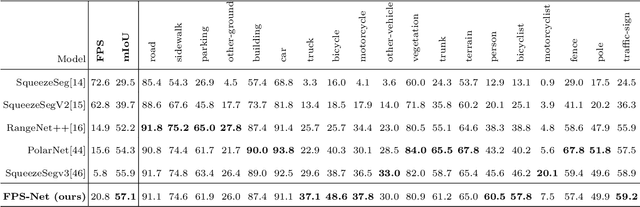
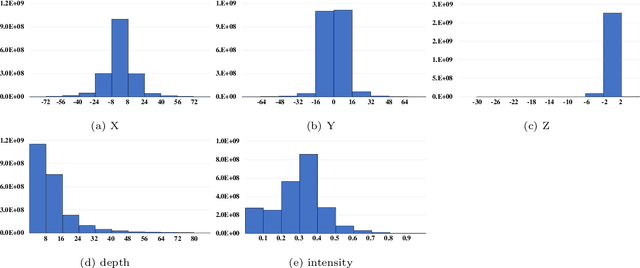
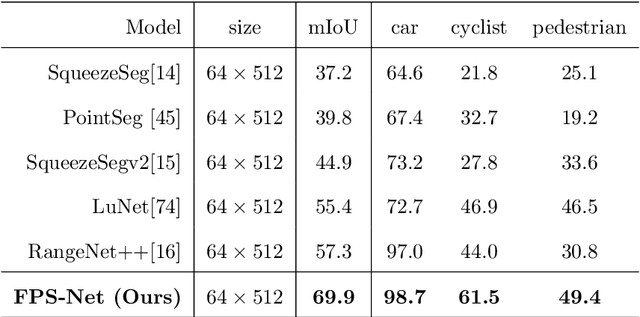
Scene understanding based on LiDAR point cloud is an essential task for autonomous cars to drive safely, which often employs spherical projection to map 3D point cloud into multi-channel 2D images for semantic segmentation. Most existing methods simply stack different point attributes/modalities (e.g. coordinates, intensity, depth, etc.) as image channels to increase information capacity, but ignore distinct characteristics of point attributes in different image channels. We design FPS-Net, a convolutional fusion network that exploits the uniqueness and discrepancy among the projected image channels for optimal point cloud segmentation. FPS-Net adopts an encoder-decoder structure. Instead of simply stacking multiple channel images as a single input, we group them into different modalities to first learn modality-specific features separately and then map the learned features into a common high-dimensional feature space for pixel-level fusion and learning. Specifically, we design a residual dense block with multiple receptive fields as a building block in the encoder which preserves detailed information in each modality and learns hierarchical modality-specific and fused features effectively. In the FPS-Net decoder, we use a recurrent convolution block likewise to hierarchically decode fused features into output space for pixel-level classification. Extensive experiments conducted on two widely adopted point cloud datasets show that FPS-Net achieves superior semantic segmentation as compared with state-of-the-art projection-based methods. In addition, the proposed modality fusion idea is compatible with typical projection-based methods and can be incorporated into them with consistent performance improvements.