 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Player Tracking in Ice Hockey with Homographic Projections
May 22, 2024Multi Object Tracking (MOT) in ice hockey pursues the combined task of localizing and associating players across a given sequence to maintain their identities. Tracking players from monocular broadcast feeds is an important computer vision problem offering various downstream analytics and enhanced viewership experience. However, existing trackers encounter significant difficulties in dealing with occlusions, blurs, and agile player movements prevalent in telecast feeds. In this work, we propose a novel tracking approach by formulating MOT as a bipartite graph matching problem infused with homography. We disentangle the positional representations of occluded and overlapping players in broadcast view, by mapping their foot keypoints to an overhead rink template, and encode these projected positions into the graph network. This ensures reliable spatial context for consistent player tracking and unfragmented tracklet prediction. Our results show considerable improvements in both the IDsw and IDF1 metrics on the two available broadcast ice hockey datasets.
Region-level labels in ice charts can produce pixel-level segmentation for Sea Ice types
May 16, 2024



Fully supervised deep learning approaches have demonstrated impressive accuracy in sea ice classification, but their dependence on high-resolution labels presents a significant challenge due to the difficulty of obtaining such data. In response, our weakly supervised learning method provides a compelling alternative by utilizing lower-resolution regional labels from expert-annotated ice charts. This approach achieves exceptional pixel-level classification performance by introducing regional loss representations during training to measure the disparity between predicted and ice chart-derived sea ice type distributions. Leveraging the AI4Arctic Sea Ice Challenge Dataset, our method outperforms the fully supervised U-Net benchmark, the top solution of the AutoIce challenge, in both mapping resolution and class-wise accuracy, marking a significant advancement in automated operational sea ice mapping.
Evaluating deep tracking models for player tracking in broadcast ice hockey video
May 22, 2022
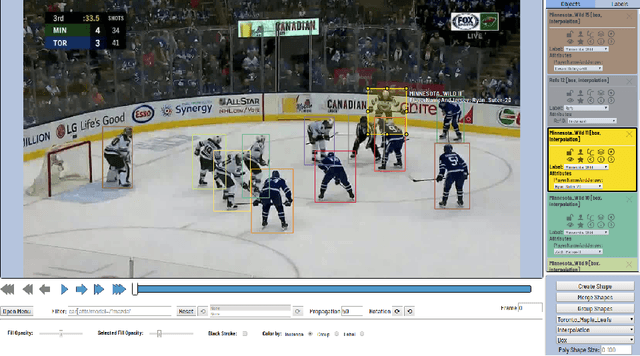

Tracking and identifying players is an important problem in computer vision based ice hockey analytics. Player tracking is a challenging problem since the motion of players in hockey is fast-paced and non-linear. There is also significant player-player and player-board occlusion, camera panning and zooming in hockey broadcast video. Prior published research perform player tracking with the help of handcrafted features for player detection and re-identification. Although commercial solutions for hockey player tracking exist, to the best of our knowledge, no network architectures used, training data or performance metrics are publicly reported. There is currently no published work for hockey player tracking making use of the recent advancements in deep learning while also reporting the current accuracy metrics used in literature. Therefore, in this paper, we compare and contrast several state-of-the-art tracking algorithms and analyze their performance and failure modes in ice hockey.
Bag of Tricks for Natural Policy Gradient Reinforcement Learning
Jan 22, 2022
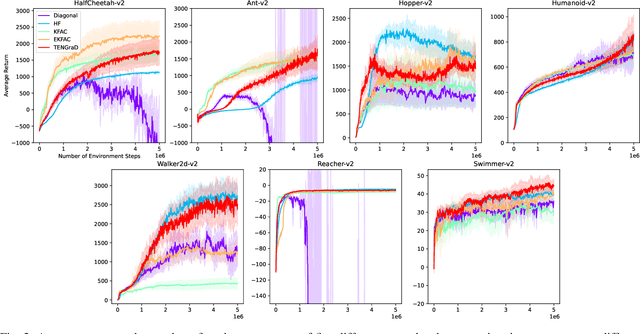

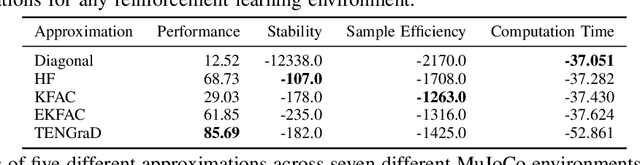
Natural policy gradient methods are popular reinforcement learning methods that improve the stability of policy gradient methods by preconditioning the gradient with the inverse of the Fisher-information matrix. However, leveraging natural policy gradient methods in an optimal manner can be very challenging as many implementation details must be set to achieve optimal performance. To the best of the authors' knowledge, there has not been a study that has investigated strategies for setting these details for natural policy gradient methods to achieve high performance in a comprehensive and systematic manner. To address this, we have implemented and compared strategies that impact performance in natural policy gradient reinforcement learning across five different second-order approximations. These include varying batch sizes and optimizing the critic network using the natural gradient. Furthermore, insights about the fundamental trade-offs when optimizing for performance (stability, sample efficiency, and computation time) were generated. Experimental results indicate that the proposed collection of strategies for performance optimization can improve results by 86% to 181% across the MuJuCo control benchmark, with TENGraD exhibiting the best approximation performance amongst the tested approximations. Code in this study is available at https://github.com/gebob19/natural-policy-gradient-reinforcement-learning.
Ice hockey player identification via transformers
Nov 22, 2021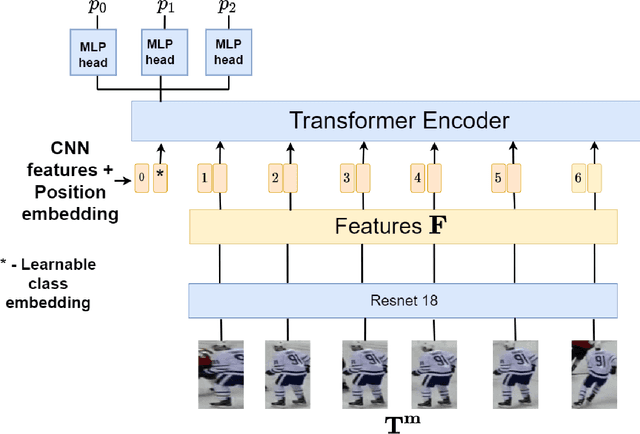
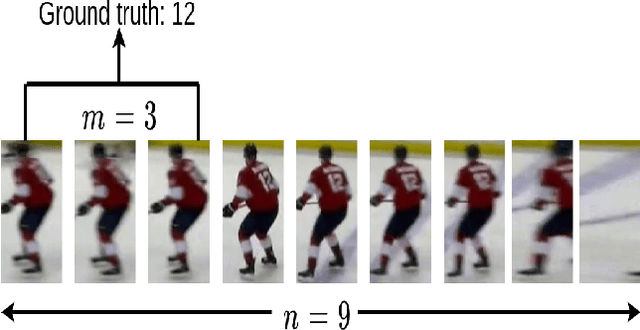
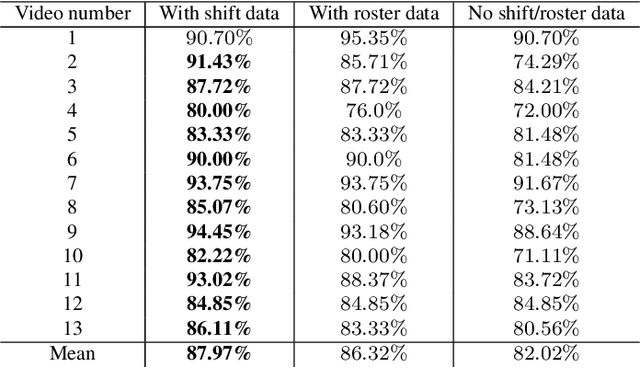
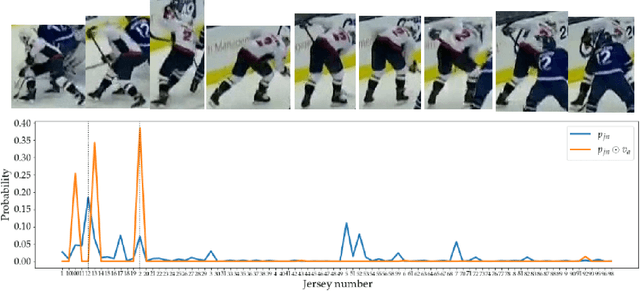
Identifying players in video is a foundational step in computer vision-based sports analytics. Obtaining player identities is essential for analyzing the game and is used in downstream tasks such as game event recognition. Transformers are the existing standard in Natural Language Processing (NLP) and are swiftly gaining traction in computer vision. Motivated by the increasing success of transformers in computer vision, in this paper, we introduce a transformer network for recognizing players through their jersey numbers in broadcast National Hockey League (NHL) videos. The transformer takes temporal sequences of player frames (also called player tracklets) as input and outputs the probabilities of jersey numbers present in the frames. The proposed network performs better than the previous benchmark on the dataset used. We implement a weakly-supervised training approach by generating approximate frame-level labels for jersey number presence and use the frame-level labels for faster training. We also utilize player shifts available in the NHL play-by-play data by reading the game time using optical character recognition (OCR) to get the players on the ice rink at a certain game time. Using player shifts improved the player identification accuracy by 6%.
M2A: Motion Aware Attention for Accurate Video Action Recognition
Nov 18, 2021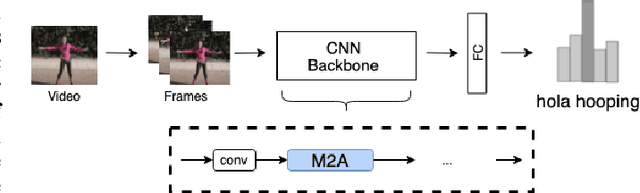
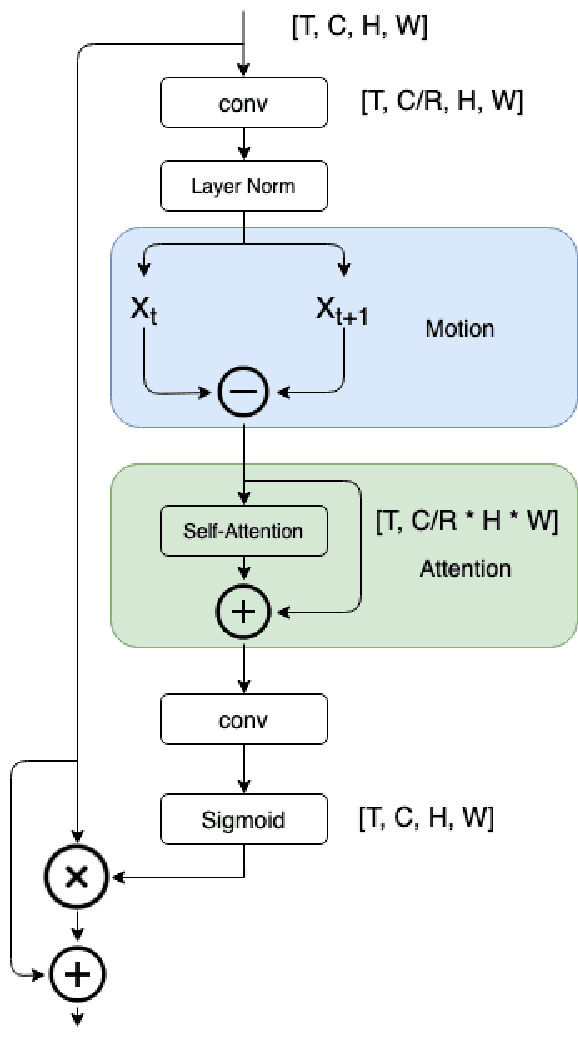


Advancements in attention mechanisms have led to significant performance improvements in a variety of areas in machine learning due to its ability to enable the dynamic modeling of temporal sequences. A particular area in computer vision that is likely to benefit greatly from the incorporation of attention mechanisms in video action recognition. However, much of the current research's focus on attention mechanisms have been on spatial and temporal attention, which are unable to take advantage of the inherent motion found in videos. Motivated by this, we develop a new attention mechanism called Motion Aware Attention (M2A) that explicitly incorporates motion characteristics. More specifically, M2A extracts motion information between consecutive frames and utilizes attention to focus on the motion patterns found across frames to accurately recognize actions in videos. The proposed M2A mechanism is simple to implement and can be easily incorporated into any neural network backbone architecture. We show that incorporating motion mechanisms with attention mechanisms using the proposed M2A mechanism can lead to a +15% to +26% improvement in top-1 accuracy across different backbone architectures, with only a small increase in computational complexity. We further compared the performance of M2A with other state-of-the-art motion and attention mechanisms on the Something-Something V1 video action recognition benchmark. Experimental results showed that M2A can lead to further improvements when combined with other temporal mechanisms and that it outperforms other motion-only or attention-only mechanisms by as much as +60% in top-1 accuracy for specific classes in the benchmark.
Player Tracking and Identification in Ice Hockey
Oct 06, 2021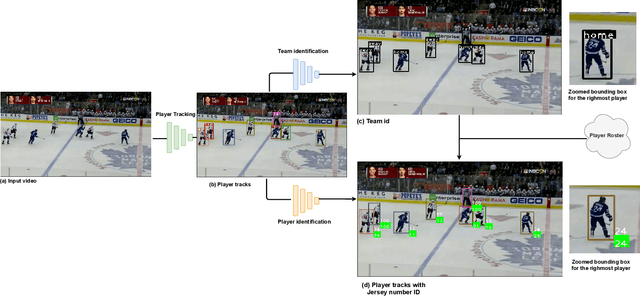
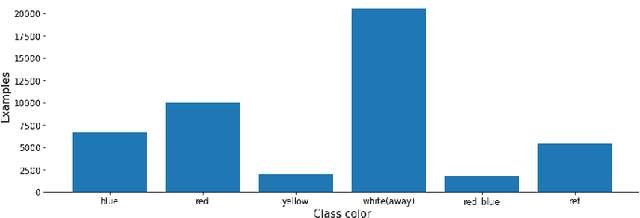
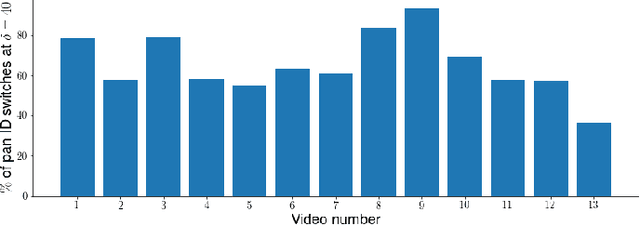
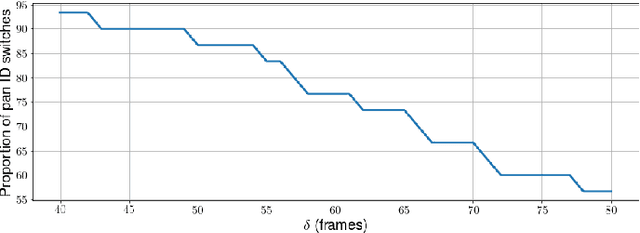
Tracking and identifying players is a fundamental step in computer vision-based ice hockey analytics. The data generated by tracking is used in many other downstream tasks, such as game event detection and game strategy analysis. Player tracking and identification is a challenging problem since the motion of players in hockey is fast-paced and non-linear when compared to pedestrians. There is also significant camera panning and zooming in hockey broadcast video. Identifying players in ice hockey is challenging since the players of the same team look almost identical, with the jersey number the only discriminating factor between players. In this paper, an automated system to track and identify players in broadcast NHL hockey videos is introduced. The system is composed of three components (1) Player tracking, (2) Team identification and (3) Player identification. Due to the absence of publicly available datasets, the datasets used to train the three components are annotated manually. Player tracking is performed with the help of a state of the art tracking algorithm obtaining a Multi-Object Tracking Accuracy (MOTA) score of 94.5%. For team identification, the away-team jerseys are grouped into a single class and home-team jerseys are grouped in classes according to their jersey color. A convolutional neural network is then trained on the team identification dataset. The team identification network gets an accuracy of 97% on the test set. A novel player identification model is introduced that utilizes a temporal one-dimensional convolutional network to identify players from player bounding box sequences. The player identification model further takes advantage of the available NHL game roster data to obtain a player identification accuracy of 83%.
Multi-task learning for jersey number recognition in Ice Hockey
Aug 17, 2021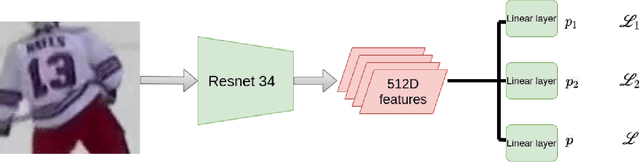

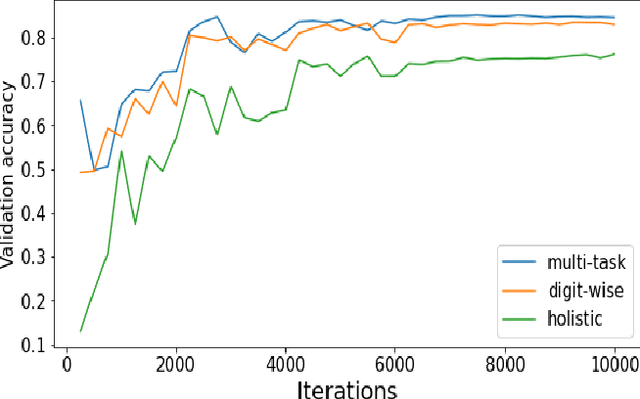

Identifying players in sports videos by recognizing their jersey numbers is a challenging task in computer vision. We have designed and implemented a multi-task learning network for jersey number recognition. In order to train a network to recognize jersey numbers, two output label representations are used (1) Holistic - considers the entire jersey number as one class, and (2) Digit-wise - considers the two digits in a jersey number as two separate classes. The proposed network learns both holistic and digit-wise representations through a multi-task loss function. We determine the optimal weights to be assigned to holistic and digit-wise losses through an ablation study. Experimental results demonstrate that the proposed multi-task learning network performs better than the constituent holistic and digit-wise single-task learning networks.
Sentinel-1 Additive Noise Removal from Cross-Polarization Extra-Wide TOPSAR with Dynamic Least-Squares
Jul 12, 2021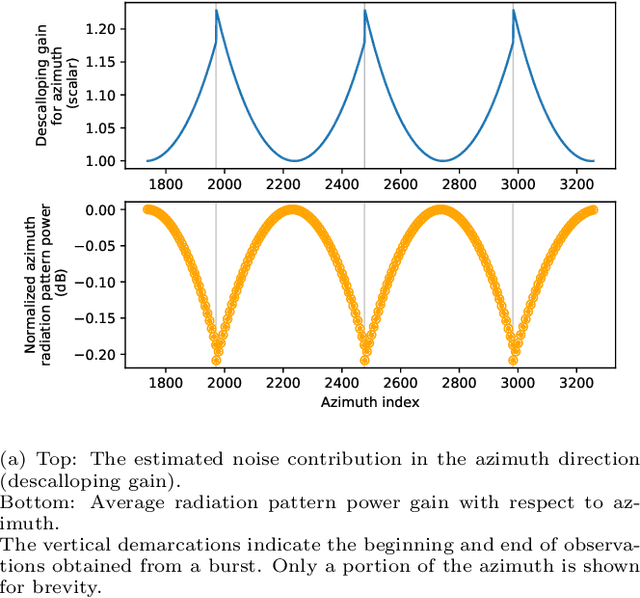



Sentinel-1 is a synthetic aperture radar (SAR) platform with an operational mode called extra wide (EW) that offers large regions of ocean areas to be observed. A major issue with EW images is that the cross-polarized HV and VH channels have prominent additive noise patterns relative to low backscatter intensity, which disrupts tasks that require manual or automated interpretation. The European Space Agency (ESA) provides a method for removing the additive noise pattern by means of lookup tables, but applying them directly produces unsatisfactory results because characteristics of the noise still remain. Furthermore, evidence suggests that the magnitude of the additive noise dynamically depends on factors that are not considered by the ESA estimated noise field. To address these issues we propose a quadratic objective function to model the mis-scale of the provided noise field on an image. We consider a linear denoising model that re-scales the noise field for each subswath, whose parameters are found from a least-squares solution over the objective function. This method greatly reduces the presence of additive noise while not requiring a set of training images, is robust to heterogeneity in images, dynamically estimates parameters for each image, and finds parameters using a closed-form solution. Two experiments were performed to validate the proposed method. The first experiment simulated noise removal on a set of RADARSAT-2 images with noise fields artificially imposed on them. The second experiment conducted noise removal on a set of Sentinel-1 images taken over the five oceans. Afterwards, quality of the noise removal was evaluated based on the appearance of open-water. The two experiments indicate that the proposed method marks an improvement both visually and through numerical measures.
* 22 pages, 14 figures
Puck localization and multi-task event recognition in broadcast hockey videos
May 21, 2021

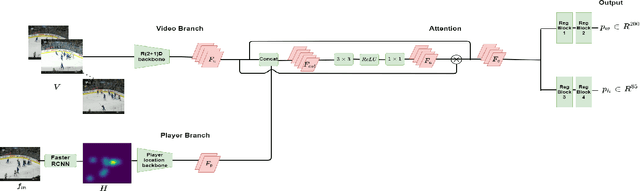

Puck localization is an important problem in ice hockey video analytics useful for analyzing the game, determining play location, and assessing puck possession. The problem is challenging due to the small size of the puck, excessive motion blur due to high puck velocity and occlusions due to players and boards. In this paper, we introduce and implement a network for puck localization in broadcast hockey video. The network leverages expert NHL play-by-play annotations and uses temporal context to locate the puck. Player locations are incorporated into the network through an attention mechanism by encoding player positions with a Gaussian-based spatial heatmap drawn at player positions. Since event occurrence on the rink and puck location are related, we also perform event recognition by augmenting the puck localization network with an event recognition head and training the network through multi-task learning. Experimental results demonstrate that the network is able to localize the puck with an AUC of $73.1 \%$ on the test set. The puck location can be inferred in 720p broadcast videos at $5$ frames per second. It is also demonstrated that multi-task learning with puck location improves event recognition accuracy.