 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Prompting Strategies for Multi-Label Recognition with Partial Annotations
Sep 12, 2024



Vision-language models (VLMs) like CLIP have been adapted for Multi-Label Recognition (MLR) with partial annotations by leveraging prompt-learning, where positive and negative prompts are learned for each class to associate their embeddings with class presence or absence in the shared vision-text feature space. While this approach improves MLR performance by relying on VLM priors, we hypothesize that learning negative prompts may be suboptimal, as the datasets used to train VLMs lack image-caption pairs explicitly focusing on class absence. To analyze the impact of positive and negative prompt learning on MLR, we introduce PositiveCoOp and NegativeCoOp, where only one prompt is learned with VLM guidance while the other is replaced by an embedding vector learned directly in the shared feature space without relying on the text encoder. Through empirical analysis, we observe that negative prompts degrade MLR performance, and learning only positive prompts, combined with learned negative embeddings (PositiveCoOp), outperforms dual prompt learning approaches. Moreover, we quantify the performance benefits that prompt-learning offers over a simple vision-features-only baseline, observing that the baseline displays strong performance comparable to dual prompt learning approach (DualCoOp), when the proportion of missing labels is low, while requiring half the training compute and 16 times fewer parameters
Potential Field Based Deep Metric Learning
May 28, 2024Deep metric learning (DML) involves training a network to learn a semantically meaningful representation space. Many current approaches mine n-tuples of examples and model interactions within each tuplets. We present a novel, compositional DML model, inspired by electrostatic fields in physics that, instead of in tuples, represents the influence of each example (embedding) by a continuous potential field, and superposes the fields to obtain their combined global potential field. We use attractive/repulsive potential fields to represent interactions among embeddings from images of the same/different classes. Contrary to typical learning methods, where mutual influence of samples is proportional to their distance, we enforce reduction in such influence with distance, leading to a decaying field. We show that such decay helps improve performance on real world datasets with large intra-class variations and label noise. Like other proxy-based methods, we also use proxies to succinctly represent sub-populations of examples. We evaluate our method on three standard DML benchmarks- Cars-196, CUB-200-2011, and SOP datasets where it outperforms state-of-the-art baselines.
Improving Multi-label Recognition using Class Co-Occurrence Probabilities
Apr 24, 2024



Multi-label Recognition (MLR) involves the identification of multiple objects within an image. To address the additional complexity of this problem, recent works have leveraged information from vision-language models (VLMs) trained on large text-images datasets for the task. These methods learn an independent classifier for each object (class), overlooking correlations in their occurrences. Such co-occurrences can be captured from the training data as conditional probabilities between a pair of classes. We propose a framework to extend the independent classifiers by incorporating the co-occurrence information for object pairs to improve the performance of independent classifiers. We use a Graph Convolutional Network (GCN) to enforce the conditional probabilities between classes, by refining the initial estimates derived from image and text sources obtained using VLMs. We validate our method on four MLR datasets, where our approach outperforms all state-of-the-art methods.
Piecewise-Linear Manifolds for Deep Metric Learning
Mar 22, 2024Unsupervised deep metric learning (UDML) focuses on learning a semantic representation space using only unlabeled data. This challenging problem requires accurately estimating the similarity between data points, which is used to supervise a deep network. For this purpose, we propose to model the high-dimensional data manifold using a piecewise-linear approximation, with each low-dimensional linear piece approximating the data manifold in a small neighborhood of a point. These neighborhoods are used to estimate similarity between data points. We empirically show that this similarity estimate correlates better with the ground truth than the similarity estimates of current state-of-the-art techniques. We also show that proxies, commonly used in supervised metric learning, can be used to model the piecewise-linear manifold in an unsupervised setting, helping improve performance. Our method outperforms existing unsupervised metric learning approaches on standard zero-shot image retrieval benchmarks.
Long-Distance Gesture Recognition using Dynamic Neural Networks
Aug 09, 2023



Gestures form an important medium of communication between humans and machines. An overwhelming majority of existing gesture recognition methods are tailored to a scenario where humans and machines are located very close to each other. This short-distance assumption does not hold true for several types of interactions, for example gesture-based interactions with a floor cleaning robot or with a drone. Methods made for short-distance recognition are unable to perform well on long-distance recognition due to gestures occupying only a small portion of the input data. Their performance is especially worse in resource constrained settings where they are not able to effectively focus their limited compute on the gesturing subject. We propose a novel, accurate and efficient method for the recognition of gestures from longer distances. It uses a dynamic neural network to select features from gesture-containing spatial regions of the input sensor data for further processing. This helps the network focus on features important for gesture recognition while discarding background features early on, thus making it more compute efficient compared to other techniques. We demonstrate the performance of our method on the LD-ConGR long-distance dataset where it outperforms previous state-of-the-art methods on recognition accuracy and compute efficiency.
Memory Efficient Adaptive Attention For Multiple Domain Learning
Oct 21, 2021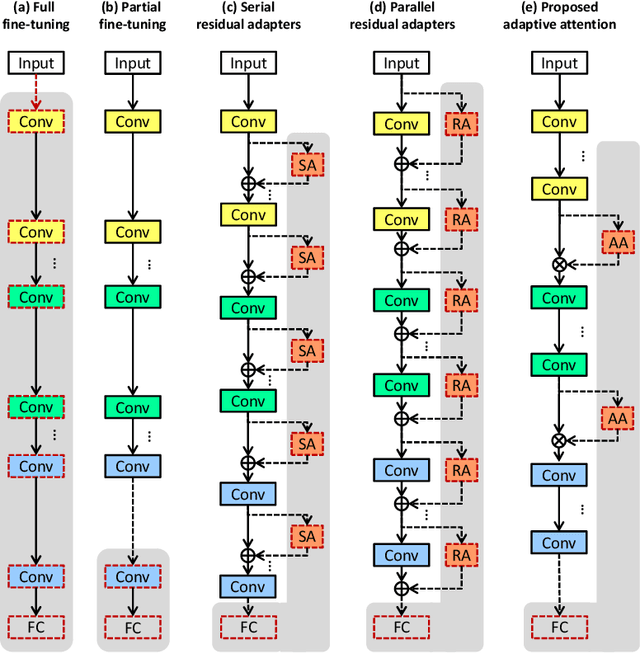
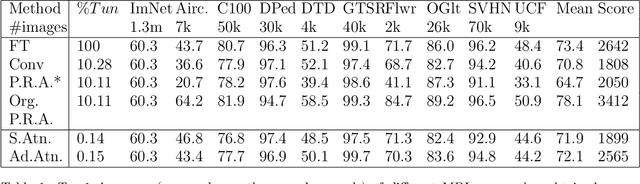


Training CNNs from scratch on new domains typically demands large numbers of labeled images and computations, which is not suitable for low-power hardware. One way to reduce these requirements is to modularize the CNN architecture and freeze the weights of the heavier modules, that is, the lower layers after pre-training. Recent studies have proposed alternative modular architectures and schemes that lead to a reduction in the number of trainable parameters needed to match the accuracy of fully fine-tuned CNNs on new domains. Our work suggests that a further reduction in the number of trainable parameters by an order of magnitude is possible. Furthermore, we propose that new modularization techniques for multiple domain learning should also be compared on other realistic metrics, such as the number of interconnections needed between the fixed and trainable modules, the number of training samples needed, the order of computations required and the robustness to partial mislabeling of the training data. On all of these criteria, the proposed architecture demonstrates advantages over or matches the current state-of-the-art.
PAL : Pretext-based Active Learning
Oct 29, 2020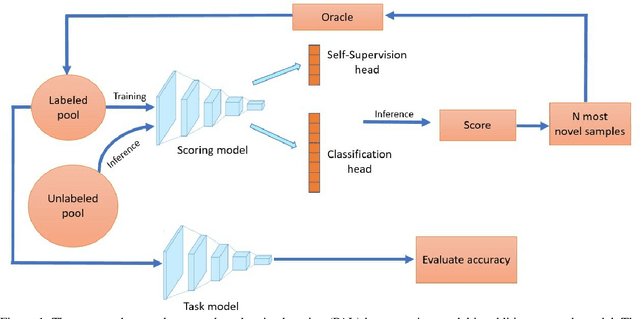
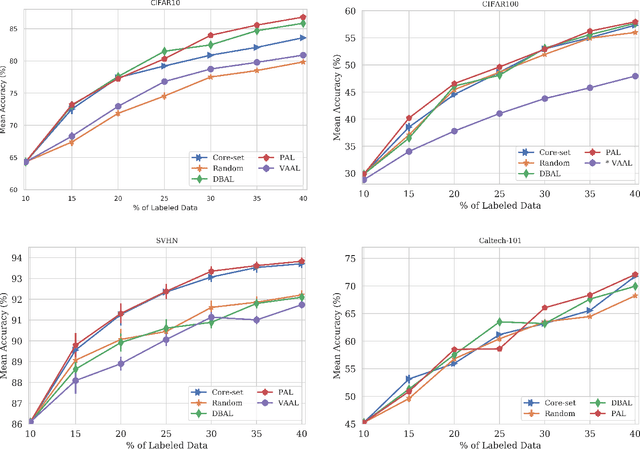
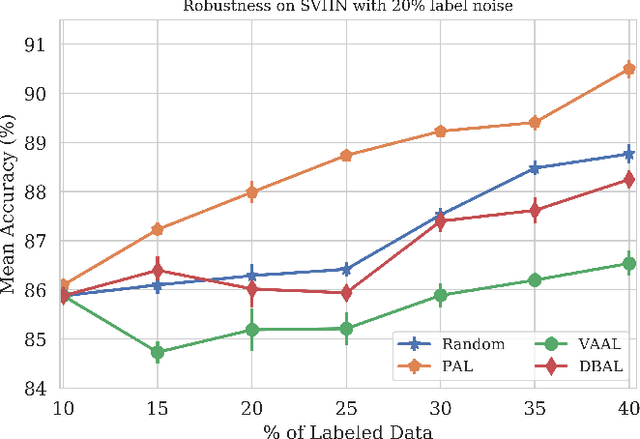
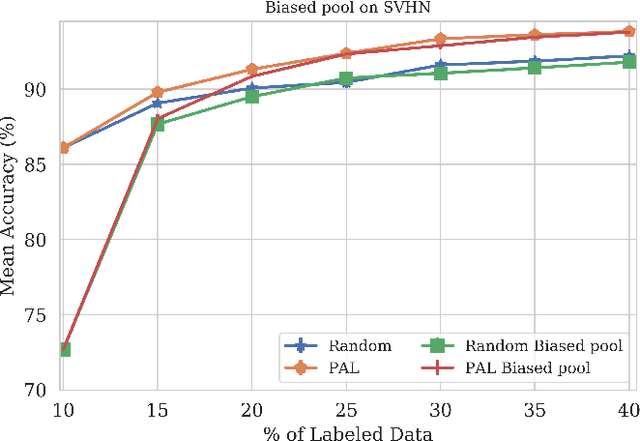
When obtaining labels is expensive, the requirement of a large labeled training data set for deep learning can be mitigated by active learning. Active learning refers to the development of algorithms to judiciously pick limited subsets of unlabeled samples that can be sent for labeling by an oracle. We propose an intuitive active learning technique that, in addition to the task neural network (e.g., for classification), uses an auxiliary self-supervised neural network that assesses the utility of an unlabeled sample for inclusion in the labeled set. Our core idea is that the difficulty of the auxiliary network trained on labeled samples to solve a self-supervision task on an unlabeled sample represents the utility of obtaining the label of that unlabeled sample. Specifically, we assume that an unlabeled image on which the precision of predicting a random applied geometric transform is low must be out of the distribution represented by the current set of labeled images. These images will therefore maximize the relative information gain when labeled by the oracle. We also demonstrate that augmenting the auxiliary network with task specific training further improves the results. We demonstrate strong performance on a range of widely used datasets and establish a new state of the art for active learning. We also make our code publicly available to encourage further research.
QR code denoising using parallel Hopfield networks
Dec 12, 2018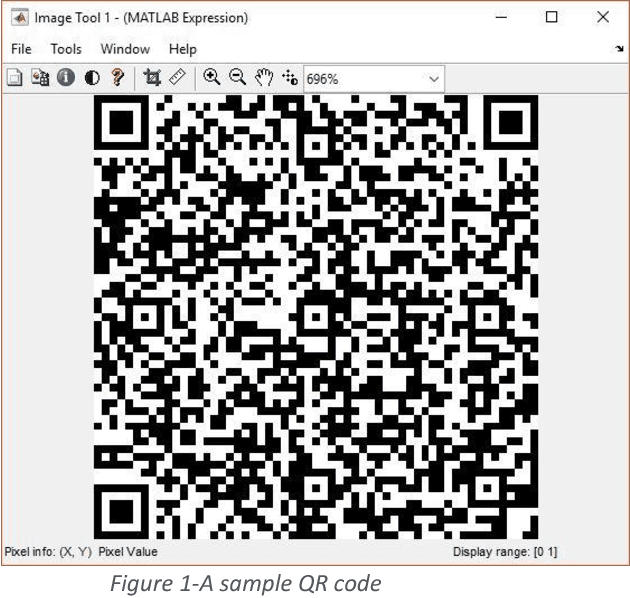
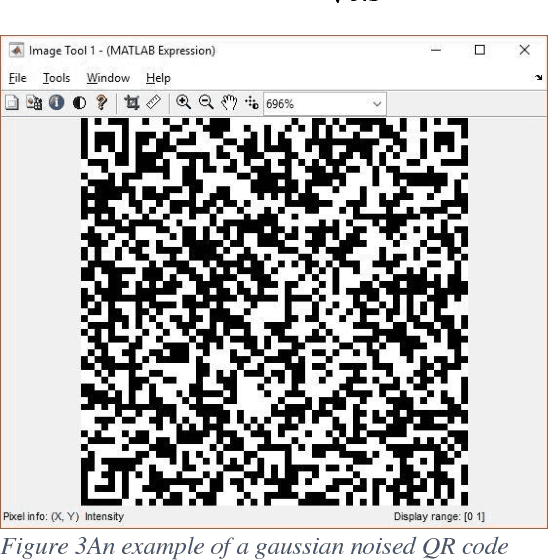
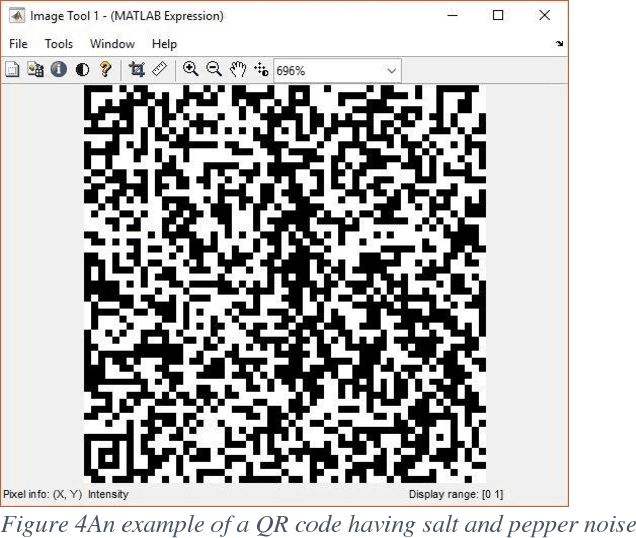
We propose a novel algorithm for using Hopfield networks to denoise QR codes. Hopfield networks have mostly been used as a noise tolerant memory or to solve difficult combinatorial problems. One of the major drawbacks in their use in noise tolerant associative memory is their low capacity of storage, scaling only linearly with the number of nodes in the network. A larger capacity therefore requires a larger number of nodes, thereby reducing the speed of convergence of the network in addition to increasing hardware costs for acquiring more precise data to be fed to a larger number of nodes. Our paper proposes a new algorithm to allow the use of several Hopfield networks in parallel thereby increasing the cumulative storage capacity of the system many times as compared to a single Hopfield network. Our algorithm would also be much faster than a larger single Hopfield network with the same total capacity. This enables their use in applications like denoising QR codes, which we have demonstrated in our paper. We then test our network on a large set of QR code images with different types of noise and demonstrate that such a system of Hopfield networks can be used to denoise and recognize QR codes in real time.