 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAL: Proxy-Guided Black-Box Attack on Large Language Models
Feb 15, 2024



Large Language Models (LLMs) have surged in popularity in recent months, but they have demonstrated concerning capabilities to generate harmful content when manipulated. While techniques like safety fine-tuning aim to minimize harmful use, recent works have shown that LLMs remain vulnerable to attacks that elicit toxic responses. In this work, we introduce the Proxy-Guided Attack on LLMs (PAL), the first optimization-based attack on LLMs in a black-box query-only setting. In particular, it relies on a surrogate model to guide the optimization and a sophisticated loss designed for real-world LLM APIs. Our attack achieves 84% attack success rate (ASR) on GPT-3.5-Turbo and 48% on Llama-2-7B, compared to 4% for the current state of the art. We also propose GCG++, an improvement to the GCG attack that reaches 94% ASR on white-box Llama-2-7B, and the Random-Search Attack on LLMs (RAL), a strong but simple baseline for query-based attacks. We believe the techniques proposed in this work will enable more comprehensive safety testing of LLMs and, in the long term, the development of better security guardrails. The code can be found at https://github.com/chawins/pal.
Jatmo: Prompt Injection Defense by Task-Specific Finetuning
Jan 08, 2024



Large Language Models (LLMs) are attracting significant research attention due to their instruction-following abilities, allowing users and developers to leverage LLMs for a variety of tasks. However, LLMs are vulnerable to prompt-injection attacks: a class of attacks that hijack the model's instruction-following abilities, changing responses to prompts to undesired, possibly malicious ones. In this work, we introduce Jatmo, a method for generating task-specific models resilient to prompt-injection attacks. Jatmo leverages the fact that LLMs can only follow instructions once they have undergone instruction tuning. It harnesses a teacher instruction-tuned model to generate a task-specific dataset, which is then used to fine-tune a base model (i.e., a non-instruction-tuned model). Jatmo only needs a task prompt and a dataset of inputs for the task: it uses the teacher model to generate outputs. For situations with no pre-existing datasets, Jatmo can use a single example, or in some cases none at all, to produce a fully synthetic dataset. Our experiments on seven tasks show that Jatmo models provide similar quality of outputs on their specific task as standard LLMs, while being resilient to prompt injections. The best attacks succeeded in less than 0.5% of cases against our models, versus 87% success rate against GPT-3.5-Turbo. We release Jatmo at https://github.com/wagner-group/prompt-injection-defense.
Mark My Words: Analyzing and Evaluating Language Model Watermarks
Dec 07, 2023



The capabilities of large language models have grown significantly in recent years and so too have concerns about their misuse. In this context, the ability to distinguish machine-generated text from human-authored content becomes important. Prior works have proposed numerous schemes to watermark text, which would benefit from a systematic evaluation framework. This work focuses on text watermarking techniques - as opposed to image watermarks - and proposes MARKMYWORDS, a comprehensive benchmark for them under different tasks as well as practical attacks. We focus on three main metrics: quality, size (e.g. the number of tokens needed to detect a watermark), and tamper-resistance. Current watermarking techniques are good enough to be deployed: Kirchenbauer et al. [1] can watermark Llama2-7B-chat with no perceivable loss in quality, the watermark can be detected with fewer than 100 tokens, and the scheme offers good tamper-resistance to simple attacks. We argue that watermark indistinguishability, a criteria emphasized in some prior works, is too strong a requirement: schemes that slightly modify logit distributions outperform their indistinguishable counterparts with no noticeable loss in generation quality. We publicly release our benchmark (https://github.com/wagner-group/MarkMyWords)
Can LLMs Follow Simple Rules?
Nov 06, 2023



As Large Language Models (LLMs) are deployed with increasing real-world responsibilities, it is important to be able to specify and constrain the behavior of these systems in a reliable manner. Model developers may wish to set explicit rules for the model, such as "do not generate abusive content", but these may be circumvented by jailbreaking techniques. Evaluating how well LLMs follow developer-provided rules in the face of adversarial inputs typically requires manual review, which slows down monitoring and methods development. To address this issue, we propose Rule-following Language Evaluation Scenarios (RuLES), a programmatic framework for measuring rule-following ability in LLMs. RuLES consists of 15 simple text scenarios in which the model is instructed to obey a set of rules in natural language while interacting with the human user. Each scenario has a concise evaluation program to determine whether the model has broken any rules in a conversation. Through manual exploration of model behavior in our scenarios, we identify 6 categories of attack strategies and collect two suites of test cases: one consisting of unique conversations from manual testing and one that systematically implements strategies from the 6 categories. Across various popular proprietary and open models such as GPT-4 and Llama 2, we find that all models are susceptible to a wide variety of adversarial hand-crafted user inputs, though GPT-4 is the best-performing model. Additionally, we evaluate open models under gradient-based attacks and find significant vulnerabilities. We propose RuLES as a challenging new setting for research into exploring and defending against both manual and automatic attacks on LLMs.
Defending Against Transfer Attacks From Public Models
Oct 26, 2023Adversarial attacks have been a looming and unaddressed threat in the industry. However, through a decade-long history of the robustness evaluation literature, we have learned that mounting a strong or optimal attack is challenging. It requires both machine learning and domain expertise. In other words, the white-box threat model, religiously assumed by a large majority of the past literature, is unrealistic. In this paper, we propose a new practical threat model where the adversary relies on transfer attacks through publicly available surrogate models. We argue that this setting will become the most prevalent for security-sensitive applications in the future. We evaluate the transfer attacks in this setting and propose a specialized defense method based on a game-theoretic perspective. The defenses are evaluated under 24 public models and 11 attack algorithms across three datasets (CIFAR-10, CIFAR-100, and ImageNet). Under this threat model, our defense, PubDef, outperforms the state-of-the-art white-box adversarial training by a large margin with almost no loss in the normal accuracy. For instance, on ImageNet, our defense achieves 62% accuracy under the strongest transfer attack vs only 36% of the best adversarially trained model. Its accuracy when not under attack is only 2% lower than that of an undefended model (78% vs 80%). We release our code at https://github.com/wagner-group/pubdef.
DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection
Apr 01, 2023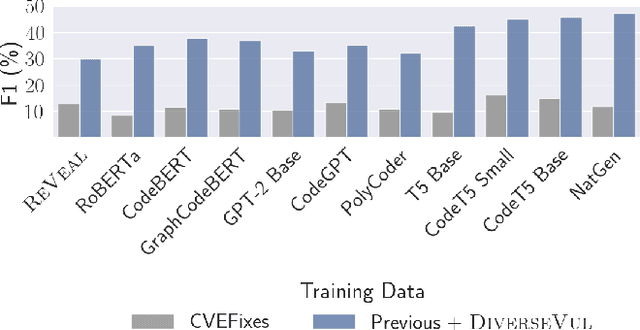
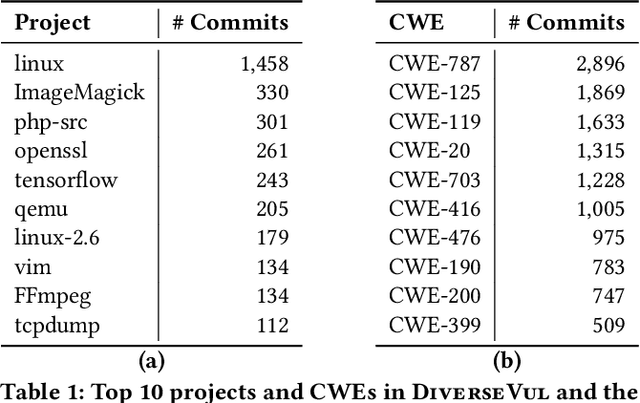
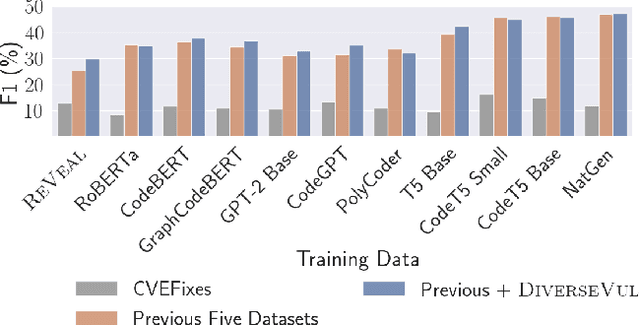
We propose and release a new vulnerable source code dataset. We curate the dataset by crawling security issue websites, extracting vulnerability-fixing commits and source codes from the corresponding projects. Our new dataset contains 150 CWEs, 26,635 vulnerable functions, and 352,606 non-vulnerable functions extracted from 7,861 commits. Our dataset covers 305 more projects than all previous datasets combined. We show that increasing the diversity and volume of training data improves the performance of deep learning models for vulnerability detection. Combining our new dataset with previous datasets, we present an analysis of the challenges and promising research directions of using deep learning for detecting software vulnerabilities. We study 11 model architectures belonging to 4 families. Our results show that deep learning is still not ready for vulnerability detection, due to high false positive rate, low F1 score, and difficulty of detecting hard CWEs. In particular, we demonstrate an important generalization challenge for the deployment of deep learning-based models. However, we also identify hopeful future research directions. We demonstrate that large language models (LLMs) are the future for vulnerability detection, outperforming Graph Neural Networks (GNNs) with manual feature engineering. Moreover, developing source code specific pre-training objectives is a promising research direction to improve the vulnerability detection performance.
Continuous Learning for Android Malware Detection
Feb 08, 2023



Machine learning methods can detect Android malware with very high accuracy. However, these classifiers have an Achilles heel, concept drift: they rapidly become out of date and ineffective, due to the evolution of malware apps and benign apps. Our research finds that, after training an Android malware classifier on one year's worth of data, the F1 score quickly dropped from 0.99 to 0.76 after 6 months of deployment on new test samples. In this paper, we propose new methods to combat the concept drift problem of Android malware classifiers. Since machine learning technique needs to be continuously deployed, we use active learning: we select new samples for analysts to label, and then add the labeled samples to the training set to retrain the classifier. Our key idea is, similarity-based uncertainty is more robust against concept drift. Therefore, we combine contrastive learning with active learning. We propose a new hierarchical contrastive learning scheme, and a new sample selection technique to continuously train the Android malware classifier. Our evaluation shows that this leads to significant improvements, compared to previously published methods for active learning. Our approach reduces the false negative rate from 16% (for the best baseline) to 10%, while maintaining the same false positive rate (0.6%). Also, our approach maintains more consistent performance across a seven-year time period than past methods.
REAP: A Large-Scale Realistic Adversarial Patch Benchmark
Dec 12, 2022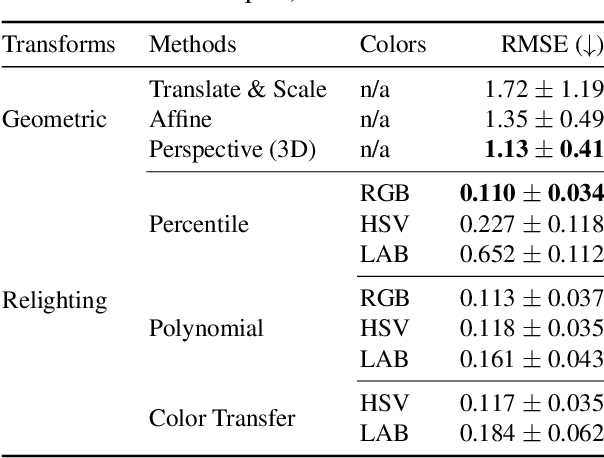
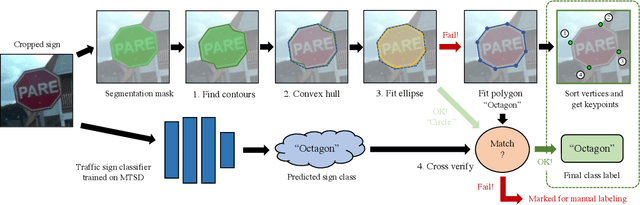
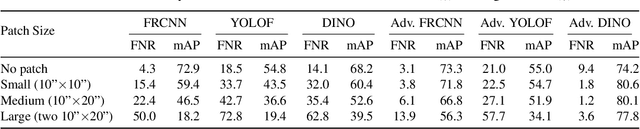
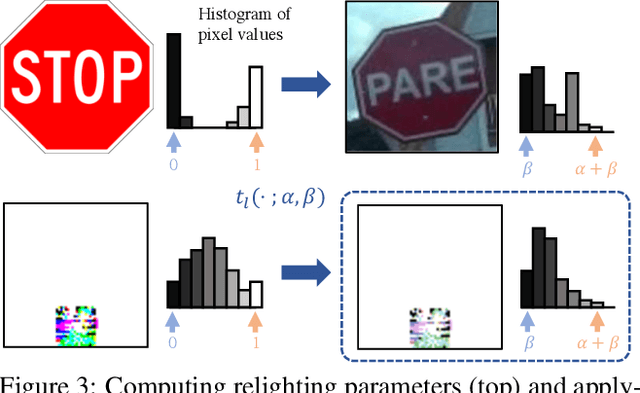
Machine learning models are known to be susceptible to adversarial perturbation. One famous attack is the adversarial patch, a sticker with a particularly crafted pattern that makes the model incorrectly predict the object it is placed on. This attack presents a critical threat to cyber-physical systems that rely on cameras such as autonomous cars. Despite the significance of the problem, conducting research in this setting has been difficult; evaluating attacks and defenses in the real world is exceptionally costly while synthetic data are unrealistic. In this work, we propose the REAP (REalistic Adversarial Patch) benchmark, a digital benchmark that allows the user to evaluate patch attacks on real images, and under real-world conditions. Built on top of the Mapillary Vistas dataset, our benchmark contains over 14,000 traffic signs. Each sign is augmented with a pair of geometric and lighting transformations, which can be used to apply a digitally generated patch realistically onto the sign. Using our benchmark, we perform the first large-scale assessments of adversarial patch attacks under realistic conditions. Our experiments suggest that adversarial patch attacks may present a smaller threat than previously believed and that the success rate of an attack on simpler digital simulations is not predictive of its actual effectiveness in practice. We release our benchmark publicly at https://github.com/wagner-group/reap-benchmark.
Part-Based Models Improve Adversarial Robustness
Sep 15, 2022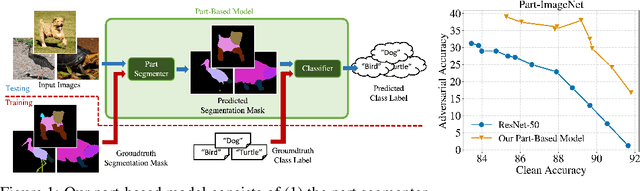
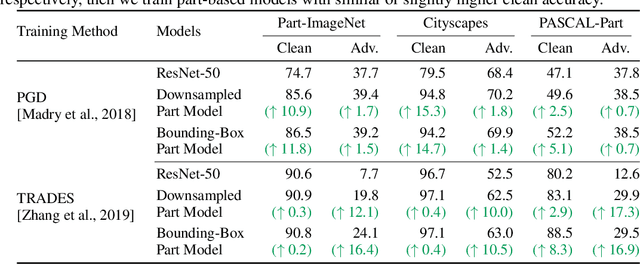

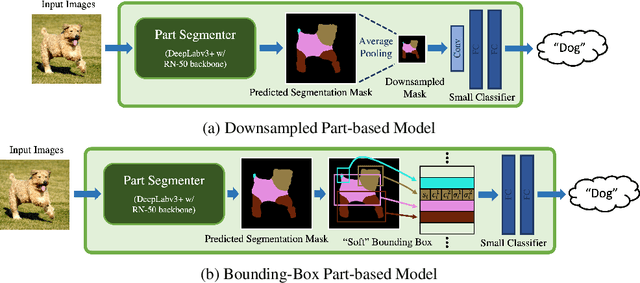
We show that combining human prior knowledge with end-to-end learning can improve the robustness of deep neural networks by introducing a part-based model for object classification. We believe that the richer form of annotation helps guide neural networks to learn more robust features without requiring more samples or larger models. Our model combines a part segmentation model with a tiny classifier and is trained end-to-end to simultaneously segment objects into parts and then classify the segmented object. Empirically, our part-based models achieve both higher accuracy and higher adversarial robustness than a ResNet-50 baseline on all three datasets. For instance, the clean accuracy of our part models is up to 15 percentage points higher than the baseline's, given the same level of robustness. Our experiments indicate that these models also reduce texture bias and yield better robustness against common corruptions and spurious correlations. The code is publicly available at https://github.com/chawins/adv-part-model.
SLIP: Self-supervision meets Language-Image Pre-training
Dec 23, 2021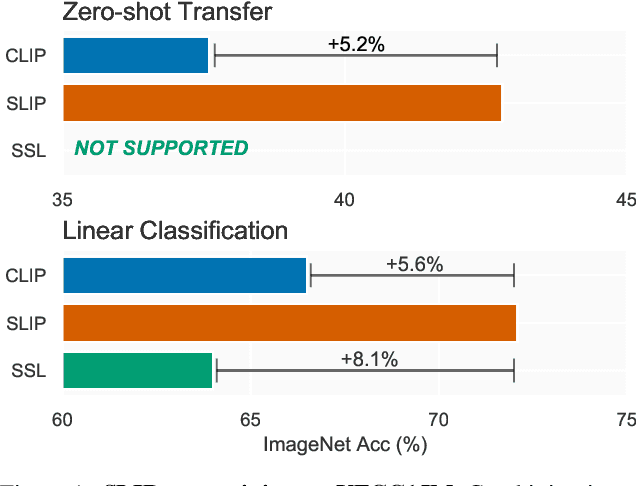
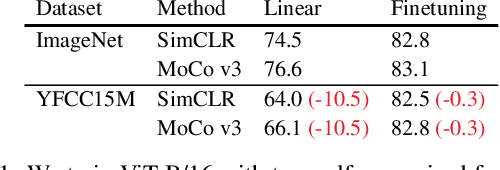
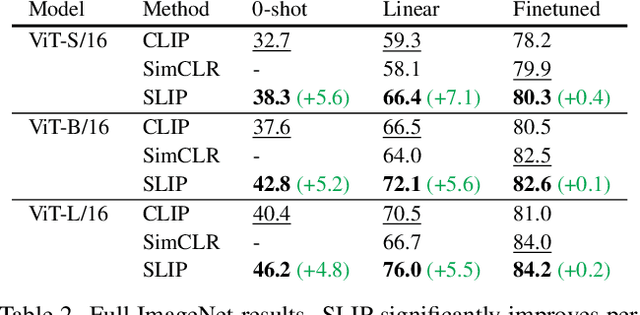
Recent work has shown that self-supervised pre-training leads to improvements over supervised learning on challenging visual recognition tasks. CLIP, an exciting new approach to learning with language supervision, demonstrates promising performance on a wide variety of benchmarks. In this work, we explore whether self-supervised learning can aid in the use of language supervision for visual representation learning. We introduce SLIP, a multi-task learning framework for combining self-supervised learning and CLIP pre-training. After pre-training with Vision Transformers, we thoroughly evaluate representation quality and compare performance to both CLIP and self-supervised learning under three distinct settings: zero-shot transfer, linear classification, and end-to-end finetuning. Across ImageNet and a battery of additional datasets, we find that SLIP improves accuracy by a large margin. We validate our results further with experiments on different model sizes, training schedules, and pre-training datasets. Our findings show that SLIP enjoys the best of both worlds: better performance than self-supervision (+8.1% linear accuracy) and language supervision (+5.2% zero-shot accuracy).