 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing
Jan 05, 2021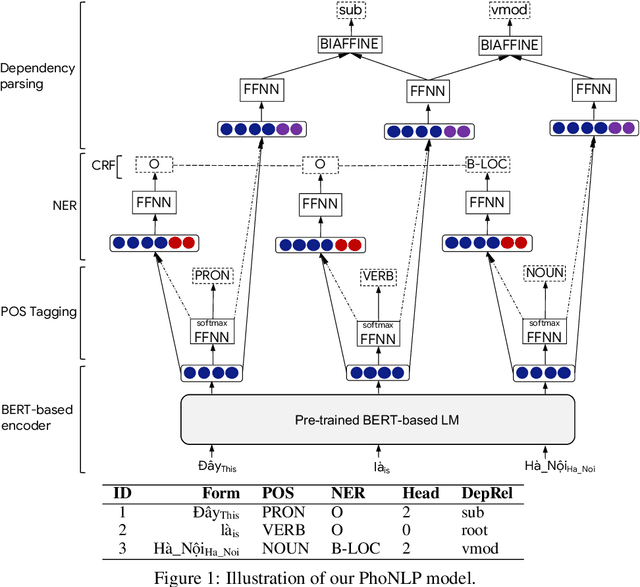
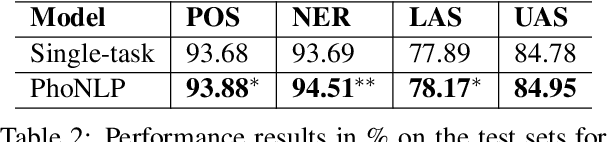

We present the first multi-task learning model -- named PhoNLP -- for joint Vietnamese part-of-speech tagging, named entity recognition and dependency parsing. Experiments on Vietnamese benchmark datasets show that PhoNLP produces state-of-the-art results, outperforming a single-task learning approach that fine-tunes the pre-trained Vietnamese language model PhoBERT (Nguyen and Nguyen, 2020) for each task independently. We publicly release PhoNLP as an open-source toolkit under the MIT License. We hope that PhoNLP can serve as a strong baseline and useful toolkit for future research and applications in Vietnamese NLP. Our PhoNLP is available at https://github.com/VinAIResearch/PhoNLP
WNUT-2020 Task 2: Identification of Informative COVID-19 English Tweets
Oct 16, 2020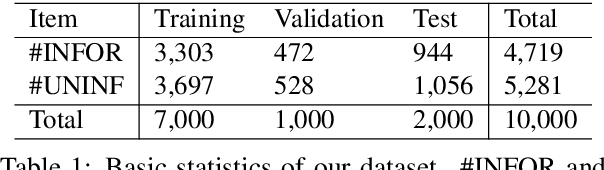
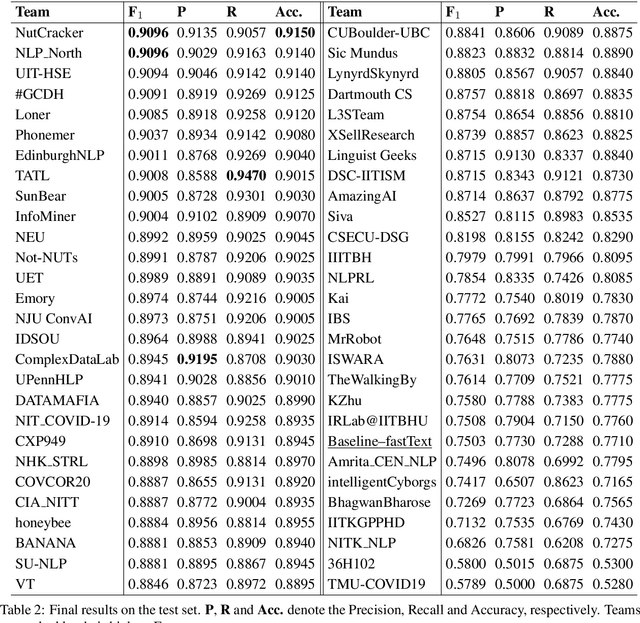
In this paper, we provide an overview of the WNUT-2020 shared task on the identification of informative COVID-19 English Tweets. We describe how we construct a corpus of 10K Tweets and organize the development and evaluation phases for this task. In addition, we also present a brief summary of results obtained from the final system evaluation submissions of 55 teams, finding that (i) many systems obtain very high performance, up to 0.91 F1 score, (ii) the majority of the submissions achieve substantially higher results than the baseline fastText (Joulin et al., 2017), and (iii) fine-tuning pre-trained language models on relevant language data followed by supervised training performs well in this task.
A Pilot Study of Text-to-SQL Semantic Parsing for Vietnamese
Oct 05, 2020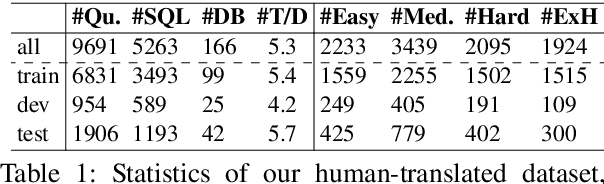
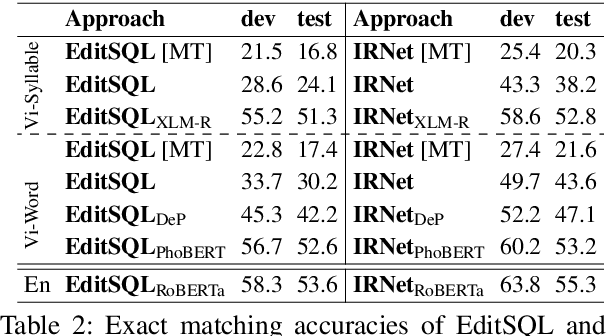
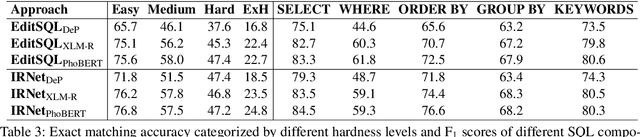
Semantic parsing is an important NLP task. However, Vietnamese is a low-resource language in this research area. In this paper, we present the first public large-scale Text-to-SQL semantic parsing dataset for Vietnamese. We extend and evaluate two strong semantic parsing baselines EditSQL (Zhang et al., 2019) and IRNet (Guo et al., 2019) on our dataset. We compare the two baselines with key configurations and find that: automatic Vietnamese word segmentation improves the parsing results of both baselines; the normalized pointwise mutual information (NPMI) score (Bouma, 2009) is useful for schema linking; latent syntactic features extracted from a neural dependency parser for Vietnamese also improve the results; and the monolingual language model PhoBERT for Vietnamese (Nguyen and Nguyen, 2020) helps produce higher performances than the recent best multilingual language model XLM-R (Conneau et al., 2020).
A Label Attention Model for ICD Coding from Clinical Text
Jul 13, 2020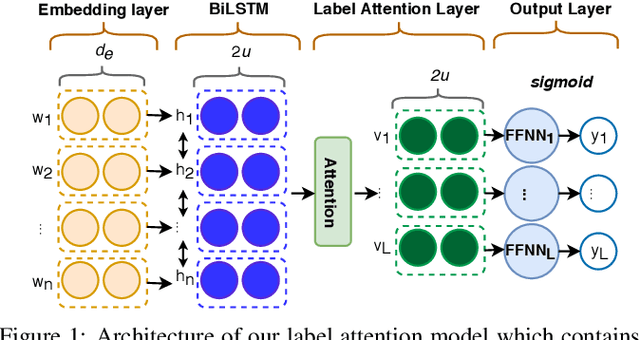
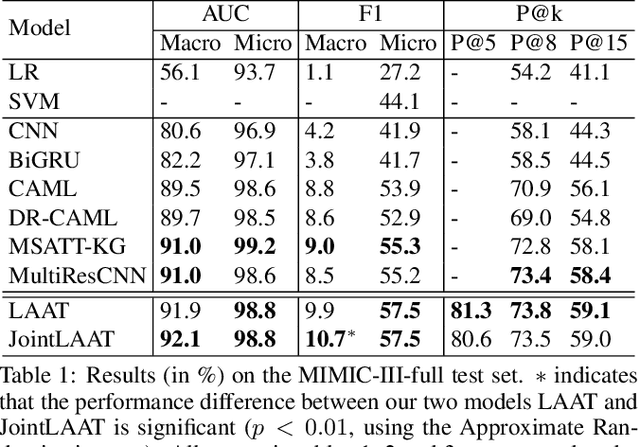
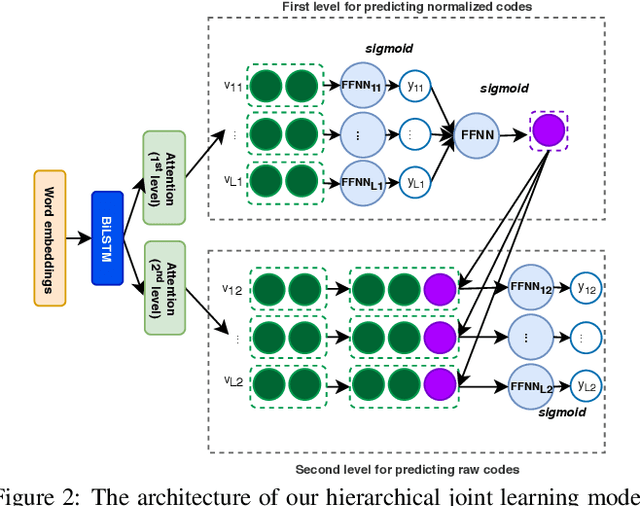
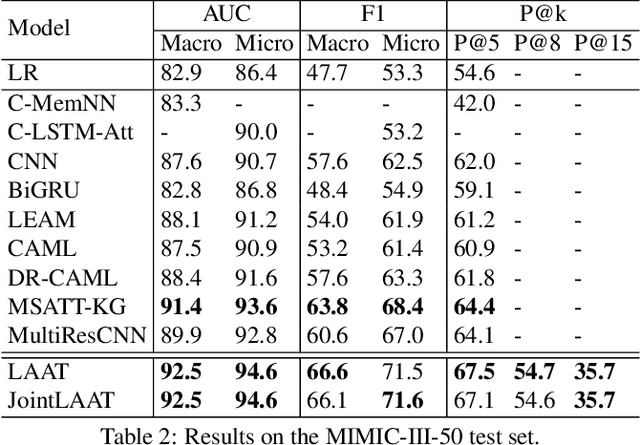
ICD coding is a process of assigning the International Classification of Disease diagnosis codes to clinical/medical notes documented by health professionals (e.g. clinicians). This process requires significant human resources, and thus is costly and prone to error. To handle the problem, machine learning has been utilized for automatic ICD coding. Previous state-of-the-art models were based on convolutional neural networks, using a single/several fixed window sizes. However, the lengths and interdependence between text fragments related to ICD codes in clinical text vary significantly, leading to the difficulty of deciding what the best window sizes are. In this paper, we propose a new label attention model for automatic ICD coding, which can handle both the various lengths and the interdependence of the ICD code related text fragments. Furthermore, as the majority of ICD codes are not frequently used, leading to the extremely imbalanced data issue, we additionally propose a hierarchical joint learning mechanism extending our label attention model to handle the issue, using the hierarchical relationships among the codes. Our label attention model achieves new state-of-the-art results on three benchmark MIMIC datasets, and the joint learning mechanism helps improve the performances for infrequent codes.
BERTweet: A pre-trained language model for English Tweets
May 20, 2020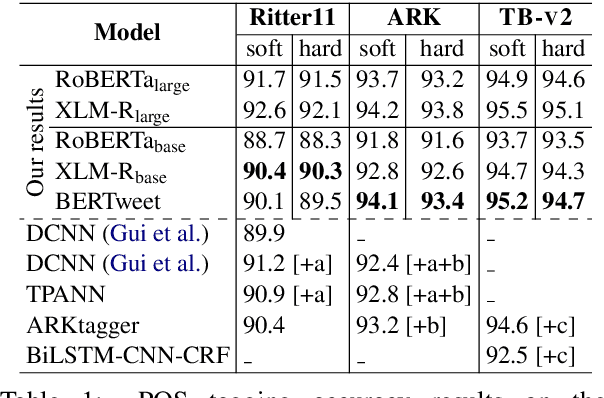
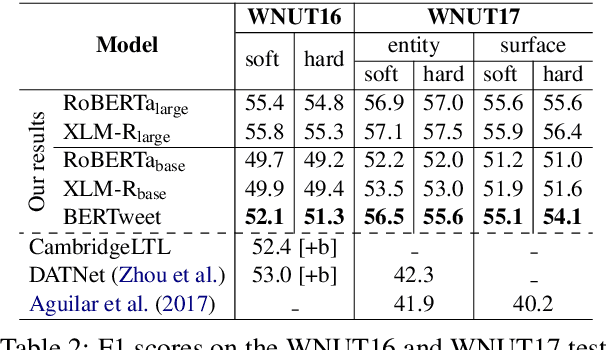
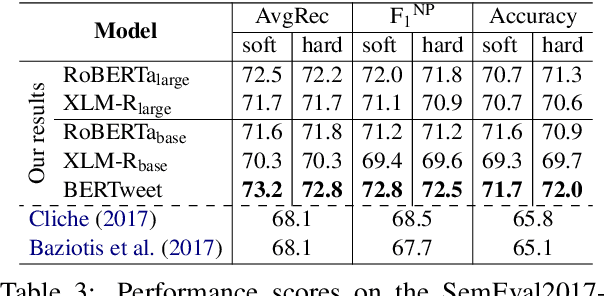
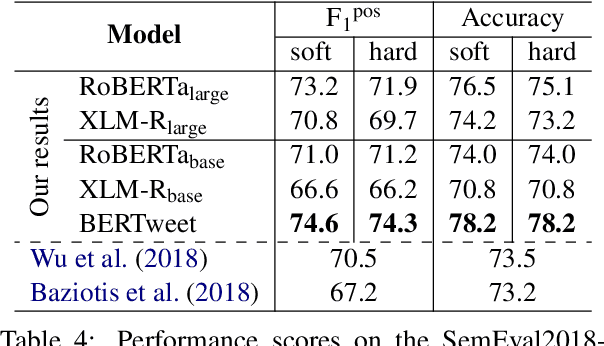
We present BERTweet, the first public large-scale pre-trained language model for English Tweets. Our BERTweet is trained using the RoBERTa pre-training procedure (Liu et al., 2019), with the same model configuration as BERT-base (Devlin et al., 2019). Experiments show that BERTweet outperforms strong baselines RoBERTa-base and XLM-R-base (Conneau et al., 2020), producing better performance results than the previous state-of-the-art models on three Tweet NLP tasks: Part-of-speech tagging, Named-entity recognition and text classification. We release BERTweet to facilitate future research and downstream applications on Tweet data. Our BERTweet is available at: https://github.com/VinAIResearch/BERTweet
PhoBERT: Pre-trained language models for Vietnamese
Mar 02, 2020
We present PhoBERT with two versions of "base" and "large"--the first public large-scale monolingual language models pre-trained for Vietnamese. We show that PhoBERT improves the state-of-the-art in multiple Vietnamese-specific NLP tasks including Part-of-speech tagging, Named-entity recognition and Natural language inference. We release PhoBERT to facilitate future research and downstream applications for Vietnamese NLP. Our PhoBERT is released at: https://github.com/VinAIResearch/PhoBERT
A Vietnamese Text-Based Conversational Agent
Nov 26, 2019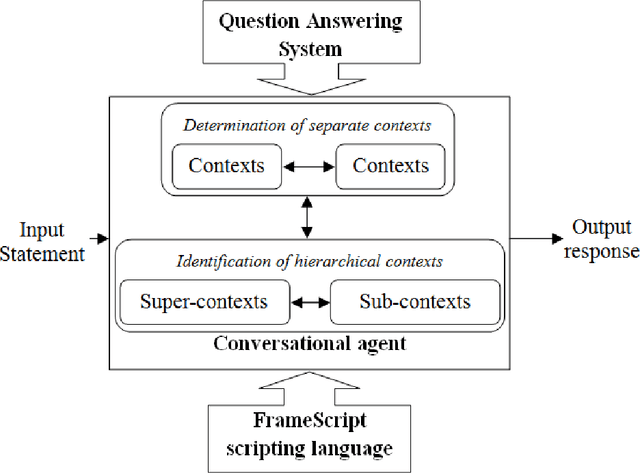


This paper introduces a Vietnamese text-based conversational agent architecture on specific knowledge domain which is integrated in a question answering system. When the question answering system fails to provide answers to users' input, our conversational agent can step in to interact with users to provide answers to users. Experimental results are promising where our Vietnamese text-based conversational agent achieves positive feedback in a study conducted in the university academic regulation domain.
A Vietnamese Question Answering System
Nov 26, 2019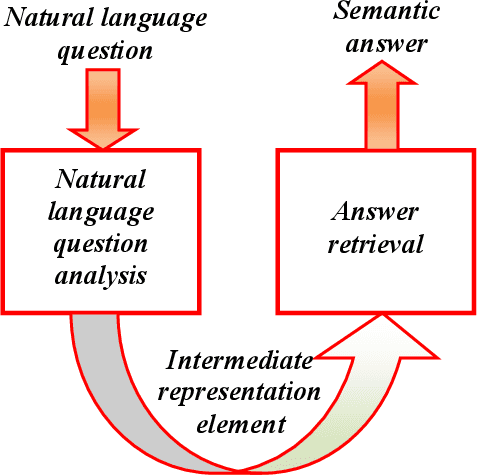
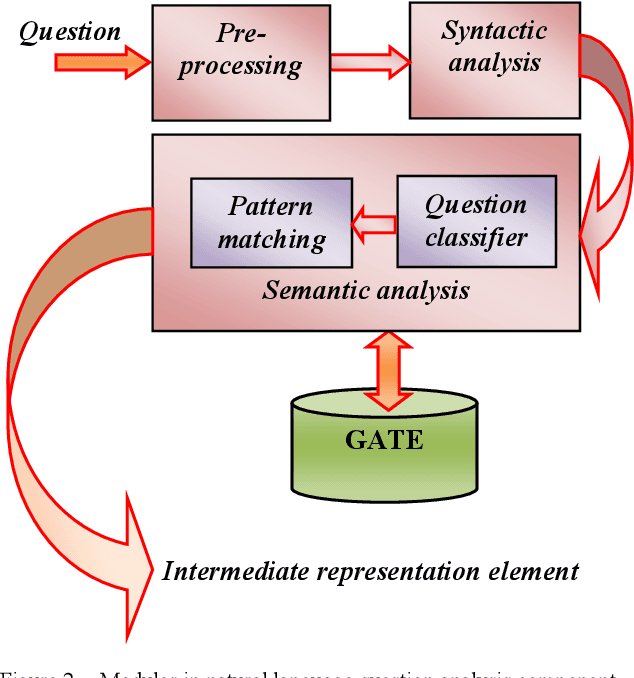
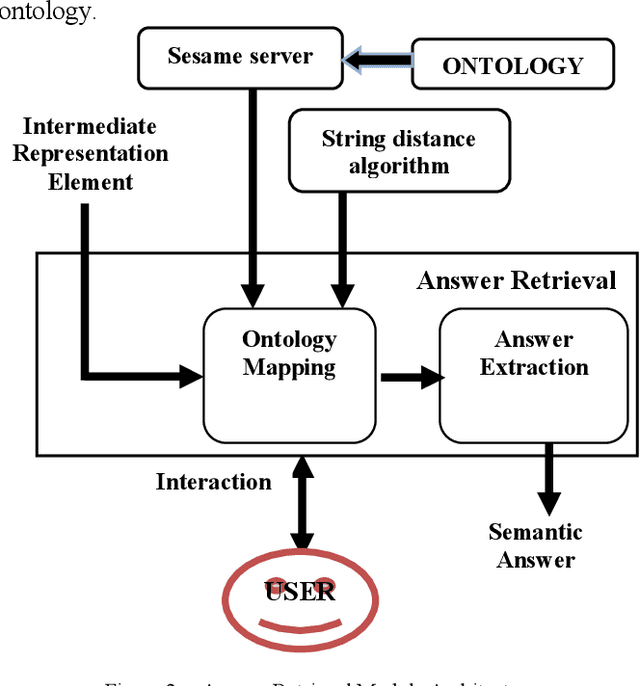
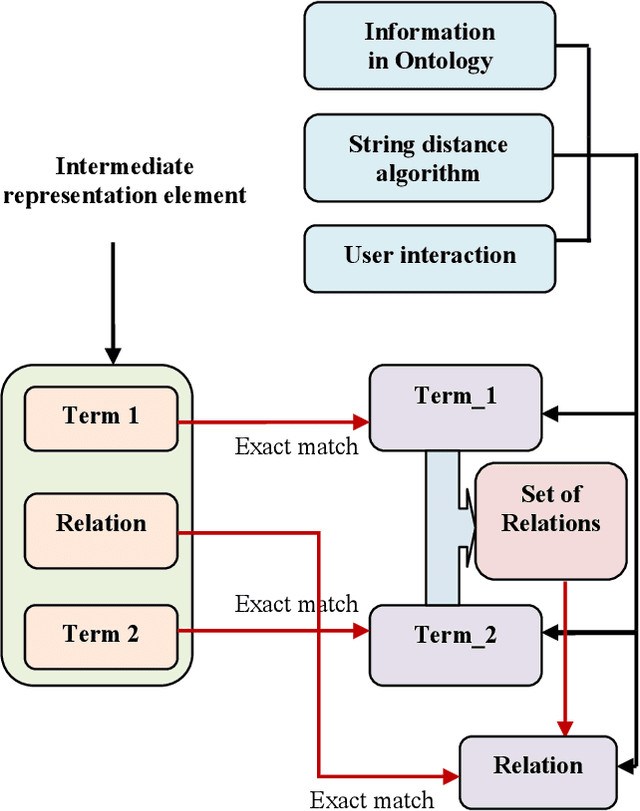
Question answering systems aim to produce exact answers to users' questions instead of a list of related documents as used by current search engines. In this paper, we propose an ontology-based Vietnamese question answering system that allows users to express their questions in natural language. To the best of our knowledge, this is the first attempt to enable users to query an ontological knowledge base using Vietnamese natural language. Experiments of our system on an organizational ontology show promising results.
A Capsule Network-based Model for Learning Node Embeddings
Nov 12, 2019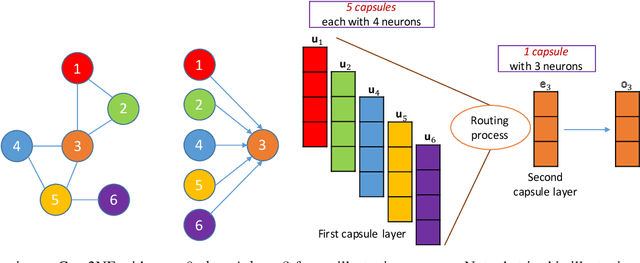
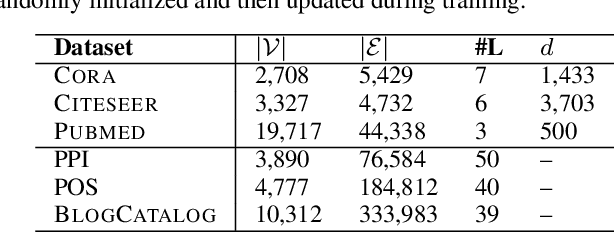
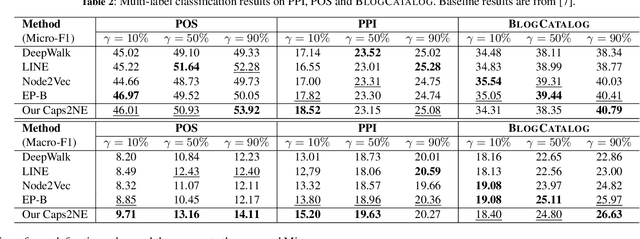
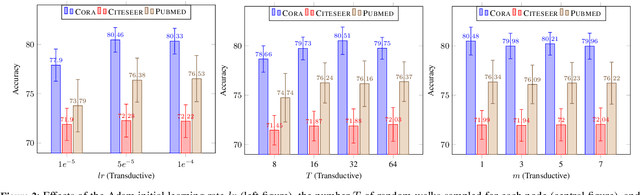
In this paper, we focus on learning low-dimensional embeddings of entity nodes from graph-structured data, where we can use the learned node embeddings for a downstream task of node classification. Existing node embedding models often suffer from a limitation of exploiting graph information to infer plausible embeddings of unseen nodes. To address this issue, we propose Caps2NE---a new unsupervised embedding model using a network of two capsule layers. Given a target node and its context nodes, Caps2NE applies a routing process to aggregate features of the context nodes at the first capsule layer, then feed these features into the second capsule layer to produce an embedding vector. This embedding vector is then used to infer a plausible embedding for the target node. Experimental results for the node classification task on six well-known benchmark datasets show that our Caps2NE obtains state-of-the-art performances.
Improving Chemical Named Entity Recognition in Patents with Contextualized Word Embeddings
Jul 05, 2019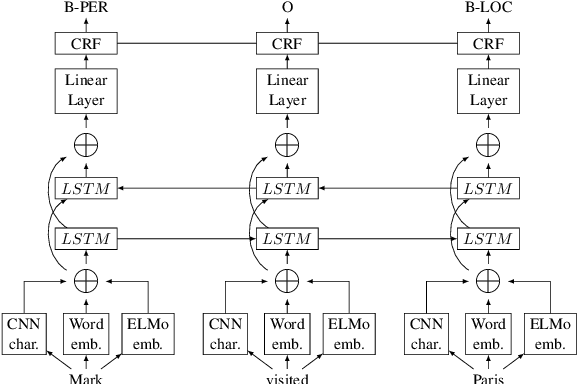
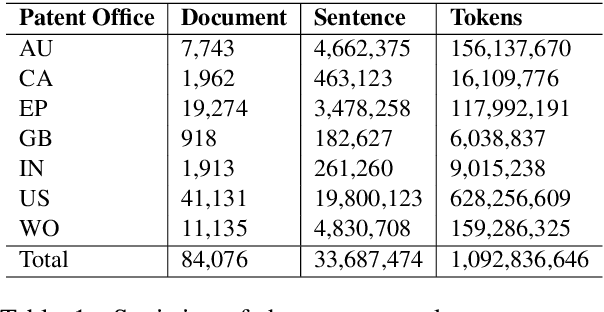

Chemical patents are an important resource for chemical information. However, few chemical Named Entity Recognition (NER) systems have been evaluated on patent documents, due in part to their structural and linguistic complexity. In this paper, we explore the NER performance of a BiLSTM-CRF model utilising pre-trained word embeddings, character-level word representations and contextualized ELMo word representations for chemical patents. We compare word embeddings pre-trained on biomedical and chemical patent corpora. The effect of tokenizers optimized for the chemical domain on NER performance in chemical patents is also explored. The results on two patent corpora show that contextualized word representations generated from ELMo substantially improve chemical NER performance w.r.t. the current state-of-the-art. We also show that domain-specific resources such as word embeddings trained on chemical patents and chemical-specific tokenizers have a positive impact on NER performance.