 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvatar4D: Synthesizing Domain-Specific 4D Humans for Real-World Pose Estimation
Dec 18, 2025We present Avatar4D, a real-world transferable pipeline for generating customizable synthetic human motion datasets tailored to domain-specific applications. Unlike prior works, which focus on general, everyday motions and offer limited flexibility, our approach provides fine-grained control over body pose, appearance, camera viewpoint, and environmental context, without requiring any manual annotations. To validate the impact of Avatar4D, we focus on sports, where domain-specific human actions and movement patterns pose unique challenges for motion understanding. In this setting, we introduce Syn2Sport, a large-scale synthetic dataset spanning sports, including baseball and ice hockey. Avatar4D features high-fidelity 4D (3D geometry over time) human motion sequences with varying player appearances rendered in diverse environments. We benchmark several state-of-the-art pose estimation models on Syn2Sport and demonstrate their effectiveness for supervised learning, zero-shot transfer to real-world data, and generalization across sports. Furthermore, we evaluate how closely the generated synthetic data aligns with real-world datasets in feature space. Our results highlight the potential of such systems to generate scalable, controllable, and transferable human datasets for diverse domain-specific tasks without relying on domain-specific real data.
OpenWildlife: Open-Vocabulary Multi-Species Wildlife Detector for Geographically-Diverse Aerial Imagery
Jun 24, 2025We introduce OpenWildlife (OW), an open-vocabulary wildlife detector designed for multi-species identification in diverse aerial imagery. While existing automated methods perform well in specific settings, they often struggle to generalize across different species and environments due to limited taxonomic coverage and rigid model architectures. In contrast, OW leverages language-aware embeddings and a novel adaptation of the Grounding-DINO framework, enabling it to identify species specified through natural language inputs across both terrestrial and marine environments. Trained on 15 datasets, OW outperforms most existing methods, achieving up to \textbf{0.981} mAP50 with fine-tuning and \textbf{0.597} mAP50 on seven datasets featuring novel species. Additionally, we introduce an efficient search algorithm that combines k-nearest neighbors and breadth-first search to prioritize areas where social species are likely to be found. This approach captures over \textbf{95\%} of species while exploring only \textbf{33\%} of the available images. To support reproducibility, we publicly release our source code and dataset splits, establishing OW as a flexible, cost-effective solution for global biodiversity assessments.
Ice Hockey Puck Localization Using Contextual Cues
Jun 04, 2025



Puck detection in ice hockey broadcast videos poses significant challenges due to the puck's small size, frequent occlusions, motion blur, broadcast artifacts, and scale inconsistencies due to varying camera zoom and broadcast camera viewpoints. Prior works focus on appearance-based or motion-based cues of the puck without explicitly modelling the cues derived from player behaviour. Players consistently turn their bodies and direct their gaze toward the puck. Motivated by this strong contextual cue, we propose Puck Localization Using Contextual Cues (PLUCC), a novel approach for scale-aware and context-driven single-frame puck detections. PLUCC consists of three components: (a) a contextual encoder, which utilizes player orientations and positioning as helpful priors; (b) a feature pyramid encoder, which extracts multiscale features from the dual encoders; and (c) a gating decoder that combines latent features with a channel gating mechanism. For evaluation, in addition to standard average precision, we propose Rink Space Localization Error (RSLE), a scale-invariant homography-based metric for removing perspective bias from rink space evaluation. The experimental results of PLUCC on the PuckDataset dataset demonstrated state-of-the-art detection performance, surpassing previous baseline methods by an average precision improvement of 12.2% and RSLE average precision of 25%. Our research demonstrates the critical role of contextual understanding in improving puck detection performance, with broad implications for automated sports analysis.
GoalieNet: A Multi-Stage Network for Joint Goalie, Equipment, and Net Pose Estimation in Ice Hockey
Jun 28, 2023In the field of computer vision-driven ice hockey analytics, one of the most challenging and least studied tasks is goalie pose estimation. Unlike general human pose estimation, goalie pose estimation is much more complex as it involves not only the detection of keypoints corresponding to the joints of the goalie concealed under thick padding and mask, but also a large number of non-human keypoints corresponding to the large leg pads and gloves worn, the stick, as well as the hockey net. To tackle this challenge, we introduce GoalieNet, a multi-stage deep neural network for jointly estimating the pose of the goalie, their equipment, and the net. Experimental results using NHL benchmark data demonstrate that the proposed GoalieNet can achieve an average of 84\% accuracy across all keypoints, where 22 out of 29 keypoints are detected with more than 80\% accuracy. This indicates that such a joint pose estimation approach can be a promising research direction.
Temporal Hockey Action Recognition via Pose and Optical Flows
Dec 22, 2018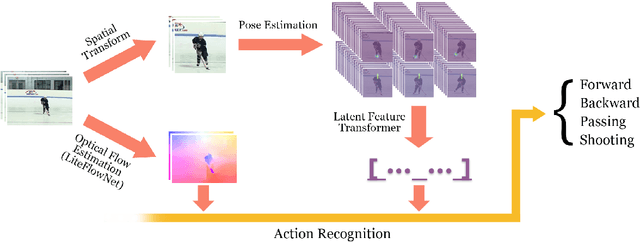
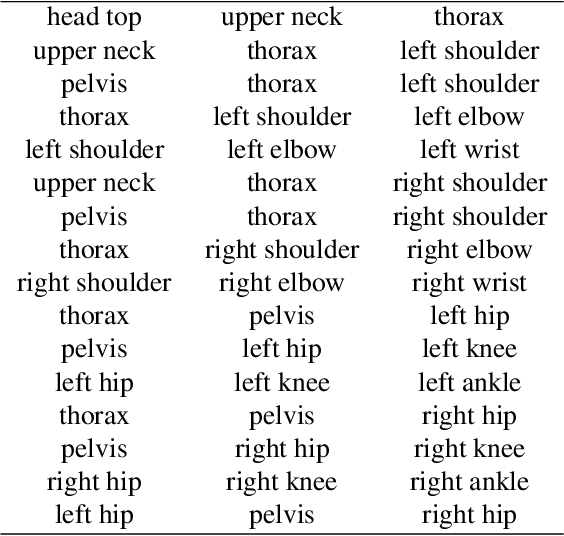
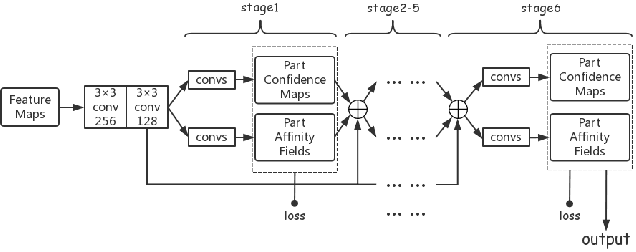
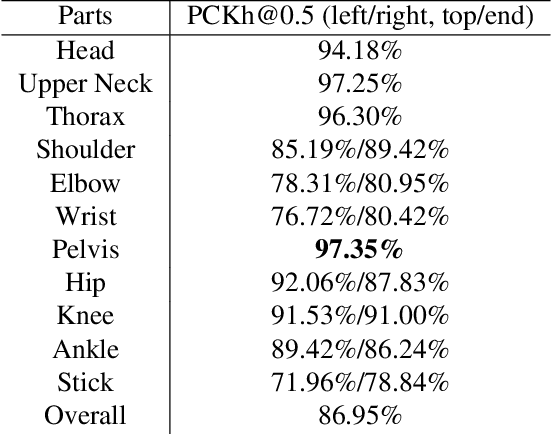
Recognizing actions in ice hockey using computer vision poses challenges due to bulky equipment and inadequate image quality. A novel two-stream framework has been designed to improve action recognition accuracy for hockey using three main components. First, pose is estimated via the Part Affinity Fields model to extract meaningful cues from the player. Second, optical flow (using LiteFlowNet) is used to extract temporal features. Third, pose and optical flow streams are fused and passed to fully-connected layers to estimate the hockey player's action. A novel publicly available dataset named HARPET (Hockey Action Recognition Pose Estimation, Temporal) was created, composed of sequences of annotated actions and pose of hockey players including their hockey sticks as an extension of human body pose. Three contributions are recognized. (1) The novel two-stream architecture achieves 85% action recognition accuracy, with the inclusion of optical flows increasing accuracy by about 10%. (2) The unique localization of hand-held objects (e.g., hockey sticks) as part of pose increases accuracy by about 13%. (3) For pose estimation, a bigger and more general dataset, MSCOCO, is successfully used for transfer learning to a smaller and more specific dataset, HARPET, achieving a PCKh of 87%.