 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiLLoC: Lossless Image Compression with Hierarchical Latent Variable Models
Dec 20, 2019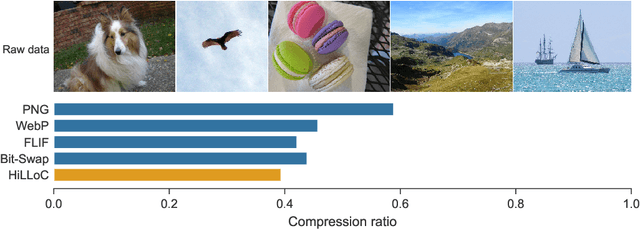
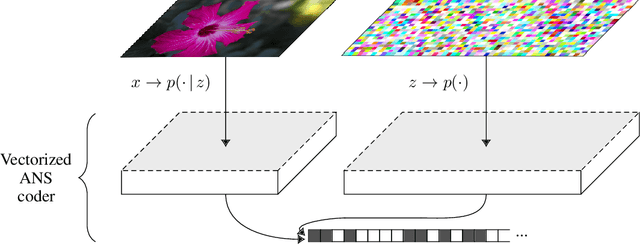
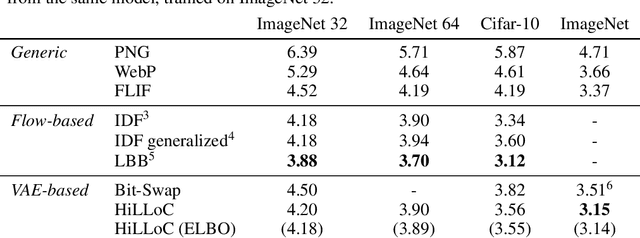
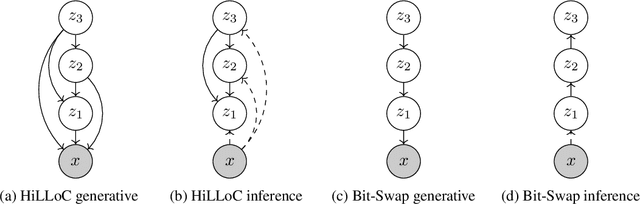
We make the following striking observation: fully convolutional VAE models trained on 32x32 ImageNet can generalize well, not just to 64x64 but also to far larger photographs, with no changes to the model. We use this property, applying fully convolutional models to lossless compression, demonstrating a method to scale the VAE-based 'Bits-Back with ANS' algorithm for lossless compression to large color photographs, and achieving state of the art for compression of full size ImageNet images. We release Craystack, an open source library for convenient prototyping of lossless compression using probabilistic models, along with full implementations of all of our compression results.
Variational f-divergence Minimization
Jul 27, 2019
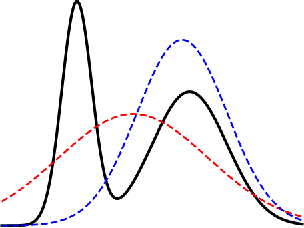

Probabilistic models are often trained by maximum likelihood, which corresponds to minimizing a specific f-divergence between the model and data distribution. In light of recent successes in training Generative Adversarial Networks, alternative non-likelihood training criteria have been proposed. Whilst not necessarily statistically efficient, these alternatives may better match user requirements such as sharp image generation. A general variational method for training probabilistic latent variable models using maximum likelihood is well established; however, how to train latent variable models using other f-divergences is comparatively unknown. We discuss a variational approach that, when combined with the recently introduced Spread Divergence, can be applied to train a large class of latent variable models using any f-divergence.
Gaussian Mean Field Regularizes by Limiting Learned Information
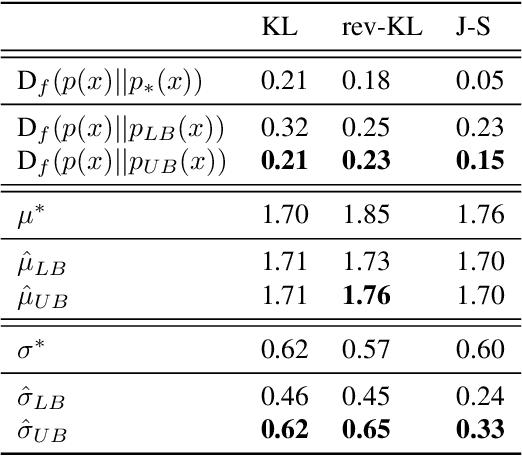
Feb 12, 2019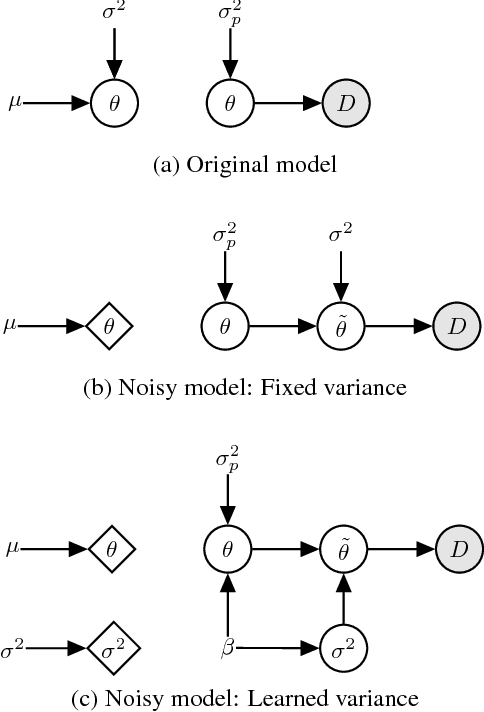
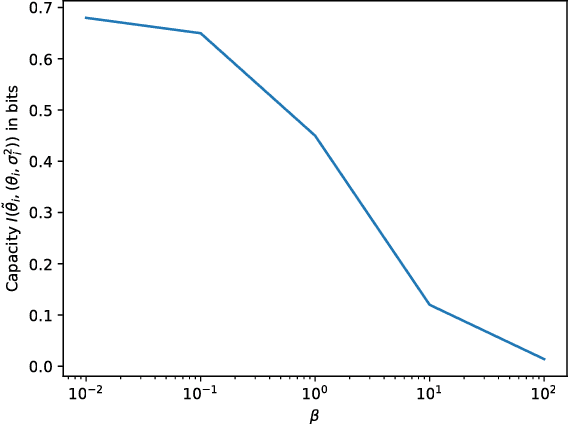
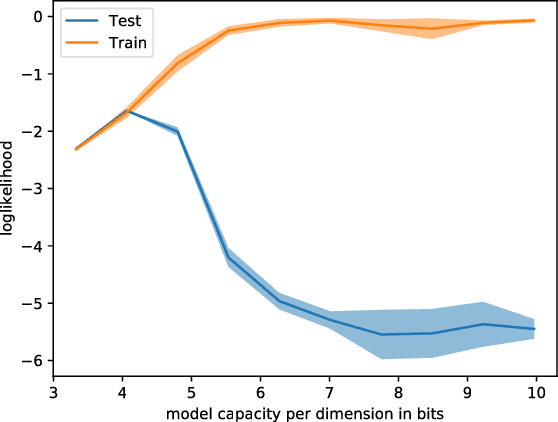
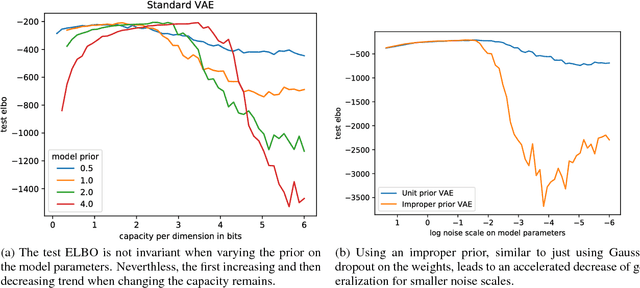
Variational inference with a factorized Gaussian posterior estimate is a widely used approach for learning parameters and hidden variables. Empirically, a regularizing effect can be observed that is poorly understood. In this work, we show how mean field inference improves generalization by limiting mutual information between learned parameters and the data through noise. We quantify a maximum capacity when the posterior variance is either fixed or learned and connect it to generalization error, even when the KL-divergence in the objective is rescaled. Our experiments demonstrate that bounding information between parameters and data effectively regularizes neural networks on both supervised and unsupervised tasks.
Practical Lossless Compression with Latent Variables using Bits Back Coding
Jan 15, 2019
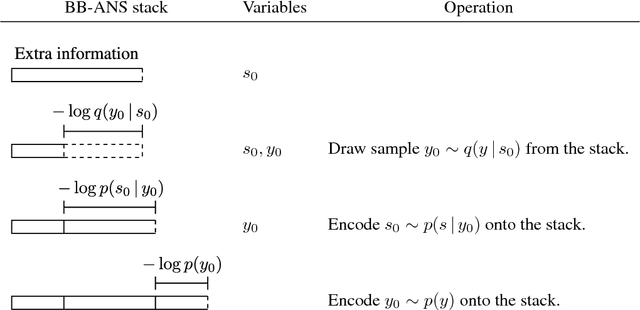

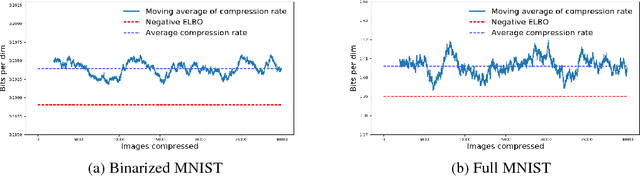
Deep latent variable models have seen recent success in many data domains. Lossless compression is an application of these models which, despite having the potential to be highly useful, has yet to be implemented in a practical manner. We present `Bits Back with ANS' (BB-ANS), a scheme to perform lossless compression with latent variable models at a near optimal rate. We demonstrate this scheme by using it to compress the MNIST dataset with a variational auto-encoder model (VAE), achieving compression rates superior to standard methods with only a simple VAE. Given that the scheme is highly amenable to parallelization, we conclude that with a sufficiently high quality generative model this scheme could be used to achieve substantial improvements in compression rate with acceptable running time. We make our implementation available open source at https://github.com/bits-back/bits-back .
Spread Divergences
Dec 02, 2018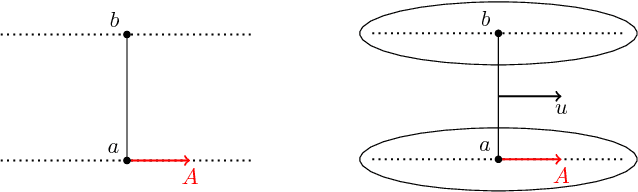


For distributions p and q with different support, the divergence generally will not exist. We define a spread divergence on modified p and q and describe sufficient conditions for the existence of such a divergence. We give examples of using a spread divergence to train implicit generative models, including linear models (Principal Components Analysis and Independent Components Analysis) and non-linear models (Deep Generative Networks).
Modular Networks: Learning to Decompose Neural Computation
Nov 13, 2018
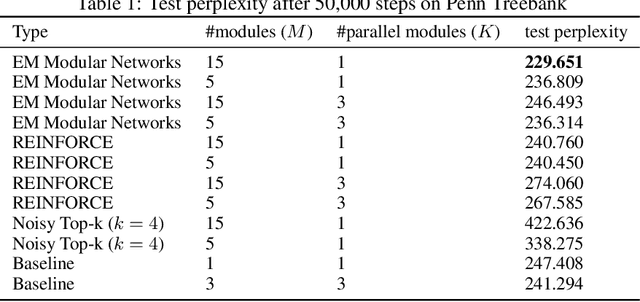
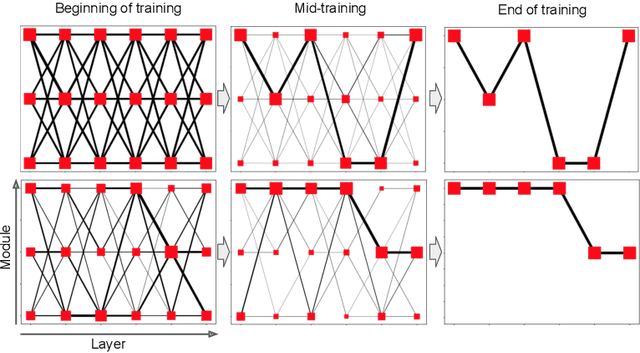

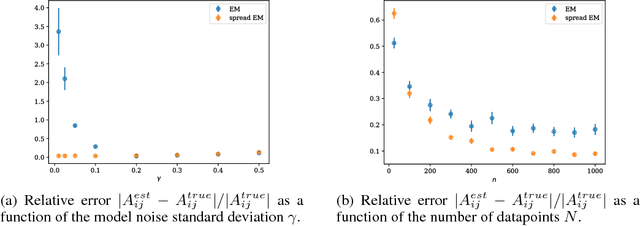
Scaling model capacity has been vital in the success of deep learning. For a typical network, necessary compute resources and training time grow dramatically with model size. Conditional computation is a promising way to increase the number of parameters with a relatively small increase in resources. We propose a training algorithm that flexibly chooses neural modules based on the data to be processed. Both the decomposition and modules are learned end-to-end. In contrast to existing approaches, training does not rely on regularization to enforce diversity in module use. We apply modular networks both to image recognition and language modeling tasks, where we achieve superior performance compared to several baselines. Introspection reveals that modules specialize in interpretable contexts.
Stochastic Variational Optimization
Sep 13, 2018
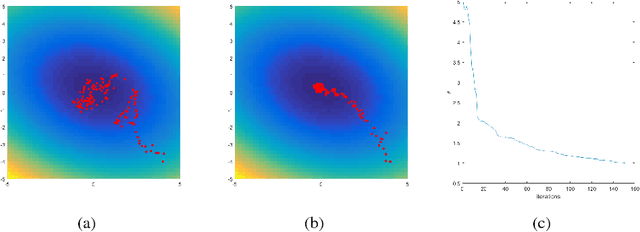
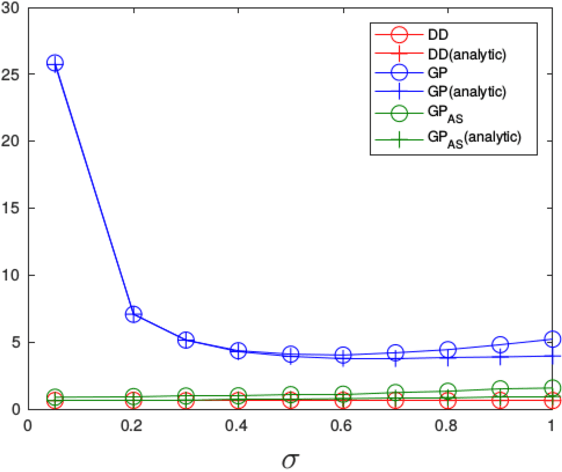
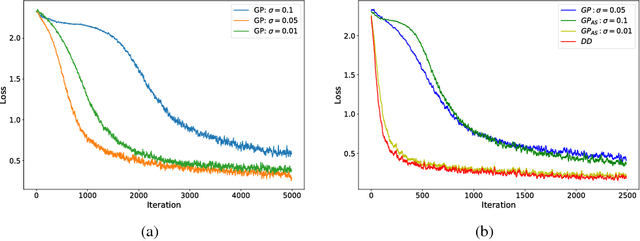
Variational Optimization forms a differentiable upper bound on an objective. We show that approaches such as Natural Evolution Strategies and Gaussian Perturbation, are special cases of Variational Optimization in which the expectations are approximated by Gaussian sampling. These approaches are of particular interest because they are parallelizable. We calculate the approximate bias and variance of the corresponding gradient estimators and demonstrate that using antithetic sampling or a baseline is crucial to mitigate their problems. We contrast these methods with an alternative parallelizable method, namely Directional Derivatives. We conclude that, for differentiable objectives, using Directional Derivatives is preferable to using Variational Optimization to perform parallel Stochastic Gradient Descent.
Tracking by Animation: Unsupervised Learning of Multi-Object Attentive Trackers
Sep 10, 2018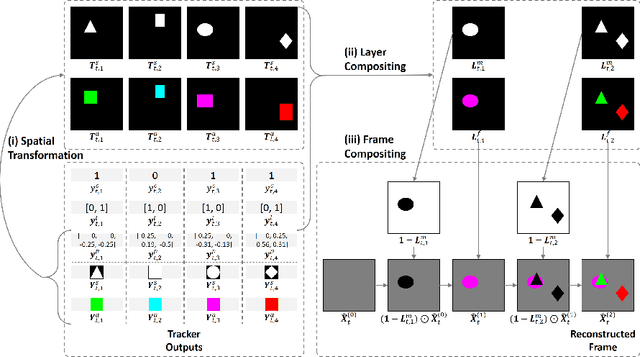
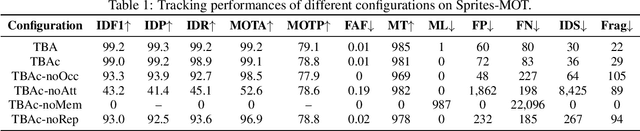
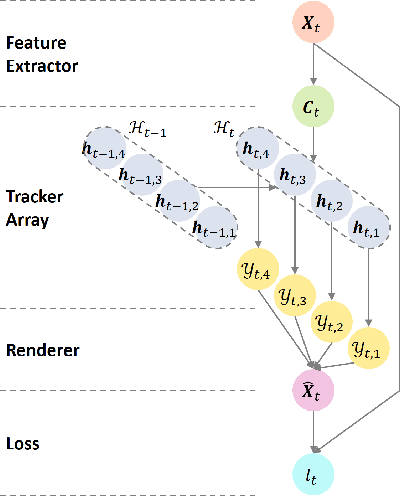
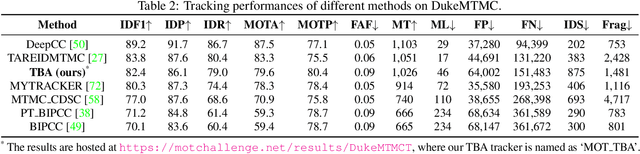
Online Multi-Object Tracking (MOT) from videos is a challenging computer vision task which has been extensively studied for decades. Most of the existing MOT algorithms are based on the Tracking-by-Detection (TBD) paradigm combined with popular machine learning approaches which largely reduce the human effort to tune algorithm parameters. However, the commonly used supervised learning approaches require the labeled data (e.g., bounding boxes), which is expensive for videos. Also, the TBD framework is usually suboptimal since it is not end-to-end, i.e., it considers the task as detection and tracking, but not jointly. To achieve both label-free and end-to-end learning of MOT, we propose a Tracking-by-Animation framework, where a differentiable neural model first tracks objects from input frames and then animates these objects into reconstructed frames. Learning is then driven by the reconstruction error through backpropagation. We further propose a Reprioritized Attentive Tracking to improve the robustness of data association. Experiments conducted on both synthetic and real video datasets show the potential of the proposed model.
Generative Neural Machine Translation
Jun 13, 2018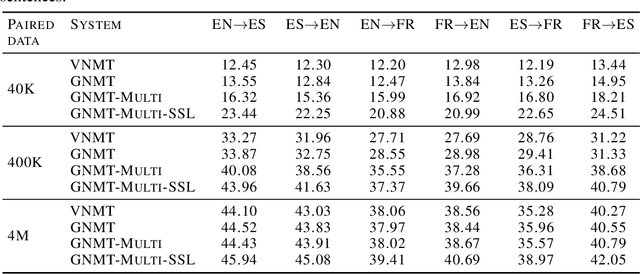



We introduce Generative Neural Machine Translation (GNMT), a latent variable architecture which is designed to model the semantics of the source and target sentences. We modify an encoder-decoder translation model by adding a latent variable as a language agnostic representation which is encouraged to learn the meaning of the sentence. GNMT achieves competitive BLEU scores on pure translation tasks, and is superior when there are missing words in the source sentence. We augment the model to facilitate multilingual translation and semi-supervised learning without adding parameters. This framework significantly reduces overfitting when there is limited paired data available, and is effective for translating between pairs of languages not seen during training.
Generating Sentences Using a Dynamic Canvas
Jun 13, 2018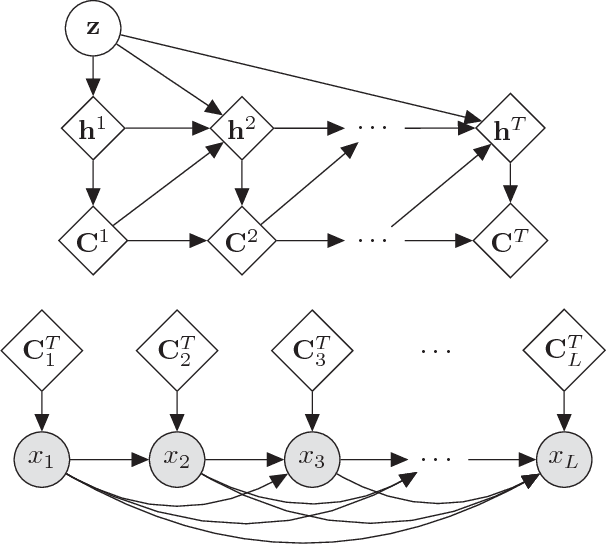
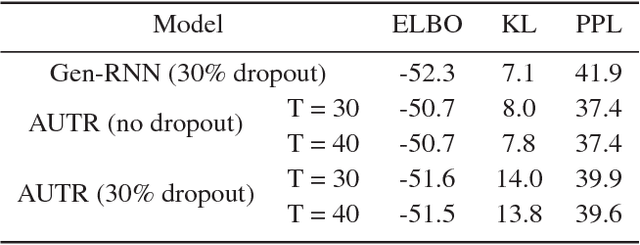


We introduce the Attentive Unsupervised Text (W)riter (AUTR), which is a word level generative model for natural language. It uses a recurrent neural network with a dynamic attention and canvas memory mechanism to iteratively construct sentences. By viewing the state of the memory at intermediate stages and where the model is placing its attention, we gain insight into how it constructs sentences. We demonstrate that AUTR learns a meaningful latent representation for each sentence, and achieves competitive log-likelihood lower bounds whilst being computationally efficient. It is effective at generating and reconstructing sentences, as well as imputing missing words.