 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity
May 22, 2023



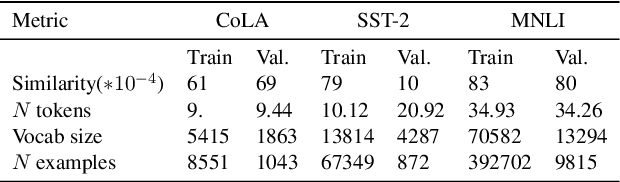
Pretraining is the preliminary and fundamental step in developing capable language models (LM). Despite this, pretraining data design is critically under-documented and often guided by empirically unsupported intuitions. To address this, we pretrain 28 1.5B parameter decoder-only models, training on data curated (1) at different times, (2) with varying toxicity and quality filters, and (3) with different domain compositions. First, we quantify the effect of pretraining data age. A temporal shift between evaluation data and pretraining data leads to performance degradation, which is not overcome by finetuning. Second, we explore the effect of quality and toxicity filters, showing a trade-off between performance on standard benchmarks and risk of toxic generations. Our findings indicate there does not exist a one-size-fits-all solution to filtering training data. We also find that the effects of different types of filtering are not predictable from text domain characteristics. Lastly, we empirically validate that the inclusion of heterogeneous data sources, like books and web, is broadly beneficial and warrants greater prioritization. These findings constitute the largest set of experiments to validate, quantify, and expose many undocumented intuitions about text pretraining, which we hope will help support more informed data-centric decisions in LM development.
Sensemaking About Contraceptive Methods Across Online Platforms
Jan 23, 2023Selecting a birth control method is a complex healthcare decision. While birth control methods provide important benefits, they can also cause unpredictable side effects and be stigmatized, leading many people to seek additional information online, where they can find reviews, advice, hypotheses, and experiences of other birth control users. However, the relationships between their healthcare concerns, sensemaking activities, and online settings are not well understood. We gather texts about birth control shared on Twitter, Reddit, and WebMD -- platforms with different affordances, moderation, and audiences -- to study where and how birth control is discussed online. Using a combination of topic modeling and hand annotation, we identify and characterize the dominant sensemaking practices across these platforms, and we create lexicons to draw comparisons across birth control methods and side effects. We use these to measure variations from survey reports of side effect experiences and method usage. Our findings characterize how online platforms are used to make sense of difficult healthcare choices and highlight unmet needs of birth control users.
Breaking BERT: Evaluating and Optimizing Sparsified Attention
Oct 07, 2022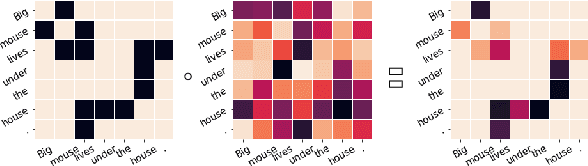


Transformers allow attention between all pairs of tokens, but there is reason to believe that most of these connections - and their quadratic time and memory - may not be necessary. But which ones? We evaluate the impact of sparsification patterns with a series of ablation experiments. First, we compare masks based on syntax, lexical similarity, and token position to random connections, and measure which patterns reduce performance the least. We find that on three common finetuning tasks even using attention that is at least 78% sparse can have little effect on performance if applied at later transformer layers, but that applying sparsity throughout the network reduces performance significantly. Second, we vary the degree of sparsity for three patterns supported by previous work, and find that connections to neighbouring tokens are the most significant. Finally, we treat sparsity as an optimizable parameter, and present an algorithm to learn degrees of neighboring connections that gives a fine-grained control over the accuracy-sparsity trade-off while approaching the performance of existing methods.
Honest Students from Untrusted Teachers: Learning an Interpretable Question-Answering Pipeline from a Pretrained Language Model
Oct 05, 2022
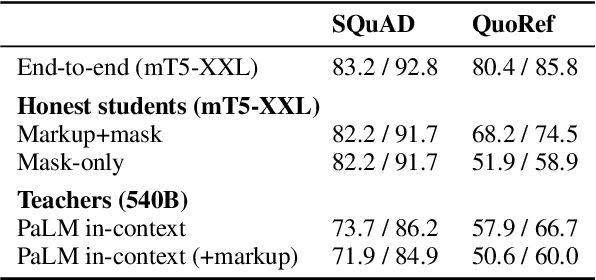


Explainable question answering systems should produce not only accurate answers but also rationales that justify their reasoning and allow humans to check their work. But what sorts of rationales are useful and how can we train systems to produce them? We propose a new style of rationale for open-book question answering, called \emph{markup-and-mask}, which combines aspects of extractive and free-text explanations. In the markup phase, the passage is augmented with free-text markup that enables each sentence to stand on its own outside the discourse context. In the masking phase, a sub-span of the marked-up passage is selected. To train a system to produce markup-and-mask rationales without annotations, we leverage in-context learning. Specifically, we generate silver annotated data by sending a series of prompts to a frozen pretrained language model, which acts as a teacher. We then fine-tune a smaller student model by training on the subset of rationales that led to correct answers. The student is "honest" in the sense that it is a pipeline: the rationale acts as a bottleneck between the passage and the answer, while the "untrusted" teacher operates under no such constraints. Thus, we offer a new way to build trustworthy pipeline systems from a combination of end-task annotations and frozen pretrained language models.
On-the-Fly Rectification for Robust Large-Vocabulary Topic Inference
Nov 12, 2021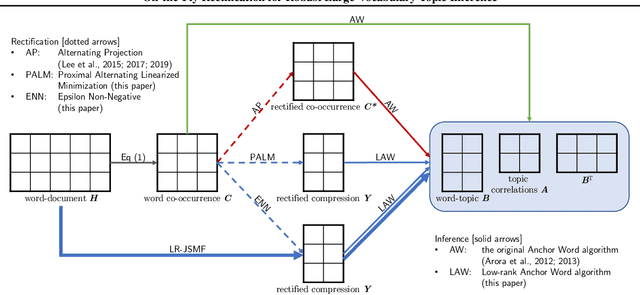

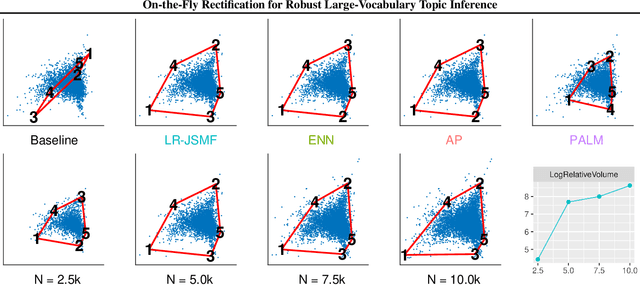
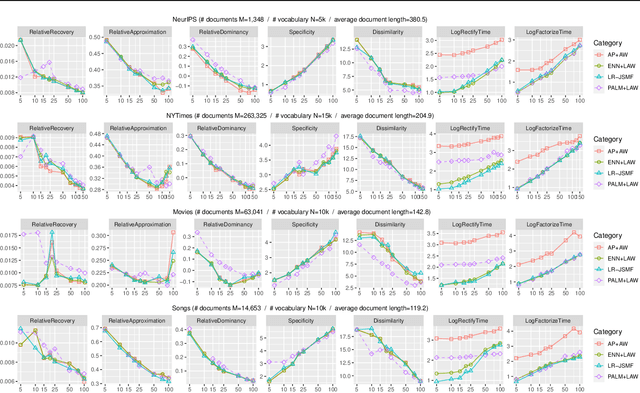
Across many data domains, co-occurrence statistics about the joint appearance of objects are powerfully informative. By transforming unsupervised learning problems into decompositions of co-occurrence statistics, spectral algorithms provide transparent and efficient algorithms for posterior inference such as latent topic analysis and community detection. As object vocabularies grow, however, it becomes rapidly more expensive to store and run inference algorithms on co-occurrence statistics. Rectifying co-occurrence, the key process to uphold model assumptions, becomes increasingly more vital in the presence of rare terms, but current techniques cannot scale to large vocabularies. We propose novel methods that simultaneously compress and rectify co-occurrence statistics, scaling gracefully with the size of vocabulary and the dimension of latent space. We also present new algorithms learning latent variables from the compressed statistics, and verify that our methods perform comparably to previous approaches on both textual and non-textual data.
Tecnologica cosa: Modeling Storyteller Personalities in Boccaccio's Decameron
Sep 22, 2021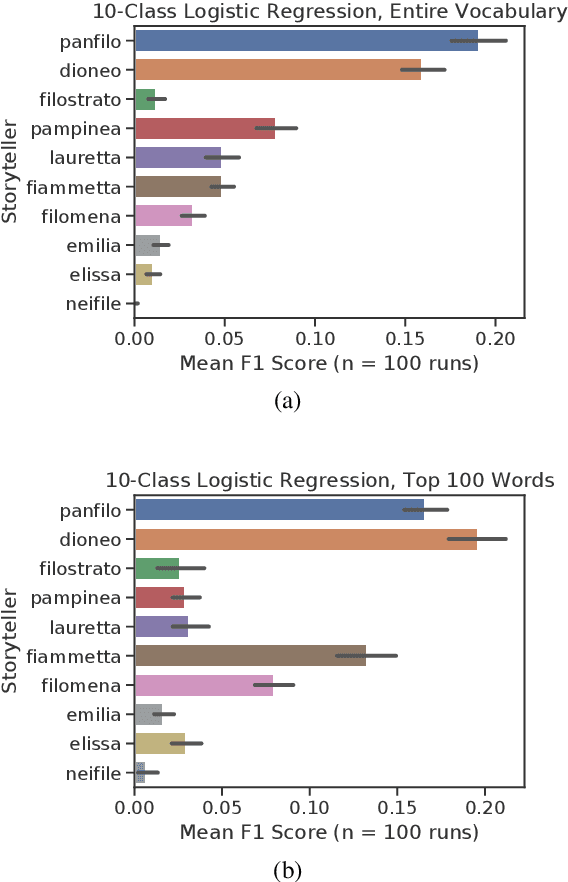


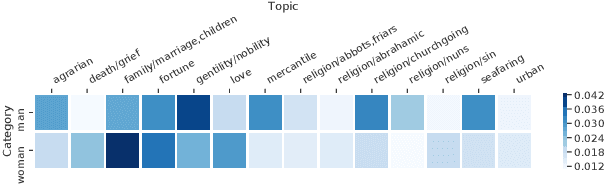
We explore Boccaccio's Decameron to see how digital humanities tools can be used for tasks that have limited data in a language no longer in contemporary use: medieval Italian. We focus our analysis on the question: Do the different storytellers in the text exhibit distinct personalities? To answer this question, we curate and release a dataset based on the authoritative edition of the text. We use supervised classification methods to predict storytellers based on the stories they tell, confirming the difficulty of the task, and demonstrate that topic modeling can extract thematic storyteller "profiles."
Comparing Text Representations: A Theory-Driven Approach
Sep 15, 2021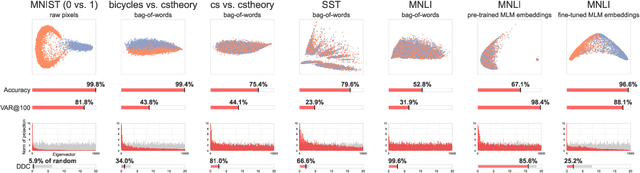
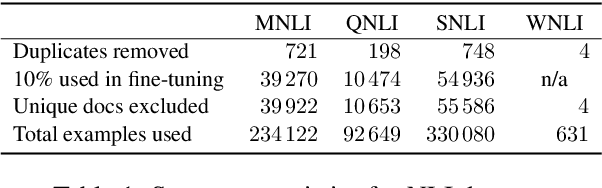
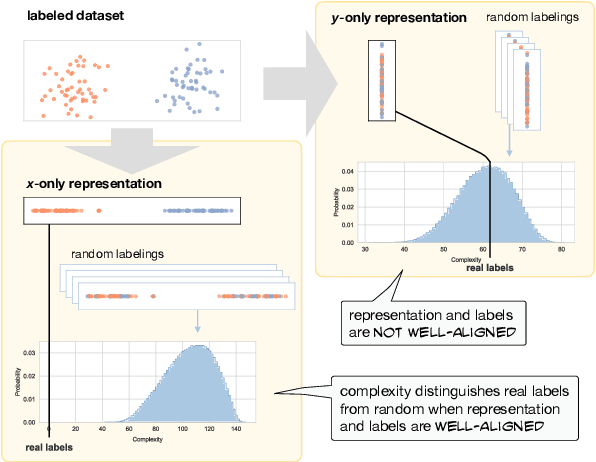
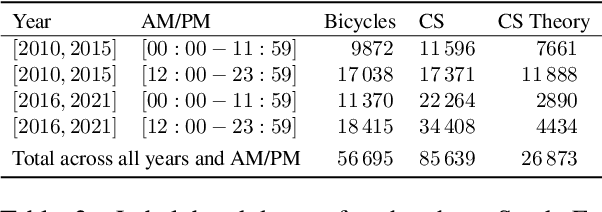
Much of the progress in contemporary NLP has come from learning representations, such as masked language model (MLM) contextual embeddings, that turn challenging problems into simple classification tasks. But how do we quantify and explain this effect? We adapt general tools from computational learning theory to fit the specific characteristics of text datasets and present a method to evaluate the compatibility between representations and tasks. Even though many tasks can be easily solved with simple bag-of-words (BOW) representations, BOW does poorly on hard natural language inference tasks. For one such task we find that BOW cannot distinguish between real and randomized labelings, while pre-trained MLM representations show 72x greater distinction between real and random labelings than BOW. This method provides a calibrated, quantitative measure of the difficulty of a classification-based NLP task, enabling comparisons between representations without requiring empirical evaluations that may be sensitive to initializations and hyperparameters. The method provides a fresh perspective on the patterns in a dataset and the alignment of those patterns with specific labels.
Domain-Specific Lexical Grounding in Noisy Visual-Textual Documents
Oct 30, 2020
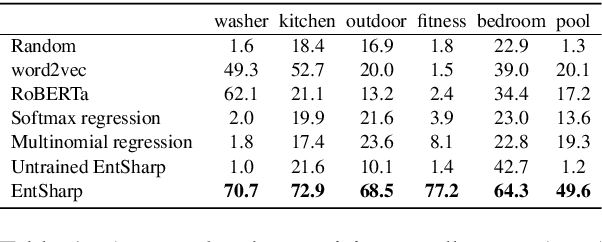
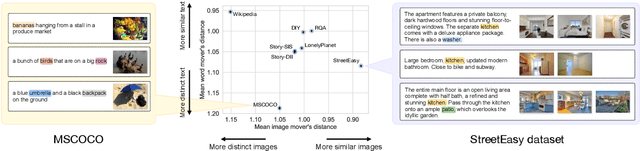

Images can give us insights into the contextual meanings of words, but current image-text grounding approaches require detailed annotations. Such granular annotation is rare, expensive, and unavailable in most domain-specific contexts. In contrast, unlabeled multi-image, multi-sentence documents are abundant. Can lexical grounding be learned from such documents, even though they have significant lexical and visual overlap? Working with a case study dataset of real estate listings, we demonstrate the challenge of distinguishing highly correlated grounded terms, such as "kitchen" and "bedroom", and introduce metrics to assess this document similarity. We present a simple unsupervised clustering-based method that increases precision and recall beyond object detection and image tagging baselines when evaluated on labeled subsets of the dataset. The proposed method is particularly effective for local contextual meanings of a word, for example associating "granite" with countertops in the real estate dataset and with rocky landscapes in a Wikipedia dataset.
Topic Modeling with Contextualized Word Representation Clusters
Oct 23, 2020
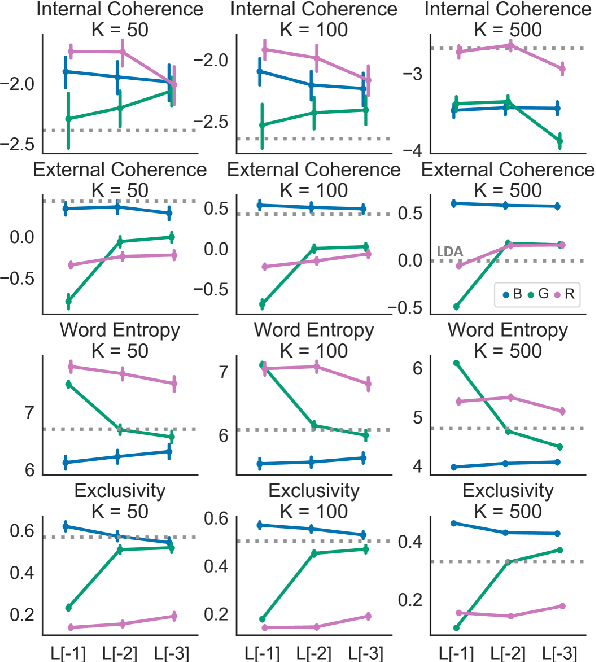
Clustering token-level contextualized word representations produces output that shares many similarities with topic models for English text collections. Unlike clusterings of vocabulary-level word embeddings, the resulting models more naturally capture polysemy and can be used as a way of organizing documents. We evaluate token clusterings trained from several different output layers of popular contextualized language models. We find that BERT and GPT-2 produce high quality clusterings, but RoBERTa does not. These cluster models are simple, reliable, and can perform as well as, if not better than, LDA topic models, maintaining high topic quality even when the number of topics is large relative to the size of the local collection.
How we do things with words: Analyzing text as social and cultural data
Jul 02, 2019In this article we describe our experiences with computational text analysis. We hope to achieve three primary goals. First, we aim to shed light on thorny issues not always at the forefront of discussions about computational text analysis methods. Second, we hope to provide a set of best practices for working with thick social and cultural concepts. Our guidance is based on our own experiences and is therefore inherently imperfect. Still, given our diversity of disciplinary backgrounds and research practices, we hope to capture a range of ideas and identify commonalities that will resonate for many. And this leads to our final goal: to help promote interdisciplinary collaborations. Interdisciplinary insights and partnerships are essential for realizing the full potential of any computational text analysis that involves social and cultural concepts, and the more we are able to bridge these divides, the more fruitful we believe our work will be.