 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronic Pain and Language: A Topic Modelling Approach to Personal Pain Descriptions
Sep 01, 2021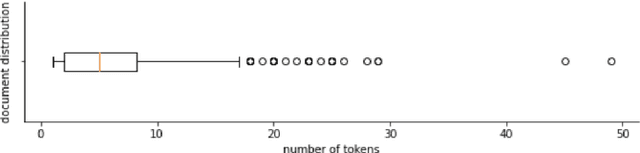
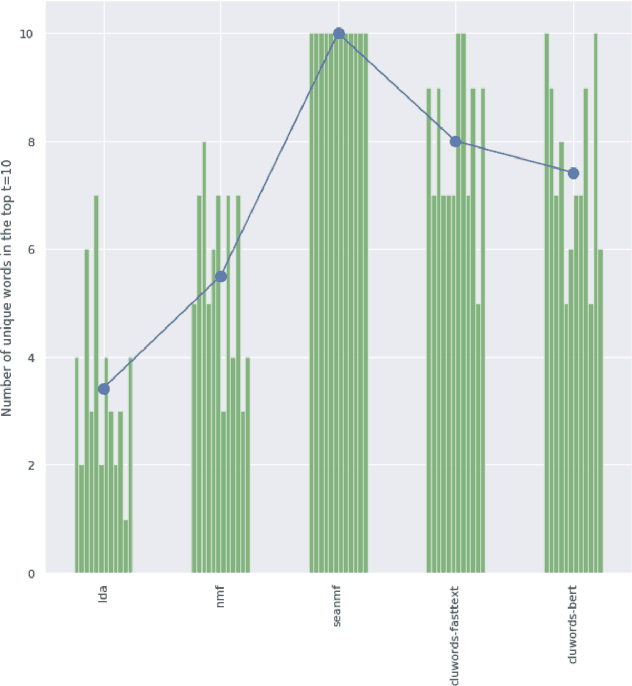
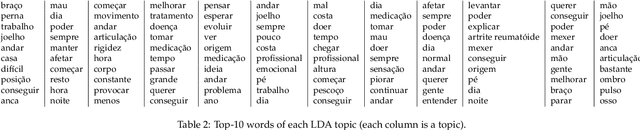
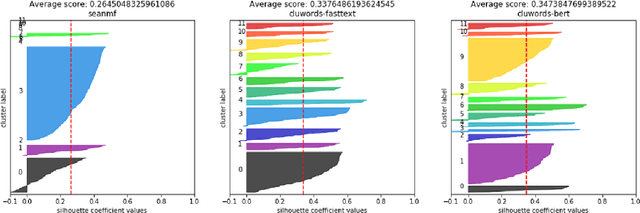
Chronic pain is recognized as a major health problem, with impacts not only at the economic, but also at the social, and individual levels. Being a private and subjective experience, it is impossible to externally and impartially experience, describe, and interpret chronic pain as a purely noxious stimulus that would directly point to a causal agent and facilitate its mitigation, contrary to acute pain, the assessment of which is usually straightforward. Verbal communication is, thus, key to convey relevant information to health professionals that would otherwise not be accessible to external entities, namely, intrinsic qualities about the painful experience and the patient. We propose and discuss a topic modelling approach to recognize patterns in verbal descriptions of chronic pain, and use these patterns to quantify and qualify experiences of pain. Our approaches allow for the extraction of novel insights on chronic pain experiences from the obtained topic models and latent spaces. We argue that our results are clinically relevant for the assessment and management of chronic pain.
Analysis of Chronic Pain Experiences Based on Online Reports: the RRCP Dataset
Aug 23, 2021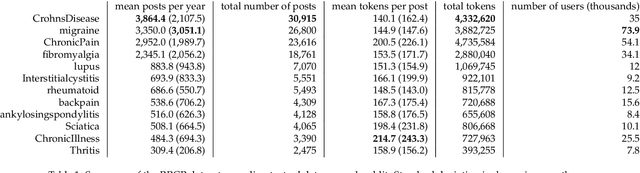
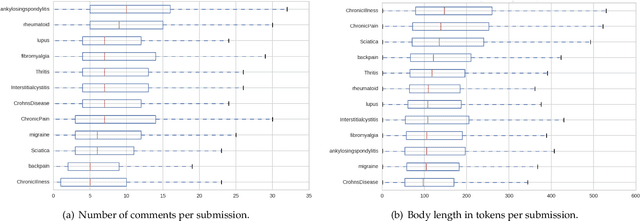

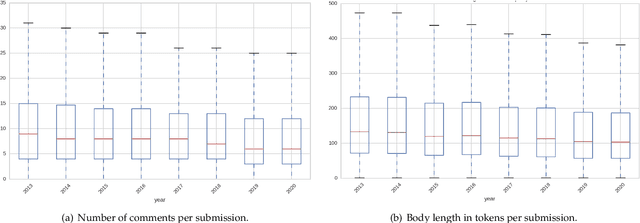
Chronic pain is recognized as a major health problem, with impacts at the economic, social, and individual levels. Being a private and subjective experience, dependent on a complex cognitive process involving the subject's past experiences, sociocultural embeddedness, as well as emotional and psychological loads, it is impossible to externally and impartially experience, describe, and interpret chronic pain as a purely noxious stimulus that would directly point to a causal agent and facilitate its mitigation. Verbal communication is, thus, key to convey relevant information to health professionals that would otherwise not be accessible to external entities. Specifically, what a patient suffering of chronic pain describes from the experience and how this information is disclosed reveals intrinsic qualities about the patient and the experience of pain itself. We present the Reddit Reports of Chronic Pain (RRCP) dataset, which comprises social media textual descriptions and discussion of various forms of chronic pain experiences, as reported from the perspective of different base pathologies. For each pathology, we identify the main concerns emergent of its consequent experience of chronic pain, as represented by the subset of documents explicitly related to it. This is obtained via document clustering in the latent space. By means of cosine similarity, we determine which concerns of different pathologies are core to all experiences of pain, and which are exclusive to certain forms. Finally, we argue that our unsupervised semantic analysis of descriptions of chronic pain echoes clinical research on how different pathologies manifest in terms of the chronic pain experience.
General-Purpose Communicative Function Recognition using a Hierarchical Network with Cascading Outputs and Maximum a Posteriori Path Estimation
Mar 07, 2020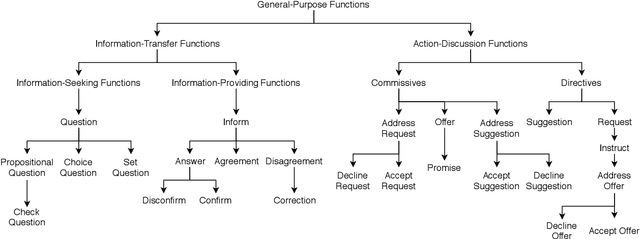
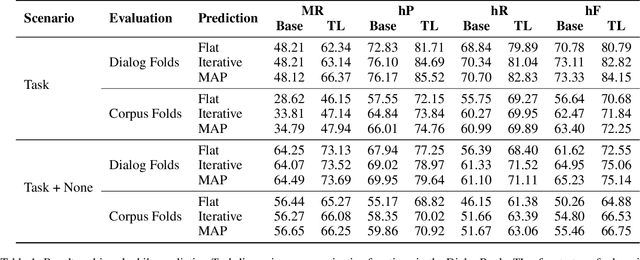
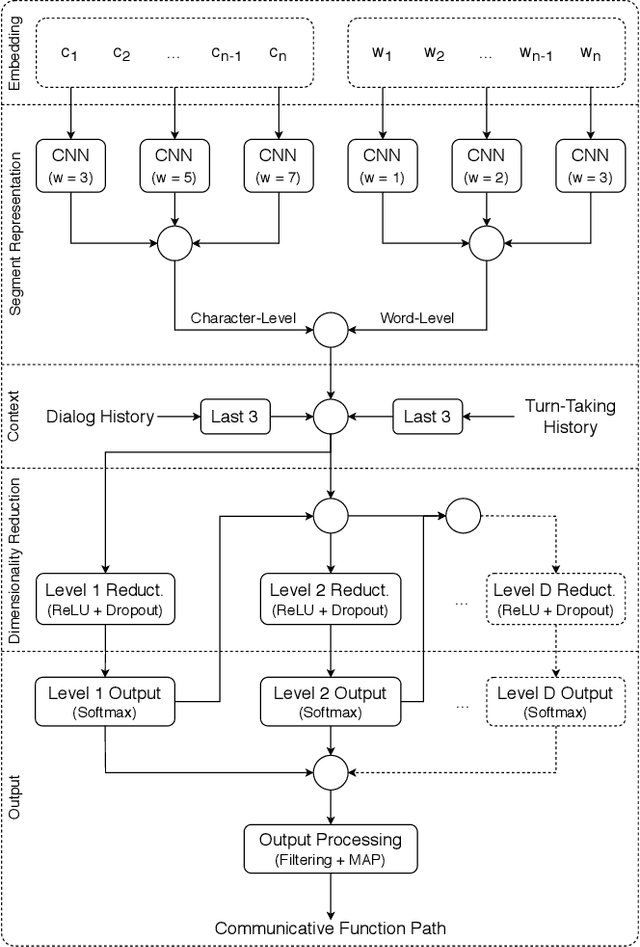
ISO 24617-2, the standard for dialog act annotation, defines a hierarchically organized set of general-purpose communicative functions. The automatic recognition of these functions, although practically unexplored, is relevant for a dialog system, since they provide cues regarding the intention behind the segments and how they should be interpreted. In this paper, we explore the recognition of general-purpose communicative functions in the DialogBank, which is a reference set of dialogs annotated according to the standard. To do so, we adapt a state-of-the-art approach on flat dialog act recognition to deal with the hierarchical classification problem. More specifically, we propose the use of a hierarchical network with cascading outputs and maximum a posteriori path estimation to predict the communicative function at each level of the hierarchy, preserve the dependencies between the functions in the path, and decide at which level to stop. Furthermore, since the amount of dialogs in the DialogBank is reduced, we rely both on additional dialogs annotated using mapping processes and on transfer learning to improve performance. The results of our experiments show that the hierarchical approach outperforms a flat one and that maximum a posteriori estimation outperforms an iterative prediction approach based on masking.
Hierarchical Multi-Label Dialog Act Recognition on Spanish Data
Jul 29, 2019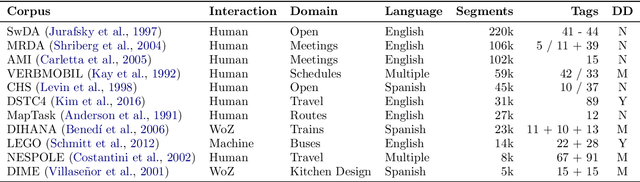

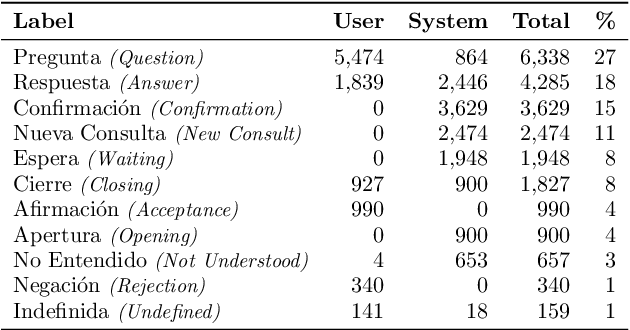
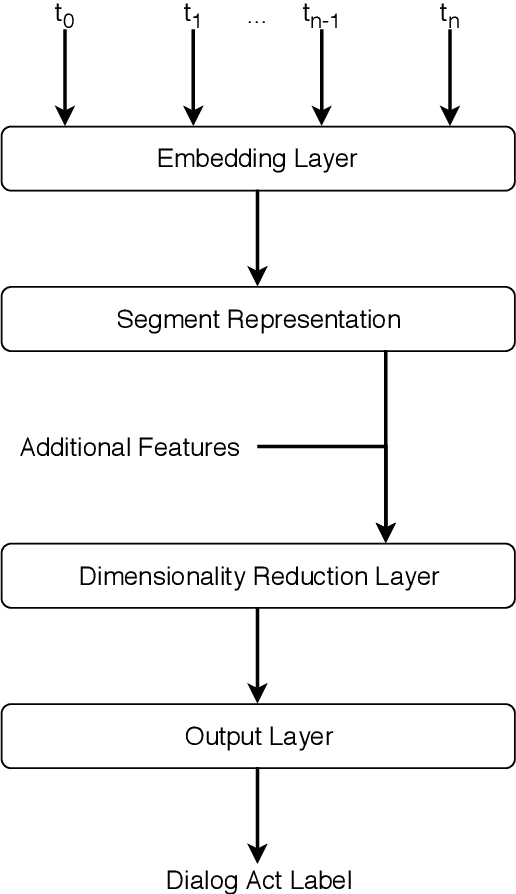
Dialog acts reveal the intention behind the uttered words. Thus, their automatic recognition is important for a dialog system trying to understand its conversational partner. The study presented in this article approaches that task on the DIHANA corpus, whose three-level dialog act annotation scheme poses problems which have not been explored in recent studies. In addition to the hierarchical problem, the two lower levels pose multi-label classification problems. Furthermore, each level in the hierarchy refers to a different aspect concerning the intention of the speaker both in terms of the structure of the dialog and the task. Also, since its dialogs are in Spanish, it allows us to assess whether the state-of-the-art approaches on English data generalize to a different language. More specifically, we compare the performance of different segment representation approaches focusing on both sequences and patterns of words and assess the importance of the dialog history and the relations between the multiple levels of the hierarchy. Concerning the single-label classification problem posed by the top level, we show that the conclusions drawn on English data also hold on Spanish data. Furthermore, we show that the approaches can be adapted to multi-label scenarios. Finally, by hierarchically combining the best classifiers for each level, we achieve the best results reported for this corpus.
* 21 pages, 4 figures, 17 tables, translated version of the article published in Linguam\'atica 11(1)
Low-dimensional Embodied Semantics for Music and Language
Jun 20, 2019
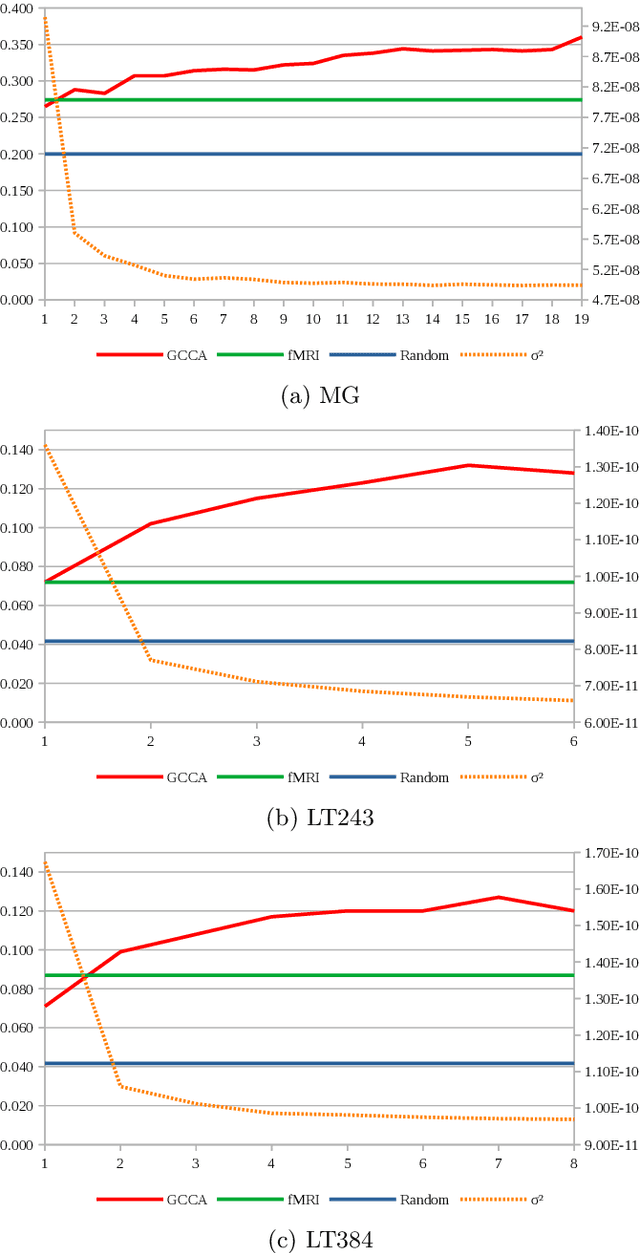
Embodied cognition states that semantics is encoded in the brain as firing patterns of neural circuits, which are learned according to the statistical structure of human multimodal experience. However, each human brain is idiosyncratically biased, according to its subjective experience history, making this biological semantic machinery noisy with respect to the overall semantics inherent to media artifacts, such as music and language excerpts. We propose to represent shared semantics using low-dimensional vector embeddings by jointly modeling several brains from human subjects. We show these unsupervised efficient representations outperform the original high-dimensional fMRI voxel spaces in proxy music genre and language topic classification tasks. We further show that joint modeling of several subjects increases the semantic richness of the learned latent vector spaces.
Learning Embodied Semantics via Music and Dance Semiotic Correlations
Mar 25, 2019

Music semantics is embodied, in the sense that meaning is biologically mediated by and grounded in the human body and brain. This embodied cognition perspective also explains why music structures modulate kinetic and somatosensory perception. We leverage this aspect of cognition, by considering dance as a proxy for music perception, in a statistical computational model that learns semiotic correlations between music audio and dance video. We evaluate the ability of this model to effectively capture underlying semantics in a cross-modal retrieval task. Quantitative results, validated with statistical significance testing, strengthen the body of evidence for embodied cognition in music and show the model can recommend music audio for dance video queries and vice-versa.
Learning multimodal representations for sample-efficient recognition of human actions
Mar 06, 2019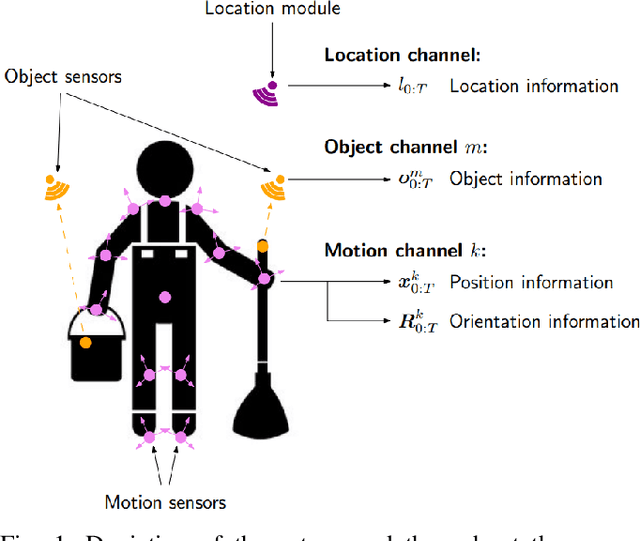
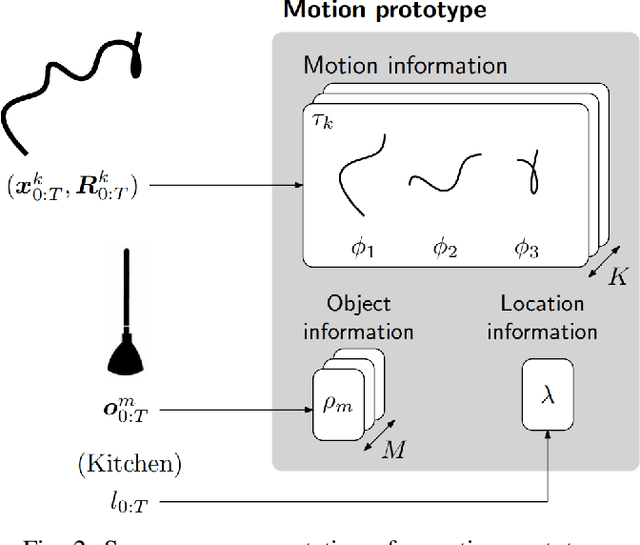
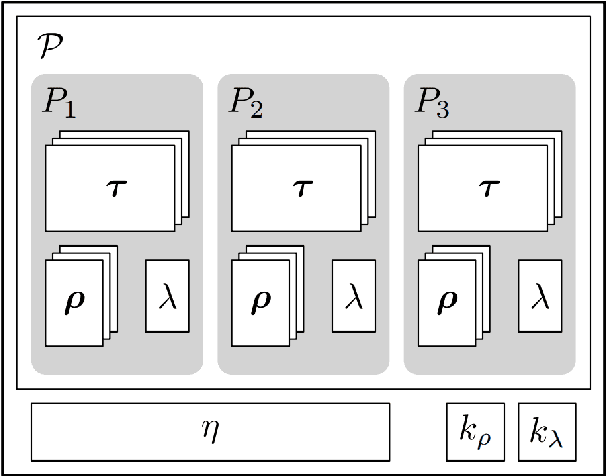

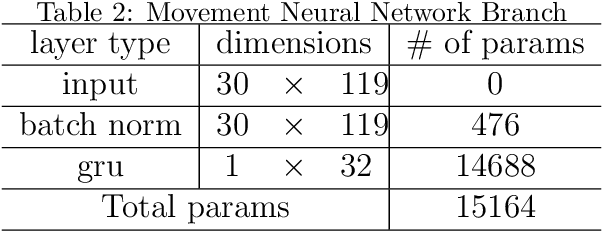
Humans interact in rich and diverse ways with the environment. However, the representation of such behavior by artificial agents is often limited. In this work we present \textit{motion concepts}, a novel multimodal representation of human actions in a household environment. A motion concept encompasses a probabilistic description of the kinematics of the action along with its contextual background, namely the location and the objects held during the performance. Furthermore, we present Online Motion Concept Learning (OMCL), a new algorithm which learns novel motion concepts from action demonstrations and recognizes previously learned motion concepts. The algorithm is evaluated on a virtual-reality household environment with the presence of a human avatar. OMCL outperforms standard motion recognition algorithms on an one-shot recognition task, attesting to its potential for sample-efficient recognition of human actions.
An Information-theoretic Approach to Machine-oriented Music Summarization
Sep 21, 2018
Music summarization allows for higher efficiency in processing, storage, and sharing of datasets. Machine-oriented approaches, being agnostic to human consumption, optimize these aspects even further. Such summaries have already been successfully validated in some MIR tasks. We now generalize previous conclusions by evaluating the impact of generic summarization of music from a probabilistic perspective. We estimate Gaussian distributions for original and summarized songs and compute their relative entropy, in order to measure information loss incurred by summarization. Our results suggest that relative entropy is a good predictor of summarization performance in the context of tasks relying on a bag-of-features model. Based on this observation, we further propose a straightforward yet expressive summarizer, which minimizes relative entropy with respect to the original song, that objectively outperforms previous methods and is better suited to avoid potential copyright issues.
A Study on Dialog Act Recognition using Character-Level Tokenization
Jul 23, 2018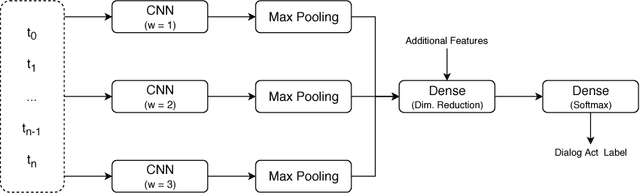


Dialog act recognition is an important step for dialog systems since it reveals the intention behind the uttered words. Most approaches on the task use word-level tokenization. In contrast, this paper explores the use of character-level tokenization. This is relevant since there is information at the sub-word level that is related to the function of the words and, thus, their intention. We also explore the use of different context windows around each token, which are able to capture important elements, such as affixes. Furthermore, we assess the importance of punctuation and capitalization. We performed experiments on both the Switchboard Dialog Act Corpus and the DIHANA Corpus. In both cases, the experiments not only show that character-level tokenization leads to better performance than the typical word-level approaches, but also that both approaches are able to capture complementary information. Thus, the best results are achieved by combining tokenization at both levels.
Deep Dialog Act Recognition using Multiple Token, Segment, and Context Information Representations
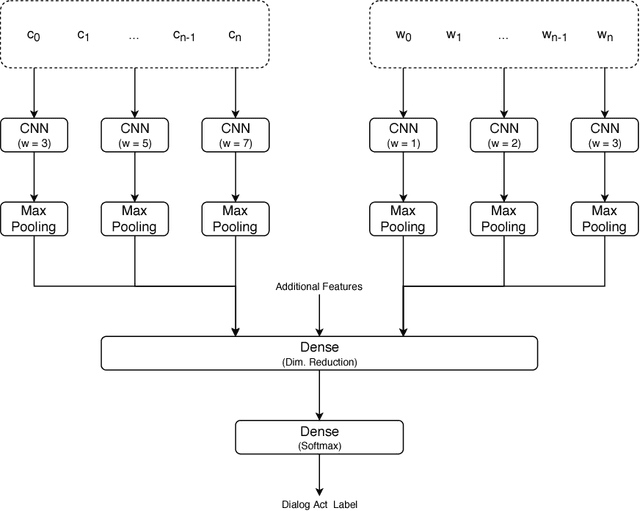
Jul 23, 2018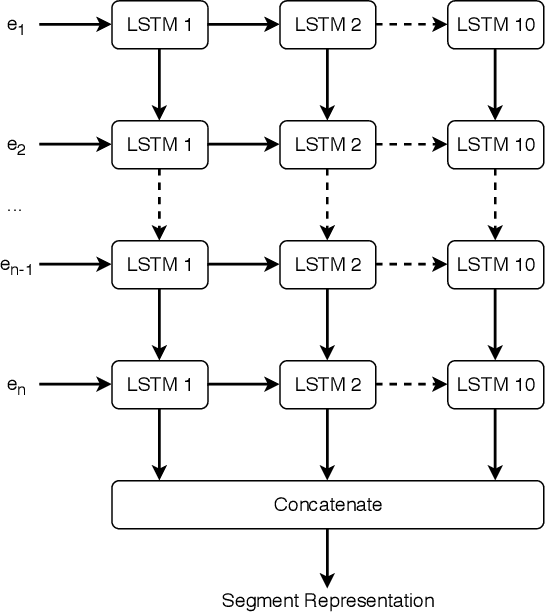
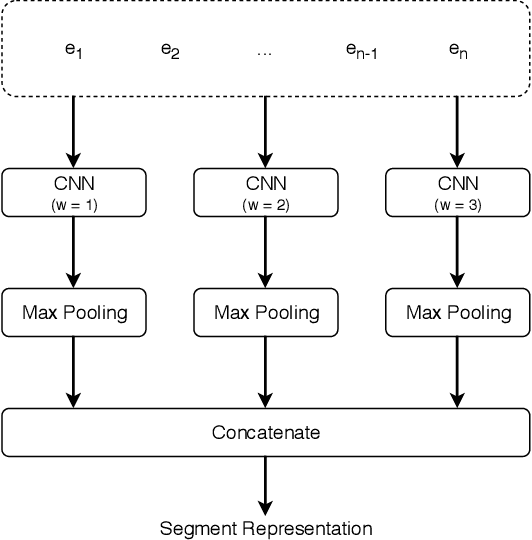
A dialog act is a representation of an intention transmitted in the form of words. In this sense, when someone wants to transmit some intention, it is revealed both in the selected words and in how they are combined to form a structured segment. Furthermore, the intentions of a speaker depend not only on her intrinsic motivation, but also on the history of the dialog and the expectation she has of its future. In this article we explore multiple representation approaches to capture cues for intention at different levels. Recent approaches on automatic dialog act recognition use Word2Vec embeddings for word representation. However, these are not able to capture segment structure information nor morphological traits related to intention. Thus, we also explore the use of dependency-based word embeddings, as well as character-level tokenization. To generate the segment representation, the top performing approaches on the task use either RNNs that are able to capture information concerning the sequentiality of the tokens or CNNs that are able to capture token patterns that reveal function. However, both aspects are important and should be captured together. Thus, we also explore the use of an RCNN. Finally, context information concerning turn-taking, as well as that provided by the surrounding segments has been proved important in previous studies. However, the representation approaches used for the latter in those studies are not appropriate to capture sequentiality, which is one of the most important characteristics of the segments in a dialog. Thus, we explore the use of approaches able to capture that information. By combining the best approaches for each aspect, we achieve results that surpass the previous state-of-the-art in a dialog system context and similar to human-level in an annotation context on the Switchboard Dialog Act Corpus, which is the most explored corpus for the task.