 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary Task Update Decomposition: The Good, The Bad and The Neutral
Aug 25, 2021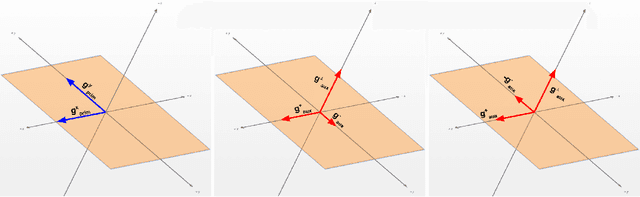

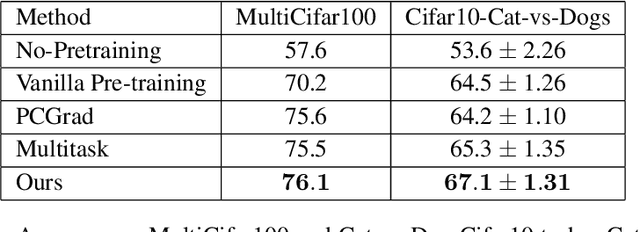
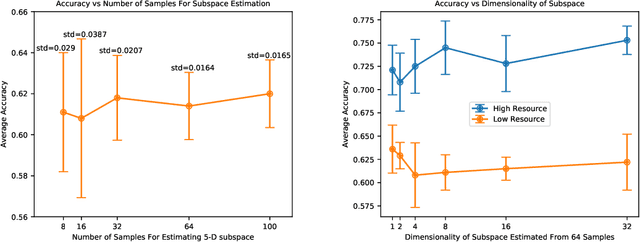
While deep learning has been very beneficial in data-rich settings, tasks with smaller training set often resort to pre-training or multitask learning to leverage data from other tasks. In this case, careful consideration is needed to select tasks and model parameterizations such that updates from the auxiliary tasks actually help the primary task. We seek to alleviate this burden by formulating a model-agnostic framework that performs fine-grained manipulation of the auxiliary task gradients. We propose to decompose auxiliary updates into directions which help, damage or leave the primary task loss unchanged. This allows weighting the update directions differently depending on their impact on the problem of interest. We present a novel and efficient algorithm for that purpose and show its advantage in practice. Our method leverages efficient automatic differentiation procedures and randomized singular value decomposition for scalability. We show that our framework is generic and encompasses some prior work as particular cases. Our approach consistently outperforms strong and widely used baselines when leveraging out-of-distribution data for Text and Image classification tasks.
What Can Unsupervised Machine Translation Contribute to High-Resource Language Pairs?
Jun 30, 2021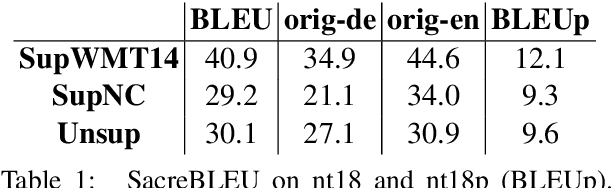
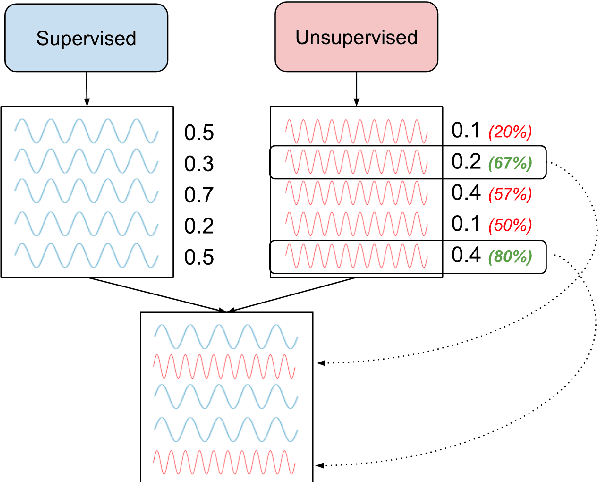
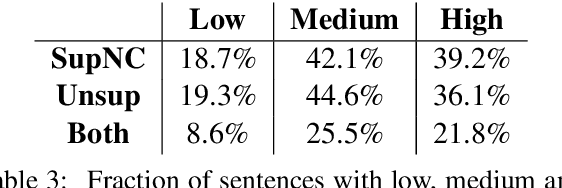
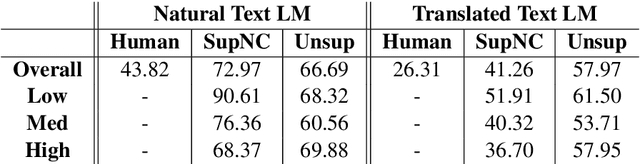
Whereas existing literature on unsupervised machine translation (MT) focuses on exploiting unsupervised techniques for low-resource language pairs where bilingual training data is scare or unavailable, we investigate whether unsupervised MT can also improve translation quality of high-resource language pairs where sufficient bitext does exist. We compare the style of correct translations generated by either supervised or unsupervised MT and find that the unsupervised output is less monotonic and more natural than supervised output. We demonstrate a way to combine the benefits of unsupervised and supervised MT into a single system, resulting in better human evaluation of quality and fluency. Our results open the door to discussions about the potential contributions of unsupervised MT in high-resource settings, and how supervised and unsupervised systems might be mutually-beneficial.
DIVE: End-to-end Speech Diarization via Iterative Speaker Embedding
May 28, 2021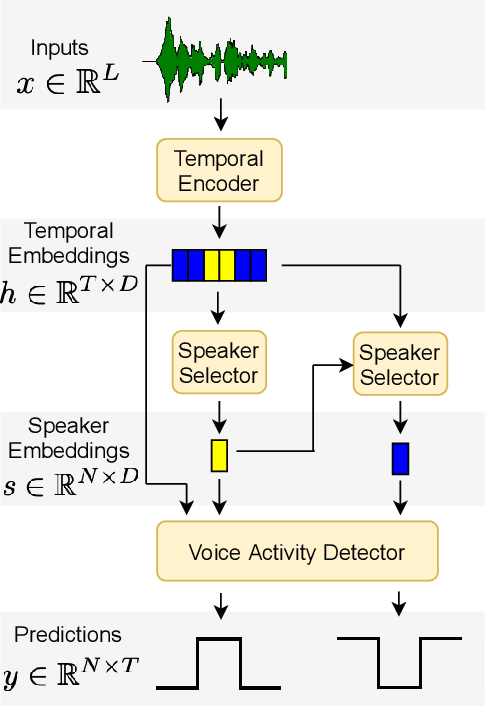
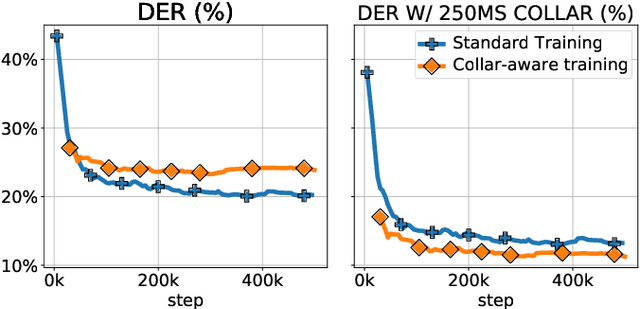
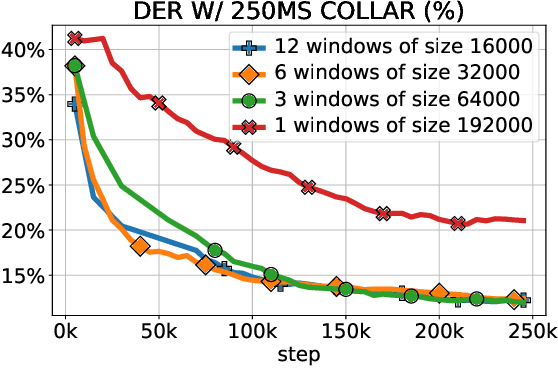
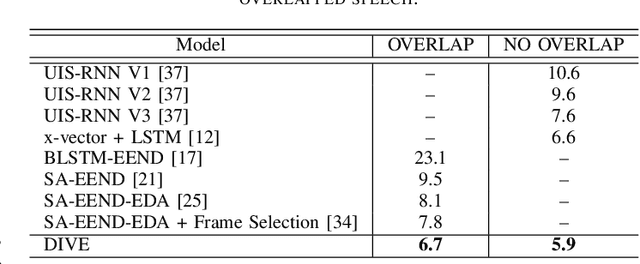
We introduce DIVE, an end-to-end speaker diarization algorithm. Our neural algorithm presents the diarization task as an iterative process: it repeatedly builds a representation for each speaker before predicting the voice activity of each speaker conditioned on the extracted representations. This strategy intrinsically resolves the speaker ordering ambiguity without requiring the classical permutation invariant training loss. In contrast with prior work, our model does not rely on pretrained speaker representations and optimizes all parameters of the system with a multi-speaker voice activity loss. Importantly, our loss explicitly excludes unreliable speaker turn boundaries from training, which is adapted to the standard collar-based Diarization Error Rate (DER) evaluation. Overall, these contributions yield a system redefining the state-of-the-art on the standard CALLHOME benchmark, with 6.7% DER compared to 7.8% for the best alternative.
Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
Apr 29, 2021

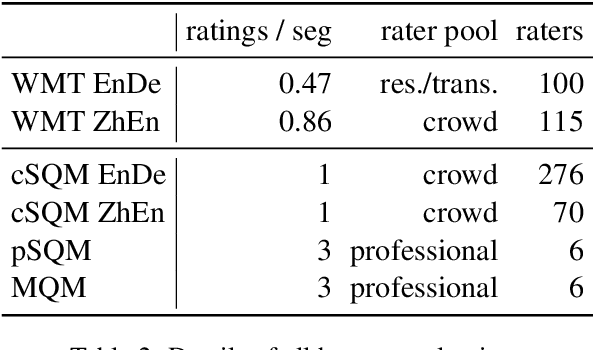

Human evaluation of modern high-quality machine translation systems is a difficult problem, and there is increasing evidence that inadequate evaluation procedures can lead to erroneous conclusions. While there has been considerable research on human evaluation, the field still lacks a commonly-accepted standard procedure. As a step toward this goal, we propose an evaluation methodology grounded in explicit error analysis, based on the Multidimensional Quality Metrics (MQM) framework. We carry out the largest MQM research study to date, scoring the outputs of top systems from the WMT 2020 shared task in two language pairs using annotations provided by professional translators with access to full document context. We analyze the resulting data extensively, finding among other results a substantially different ranking of evaluated systems from the one established by the WMT crowd workers, exhibiting a clear preference for human over machine output. Surprisingly, we also find that automatic metrics based on pre-trained embeddings can outperform human crowd workers. We make our corpus publicly available for further research.
Learning from Heterogeneous EEG Signals with Differentiable Channel Reordering
Oct 21, 2020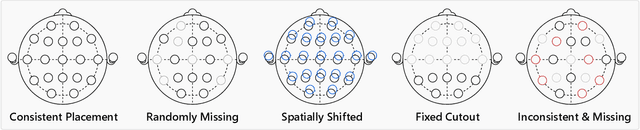
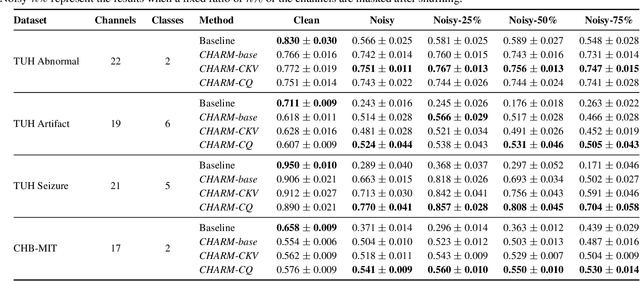
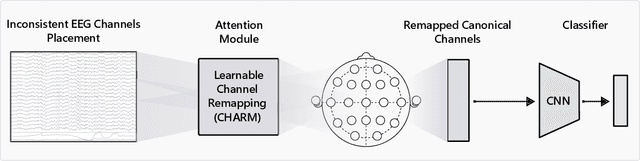
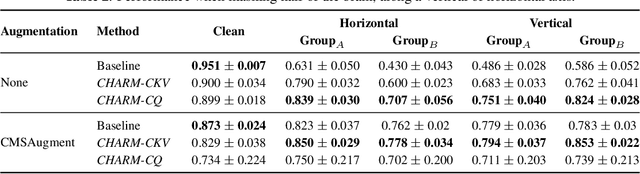
We propose CHARM, a method for training a single neural network across inconsistent input channels. Our work is motivated by Electroencephalography (EEG), where data collection protocols from different headsets result in varying channel ordering and number, which limits the feasibility of transferring trained systems across datasets. Our approach builds upon attention mechanisms to estimate a latent reordering matrix from each input signal and map input channels to a canonical order. CHARM is differentiable and can be composed further with architectures expecting a consistent channel ordering to build end-to-end trainable classifiers. We perform experiments on four EEG classification datasets and demonstrate the efficacy of CHARM via simulated shuffling and masking of input channels. Moreover, our method improves the transfer of pre-trained representations between datasets collected with different protocols.
Contrastive Learning of General-Purpose Audio Representations
Oct 21, 2020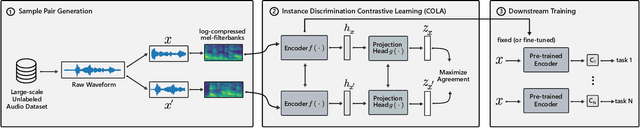
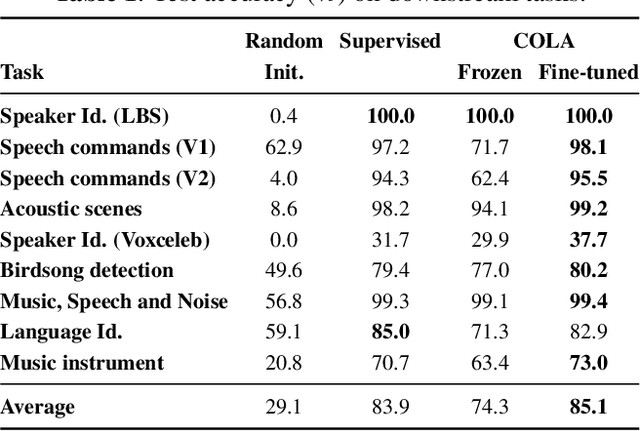
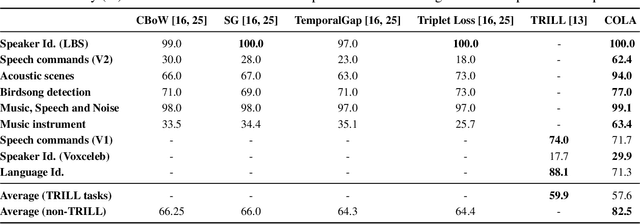
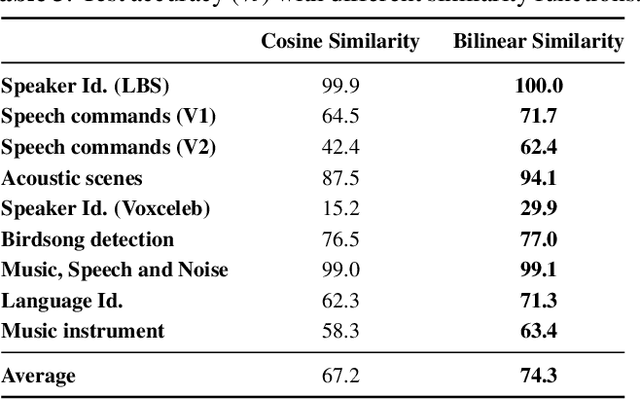
We introduce COLA, a self-supervised pre-training approach for learning a general-purpose representation of audio. Our approach is based on contrastive learning: it learns a representation which assigns high similarity to audio segments extracted from the same recording while assigning lower similarity to segments from different recordings. We build on top of recent advances in contrastive learning for computer vision and reinforcement learning to design a lightweight, easy-to-implement self-supervised model of audio. We pre-train embeddings on the large-scale Audioset database and transfer these representations to 9 diverse classification tasks, including speech, music, animal sounds, and acoustic scenes. We show that despite its simplicity, our method significantly outperforms previous self-supervised systems. We furthermore conduct ablation studies to identify key design choices and release a library to pre-train and fine-tune COLA models.
Human-Paraphrased References Improve Neural Machine Translation
Oct 20, 2020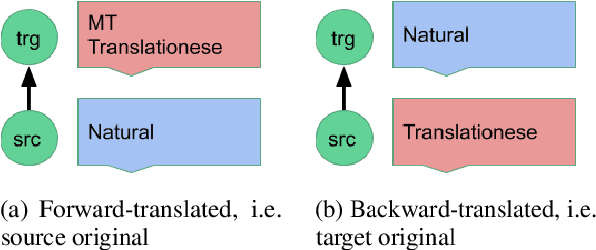
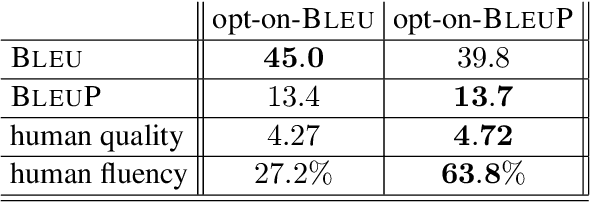
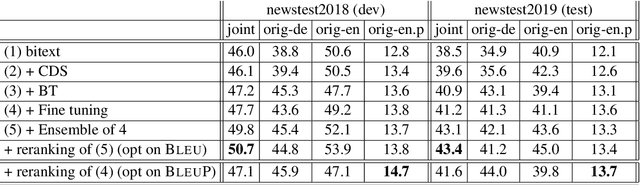
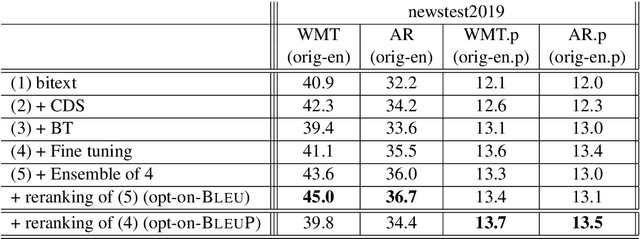
Automatic evaluation comparing candidate translations to human-generated paraphrases of reference translations has recently been proposed by Freitag et al. When used in place of original references, the paraphrased versions produce metric scores that correlate better with human judgment. This effect holds for a variety of different automatic metrics, and tends to favor natural formulations over more literal (translationese) ones. In this paper we compare the results of performing end-to-end system development using standard and paraphrased references. With state-of-the-art English-German NMT components, we show that tuning to paraphrased references produces a system that is significantly better according to human judgment, but 5 BLEU points worse when tested on standard references. Our work confirms the finding that paraphrased references yield metric scores that correlate better with human judgment, and demonstrates for the first time that using these scores for system development can lead to significant improvements.
Toward Better Storylines with Sentence-Level Language Models
May 11, 2020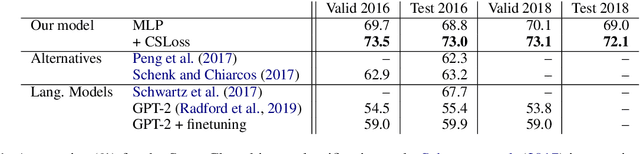
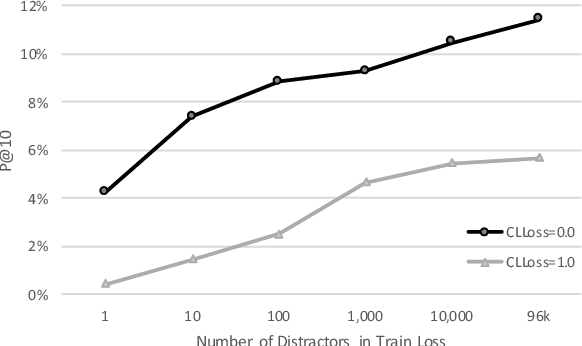
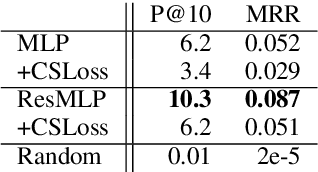
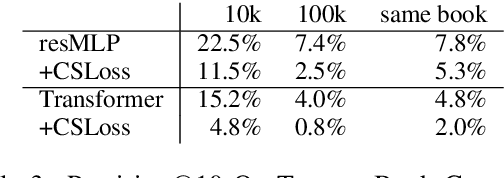
We propose a sentence-level language model which selects the next sentence in a story from a finite set of fluent alternatives. Since it does not need to model fluency, the sentence-level language model can focus on longer range dependencies, which are crucial for multi-sentence coherence. Rather than dealing with individual words, our method treats the story so far as a list of pre-trained sentence embeddings and predicts an embedding for the next sentence, which is more efficient than predicting word embeddings. Notably this allows us to consider a large number of candidates for the next sentence during training. We demonstrate the effectiveness of our approach with state-of-the-art accuracy on the unsupervised Story Cloze task and with promising results on larger-scale next sentence prediction tasks.
BLEU might be Guilty but References are not Innocent
Apr 13, 2020
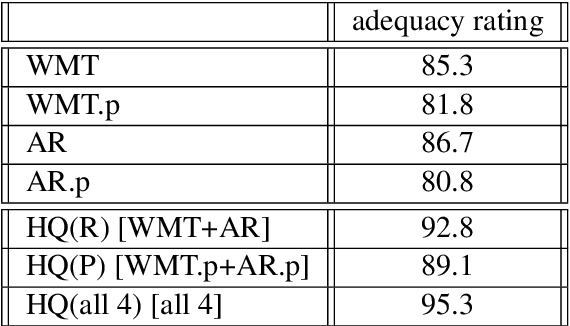
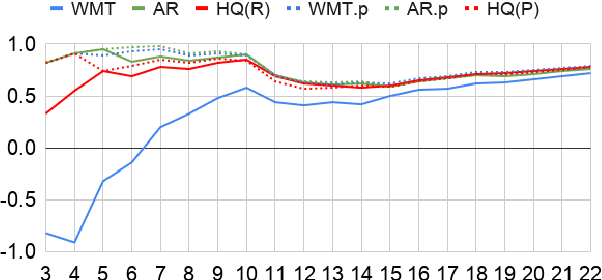
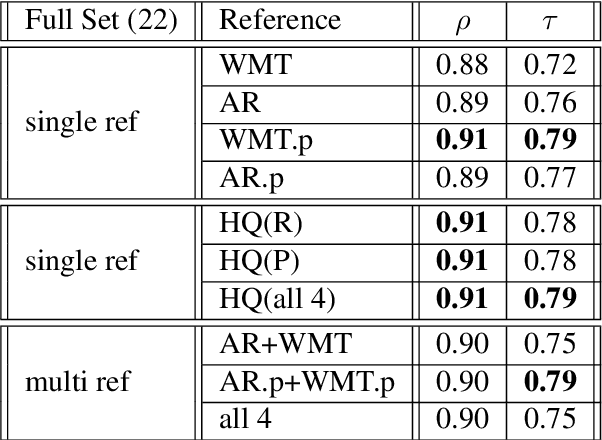
The quality of automatic metrics for machine translation has been increasingly called into question, especially for high-quality systems. This paper demonstrates that, while choice of metric is important, the nature of the references is also critical. We study different methods to collect references and compare their value in automated evaluation by reporting correlation with human evaluation for a variety of systems and metrics. Motivated by the finding that typical references exhibit poor diversity, concentrating around translationese language, we develop a paraphrasing task for linguists to perform on existing reference translations, which counteracts this bias. Our method yields higher correlation with human judgment not only for the submissions of WMT 2019 English to German, but also for Back-translation and APE augmented MT output, which have been shown to have low correlation with automatic metrics using standard references. We demonstrate that our methodology improves correlation with all modern evaluation metrics we look at, including embedding-based methods. To complete this picture, we reveal that multi-reference BLEU does not improve the correlation for high quality output, and present an alternative multi-reference formulation that is more effective.
Efficient Content-Based Sparse Attention with Routing Transformers
Mar 12, 2020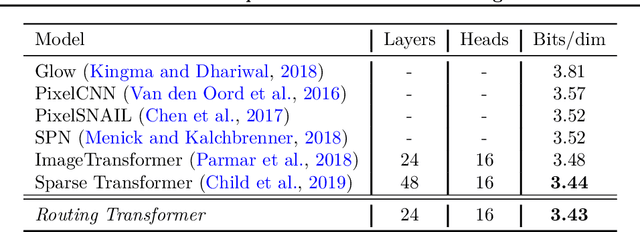
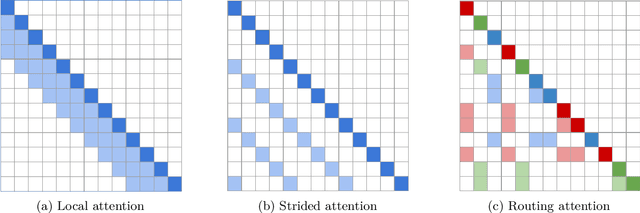
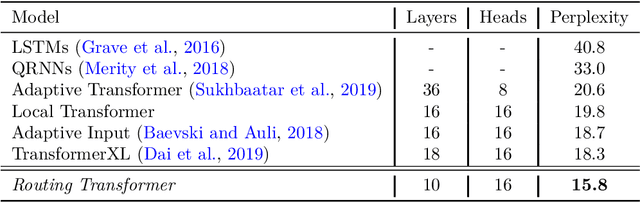

Self-attention has recently been adopted for a wide range of sequence modeling problems. Despite its effectiveness, self-attention suffers from quadratic compute and memory requirements with respect to sequence length. Successful approaches to reduce this complexity focused on attending to local sliding windows or a small set of locations independent of content. Our work proposes to learn dynamic sparse attention patterns that avoid allocating computation and memory to attend to content unrelated to the query of interest. This work builds upon two lines of research: it combines the modeling flexibility of prior work on content-based sparse attention with the efficiency gains from approaches based on local, temporal sparse attention. Our model, the Routing Transformer, endows self-attention with a sparse routing module based on online k-means while reducing the overall complexity of attention to $O\left(n^{1.5}d\right)$ from $O\left(n^2d\right)$ for sequence length $n$ and hidden dimension $d$. We show that our model outperforms comparable sparse attention models on language modeling on Wikitext-103 (15.8 vs 18.3 perplexity) as well as on image generation on ImageNet-64 (3.43 vs 3.44 bits/dim) while using fewer self-attention layers.