 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Undesirable Word Embedding Associations
Aug 18, 2019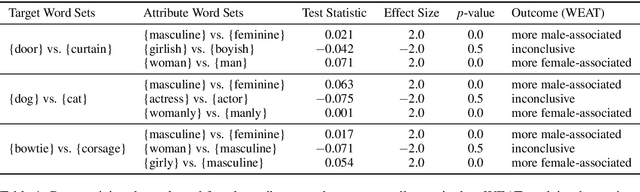
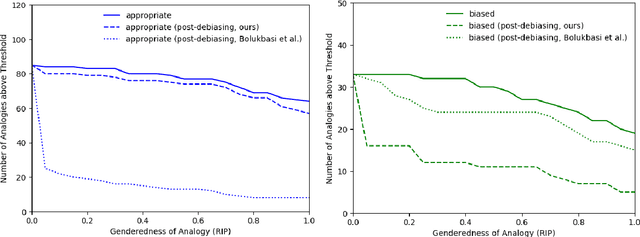
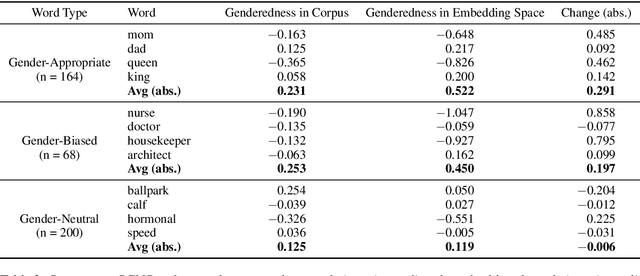
Word embeddings are often criticized for capturing undesirable word associations such as gender stereotypes. However, methods for measuring and removing such biases remain poorly understood. We show that for any embedding model that implicitly does matrix factorization, debiasing vectors post hoc using subspace projection (Bolukbasi et al., 2016) is, under certain conditions, equivalent to training on an unbiased corpus. We also prove that WEAT, the most common association test for word embeddings, systematically overestimates bias. Given that the subspace projection method is provably effective, we use it to derive a new measure of association called the $\textit{relational inner product association}$ (RIPA). Experiments with RIPA reveal that, on average, skipgram with negative sampling (SGNS) does not make most words any more gendered than they are in the training corpus. However, for gender-stereotyped words, SGNS actually amplifies the gender association in the corpus.
Latent ODEs for Irregularly-Sampled Time Series
Jul 08, 2019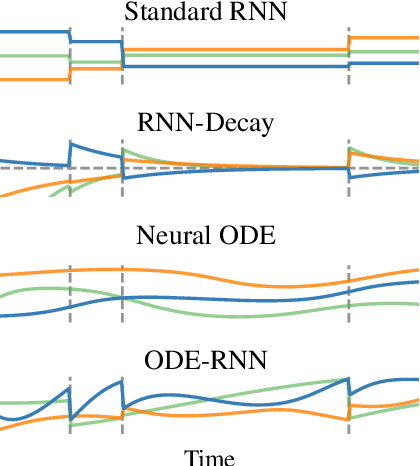
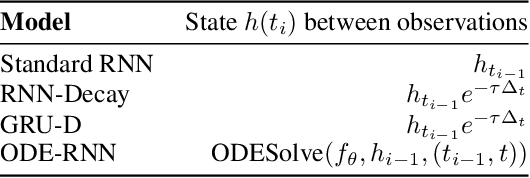
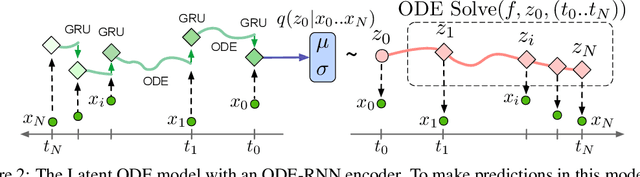
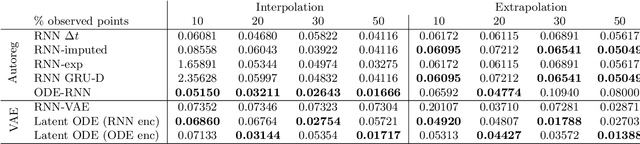
Time series with non-uniform intervals occur in many applications, and are difficult to model using standard recurrent neural networks (RNNs). We generalize RNNs to have continuous-time hidden dynamics defined by ordinary differential equations (ODEs), a model we call ODE-RNNs. Furthermore, we use ODE-RNNs to replace the recognition network of the recently-proposed Latent ODE model. Both ODE-RNNs and Latent ODEs can naturally handle arbitrary time gaps between observations, and can explicitly model the probability of observation times using Poisson processes. We show experimentally that these ODE-based models outperform their RNN-based counterparts on irregularly-sampled data.
Residual Flows for Invertible Generative Modeling
Jun 07, 2019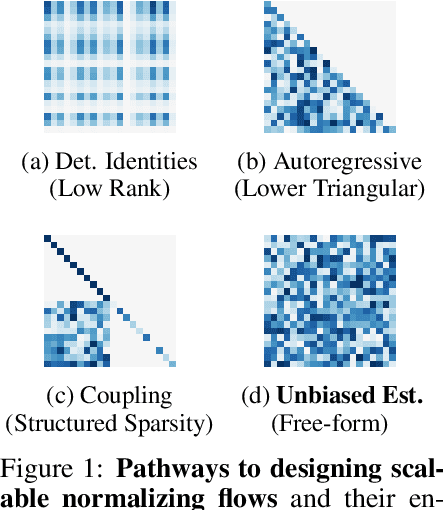
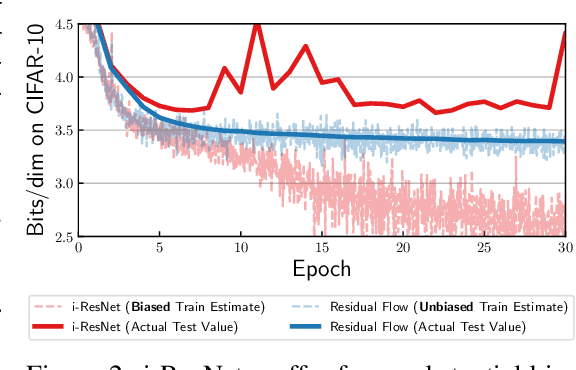
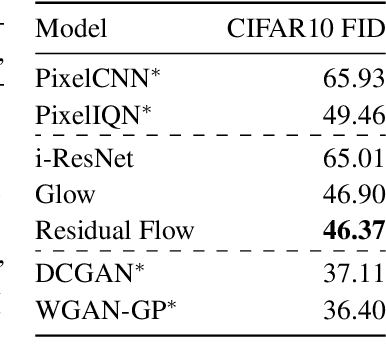
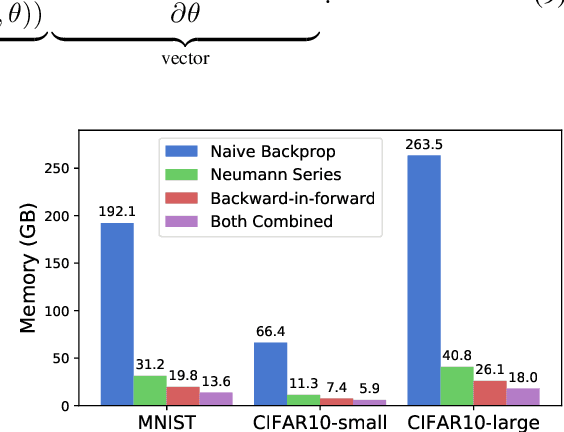
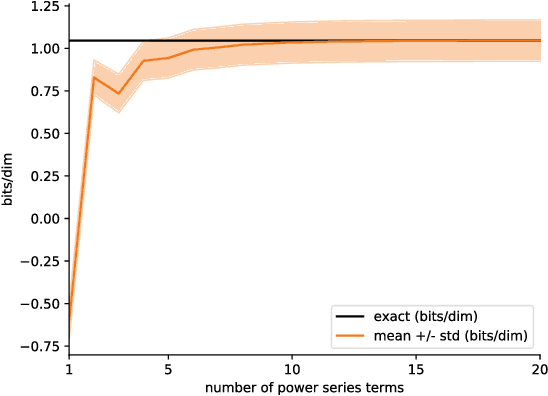
Flow-based generative models parameterize probability distributions through an invertible transformation and can be trained by maximum likelihood. Invertible residual networks provide a flexible family of transformations where only Lipschitz conditions rather than strict architectural constraints are needed for enforcing invertibility. However, prior work trained invertible residual networks for density estimation by relying on biased log-density estimates whose bias increased with the network's expressiveness. We give a tractable unbiased estimate of the log density, and reduce the memory required during training by a factor of ten. Furthermore, we improve invertible residual blocks by proposing the use of activation functions that avoid gradient saturation and generalizing the Lipschitz condition to induced mixed norms. The resulting approach, called Residual Flows, achieves state-of-the-art performance on density estimation amongst flow-based models, and outperforms networks that use coupling blocks at joint generative and discriminative modeling.
Self-Tuning Networks: Bilevel Optimization of Hyperparameters using Structured Best-Response Functions
Mar 07, 2019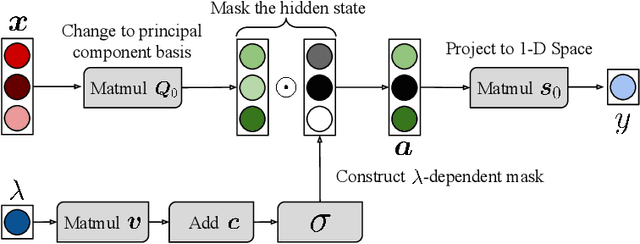
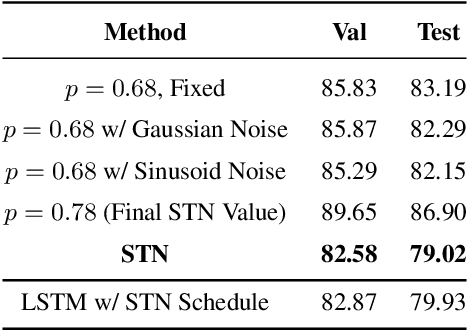
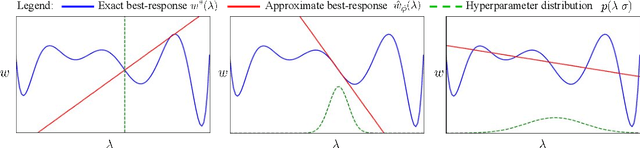
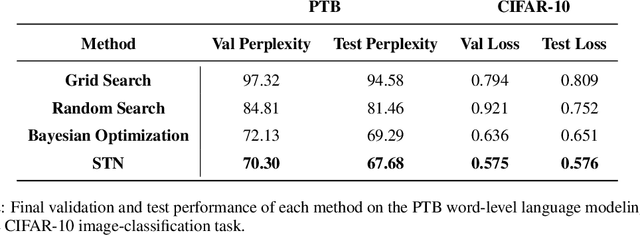
Hyperparameter optimization can be formulated as a bilevel optimization problem, where the optimal parameters on the training set depend on the hyperparameters. We aim to adapt regularization hyperparameters for neural networks by fitting compact approximations to the best-response function, which maps hyperparameters to optimal weights and biases. We show how to construct scalable best-response approximations for neural networks by modeling the best-response as a single network whose hidden units are gated conditionally on the regularizer. We justify this approximation by showing the exact best-response for a shallow linear network with L2-regularized Jacobian can be represented by a similar gating mechanism. We fit this model using a gradient-based hyperparameter optimization algorithm which alternates between approximating the best-response around the current hyperparameters and optimizing the hyperparameters using the approximate best-response function. Unlike other gradient-based approaches, we do not require differentiating the training loss with respect to the hyperparameters, allowing us to tune discrete hyperparameters, data augmentation hyperparameters, and dropout probabilities. Because the hyperparameters are adapted online, our approach discovers hyperparameter schedules that can outperform fixed hyperparameter values. Empirically, our approach outperforms competing hyperparameter optimization methods on large-scale deep learning problems. We call our networks, which update their own hyperparameters online during training, Self-Tuning Networks (STNs).
Invertible Residual Networks
Nov 02, 2018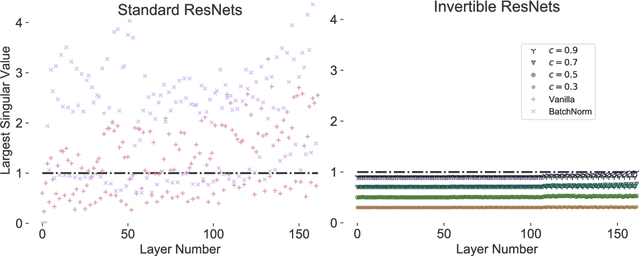
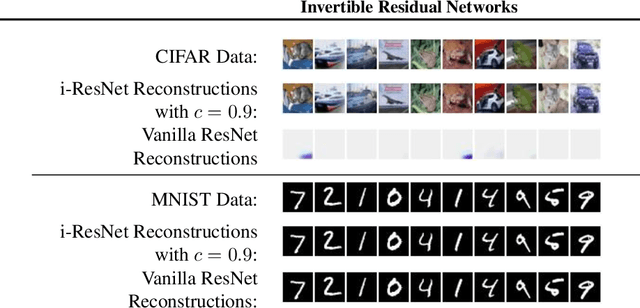
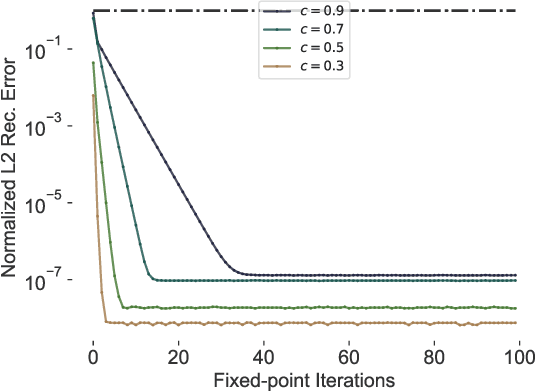
Reversible deep networks provide useful theoretical guarantees and have proven to be a powerful class of functions in many applications. Usually, they rely on analytical inverses using dimension splitting, fundamentally constraining their structure compared to common architectures. Based on recent links between ordinary differential equations and deep networks, we provide a sufficient condition when standard ResNets are invertible. This condition allows unconstrained architectures for residual blocks, while only requiring an adaption to their regularization scheme. We numerically compute their inverse, which has O(1) memory cost and computational cost of 5-20 forward passes. Finally, we show that invertible ResNets perform on par with standard ResNets on classifying MNIST and CIFAR10 images.
Towards Understanding Linear Word Analogies
Oct 27, 2018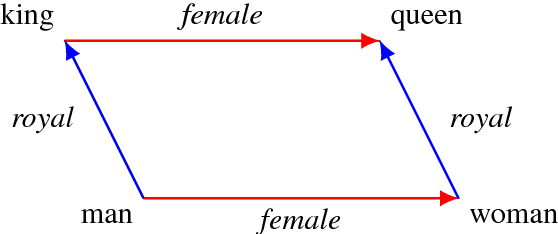
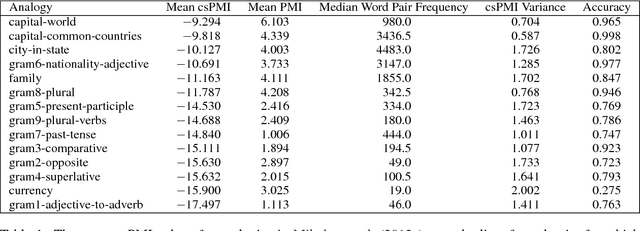
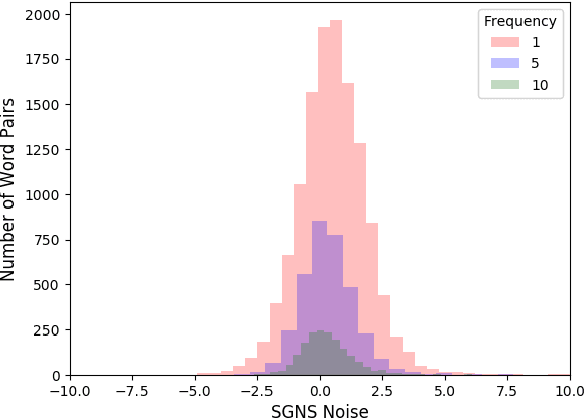
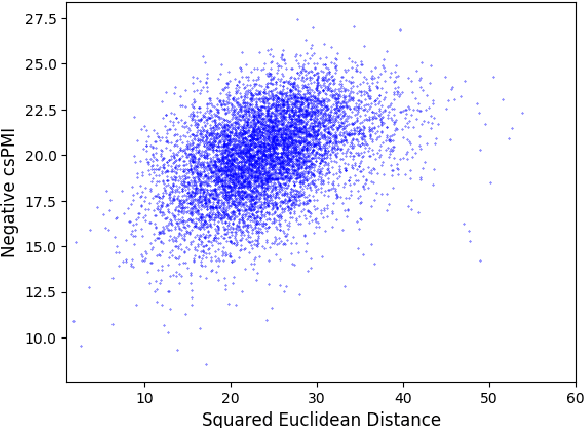
A surprising property of word vectors is that vector algebra can often be used to solve word analogies. However, it is unclear why - and when - linear operators correspond to non-linear embedding models such as skip-gram with negative sampling (SGNS). We provide a rigorous explanation of this phenomenon without making the strong assumptions that past work has made about the vector space and word distribution. Our theory has several implications. Past work has often conjectured that linear structures exist in vector spaces because relations can be represented as ratios; we prove that this holds for SGNS. We provide novel theoretical justification for the addition of SGNS word vectors by showing that it automatically down-weights the more frequent word, as weighting schemes do ad hoc. Lastly, we offer an information theoretic interpretation of Euclidean distance in vector spaces, providing rigorous justification for its use in capturing word dissimilarity.
Isolating Sources of Disentanglement in Variational Autoencoders
Oct 22, 2018
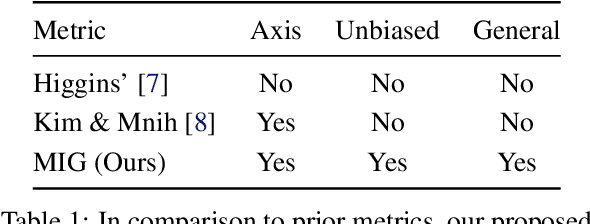
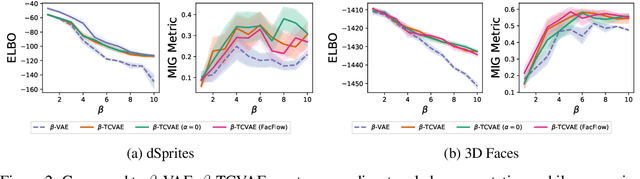
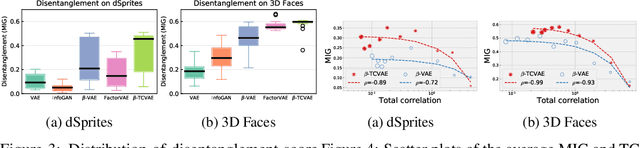
We decompose the evidence lower bound to show the existence of a term measuring the total correlation between latent variables. We use this to motivate our $\beta$-TCVAE (Total Correlation Variational Autoencoder), a refinement of the state-of-the-art $\beta$-VAE objective for learning disentangled representations, requiring no additional hyperparameters during training. We further propose a principled classifier-free measure of disentanglement called the mutual information gap (MIG). We perform extensive quantitative and qualitative experiments, in both restricted and non-restricted settings, and show a strong relation between total correlation and disentanglement, when the latent variables model is trained using our framework.
Neural Ordinary Differential Equations
Oct 22, 2018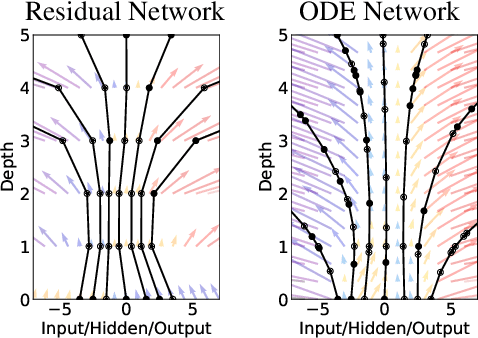
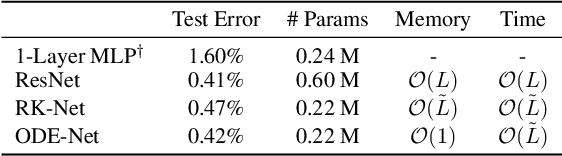
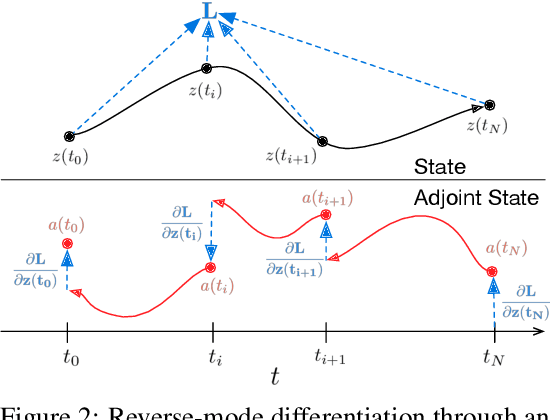
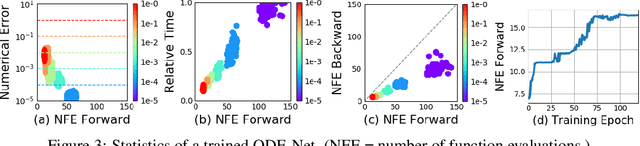
We introduce a new family of deep neural network models. Instead of specifying a discrete sequence of hidden layers, we parameterize the derivative of the hidden state using a neural network. The output of the network is computed using a black-box differential equation solver. These continuous-depth models have constant memory cost, adapt their evaluation strategy to each input, and can explicitly trade numerical precision for speed. We demonstrate these properties in continuous-depth residual networks and continuous-time latent variable models. We also construct continuous normalizing flows, a generative model that can train by maximum likelihood, without partitioning or ordering the data dimensions. For training, we show how to scalably backpropagate through any ODE solver, without access to its internal operations. This allows end-to-end training of ODEs within larger models.
FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models
Oct 22, 2018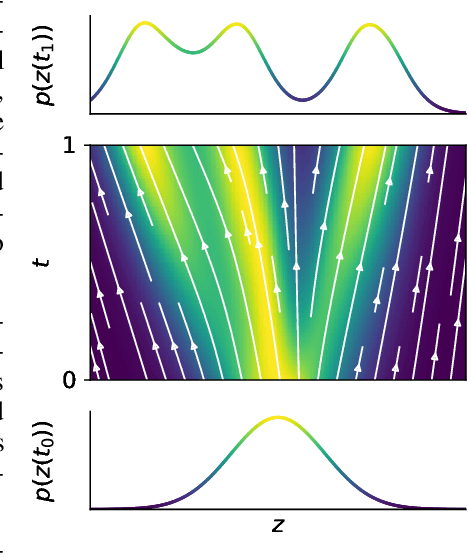

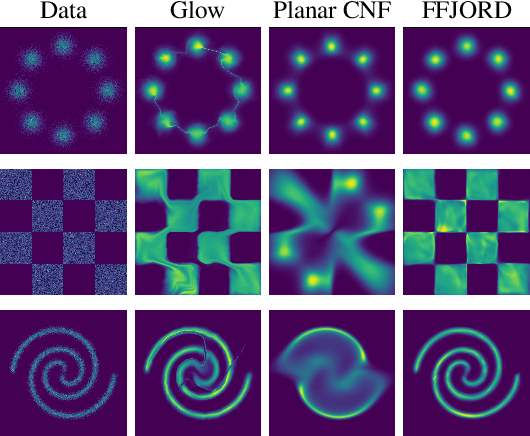
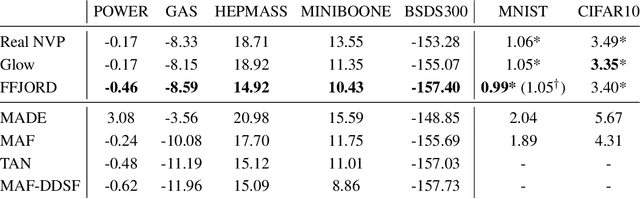
A promising class of generative models maps points from a simple distribution to a complex distribution through an invertible neural network. Likelihood-based training of these models requires restricting their architectures to allow cheap computation of Jacobian determinants. Alternatively, the Jacobian trace can be used if the transformation is specified by an ordinary differential equation. In this paper, we use Hutchinson's trace estimator to give a scalable unbiased estimate of the log-density. The result is a continuous-time invertible generative model with unbiased density estimation and one-pass sampling, while allowing unrestricted neural network architectures. We demonstrate our approach on high-dimensional density estimation, image generation, and variational inference, achieving the state-of-the-art among exact likelihood methods with efficient sampling.
Explaining Image Classifiers by Counterfactual Generation
Oct 11, 2018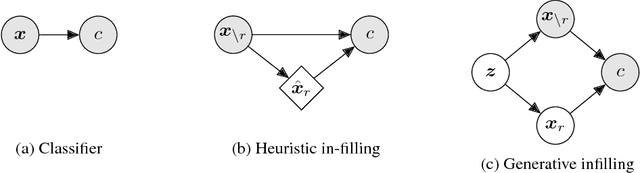

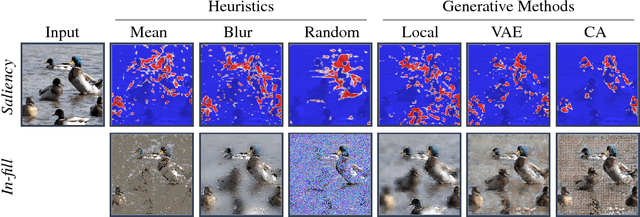

When a black-box classifier processes an input to render a prediction, which input features are relevant and why? We propose to answer this question by efficiently marginalizing over the universe of plausible alternative values for a subset of features by conditioning a generative model of the input distribution on the remaining features. In contrast with recent approaches that compute alternative feature values ad-hoc --- generating counterfactual inputs far from the natural data distribution --- our model-agnostic method produces realistic explanations, generating plausible inputs that either preserve or alter the classification confidence. When applied to image classification, our method produces more compact and relevant per-feature saliency assignment, with fewer artifacts compared to previous methods.