 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Crossover of Neural Networks Through Neuron Alignment
Mar 24, 2020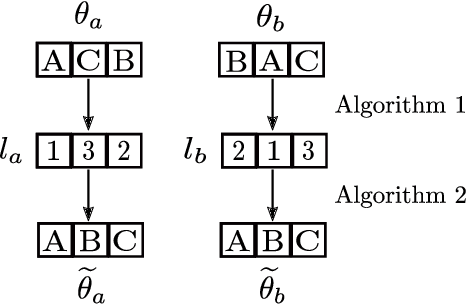
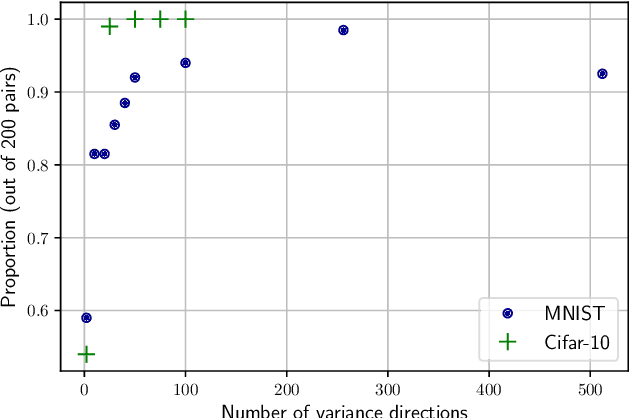
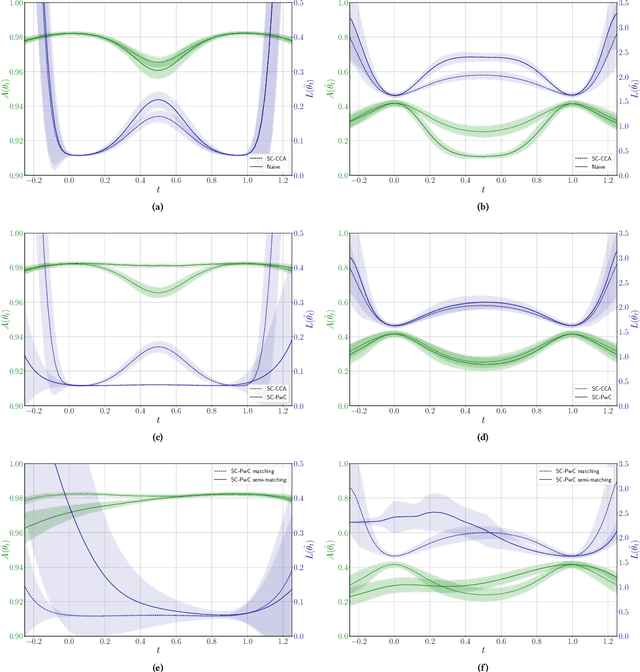

One of the main and largely unexplored challenges in evolving the weights of neural networks using genetic algorithms is to find a sensible crossover operation between parent networks. Indeed, naive crossover leads to functionally damaged offspring that do not retain information from the parents. This is because neural networks are invariant to permutations of neurons, giving rise to multiple ways of representing the same solution. This is often referred to as the competing conventions problem. In this paper, we propose a two-step safe crossover(SC) operator. First, the neurons of the parents are functionally aligned by computing how well they correlate, and only then are the parents recombined. We compare two ways of measuring relationships between neurons: Pairwise Correlation (PwC) and Canonical Correlation Analysis (CCA). We test our safe crossover operators (SC-PwC and SC-CCA) on MNIST and CIFAR-10 by performing arithmetic crossover on the weights of feed-forward neural network pairs. We show that it effectively transmits information from parents to offspring and significantly improves upon naive crossover. Our method is computationally fast,can serve as a way to explore the fitness landscape more efficiently and makes safe crossover a potentially promising operator in future neuroevolution research and applications.
Real-Time Optimal Guidance and Control for Interplanetary Transfers Using Deep Networks
Feb 20, 2020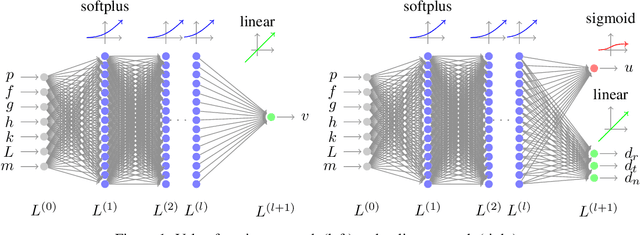

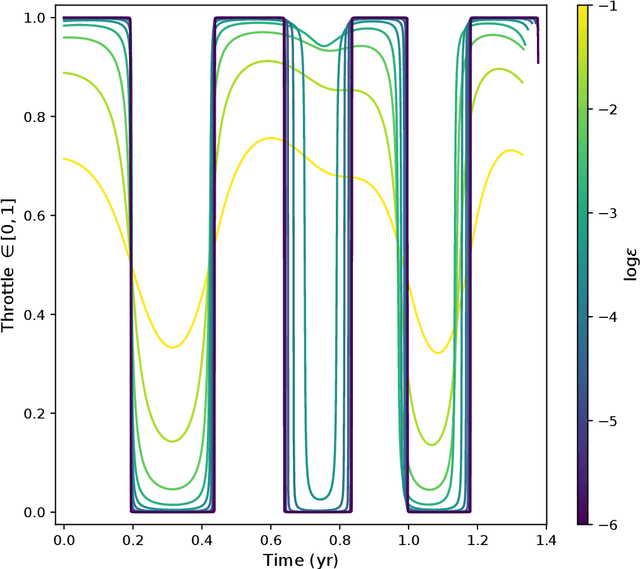

We consider the Earth-Venus mass-optimal interplanetary transfer of a low-thrust spacecraft and show how the optimal guidance can be represented by deep networks in a large portion of the state space and to a high degree of accuracy. Imitation (supervised) learning of optimal examples is used as a network training paradigm. The resulting models are suitable for an on-board, real-time, implementation of the optimal guidance and control system of the spacecraft and are called G&CNETs. A new general methodology called Backward Generation of Optimal Examples is introduced and shown to be able to efficiently create all the optimal state action pairs necessary to train G&CNETs without solving optimal control problems. With respect to previous works, we are able to produce datasets containing a few orders of magnitude more optimal trajectories and obtain network performances compatible with real missions requirements. Several schemes able to train representations of either the optimal policy (thrust profile) or the value function (optimal mass) are proposed and tested. We find that both policy learning and value function learning successfully and accurately learn the optimal thrust and that a spacecraft employing the learned thrust is able to reach the target conditions orbit spending only 2 permil more propellant than in the corresponding mathematically optimal transfer. Moreover, the optimal propellant mass can be predicted (in case of value function learning) within an error well within 1%. All G&CNETs produced are tested during simulations of interplanetary transfers with respect to their ability to reach the target conditions optimally starting from nominal and off-nominal conditions.
Aggressive Online Control of a Quadrotor via Deep Network Representations of Optimality Principles
Dec 15, 2019
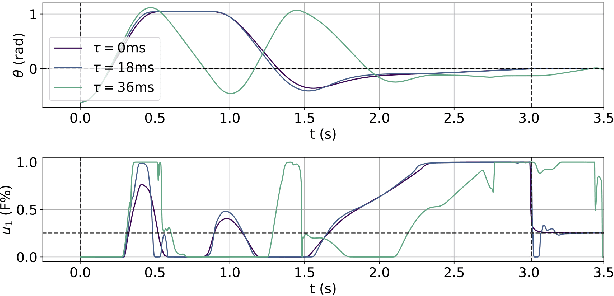
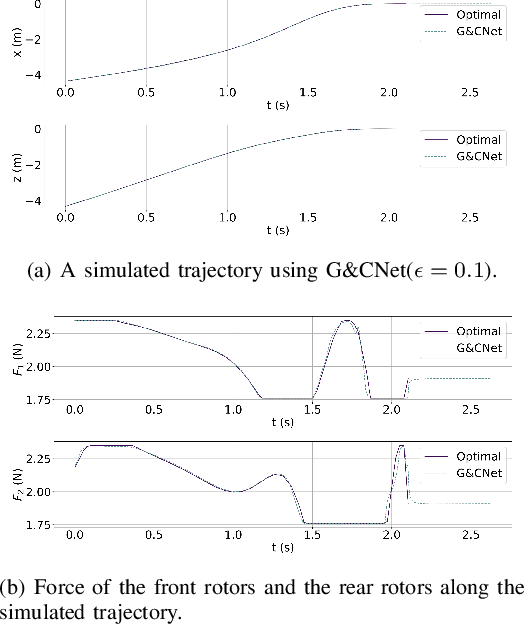
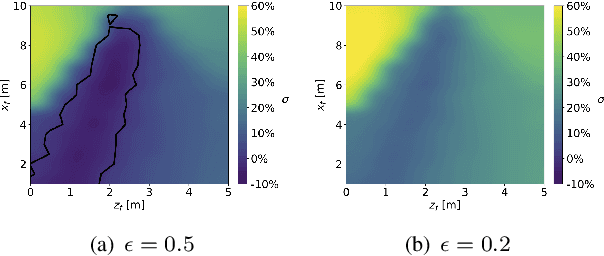
Optimal control holds great potential to improve a variety of robotic applications. The application of optimal control on-board limited platforms has been severely hindered by the large computational requirements of current state of the art implementations. In this work, we make use of a deep neural network to directly map the robot states to control actions. The network is trained offline to imitate the optimal control computed by a time consuming direct nonlinear method. A mixture of time optimality and power optimality is considered with a continuation parameter used to select the predominance of each objective. We apply our networks (termed G\&CNets) to aggressive quadrotor control, first in simulation and then in the real world. We give insight into the factors that influence the `reality gap' between the quadrotor model used by the offline optimal control method and the real quadrotor. Furthermore, we explain how we set up the model and the control structure on-board of the real quadrotor to successfully close this gap and perform time-optimal maneuvers in the real world. Finally, G\&CNet's performance is compared to state-of-the-art differential-flatness-based optimal control methods. We show, in the experiments, that G\&CNets lead to significantly faster trajectory execution due to, in part, the less restrictive nature of the allowed state-to-input mappings.
Satellite Pose Estimation Challenge: Dataset, Competition Design and Results
Nov 05, 2019
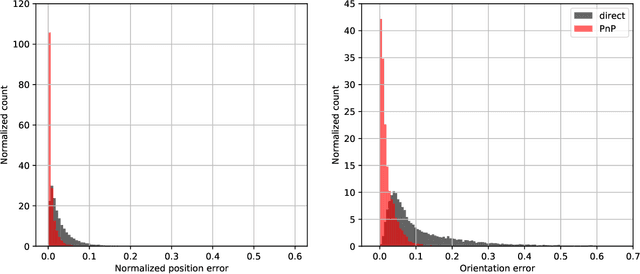
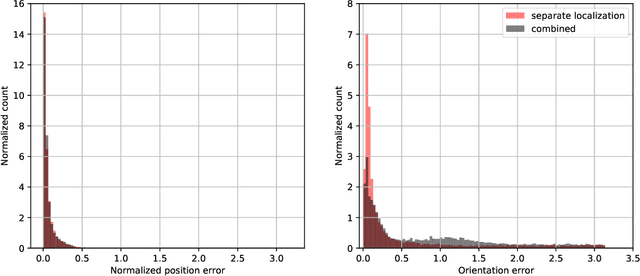
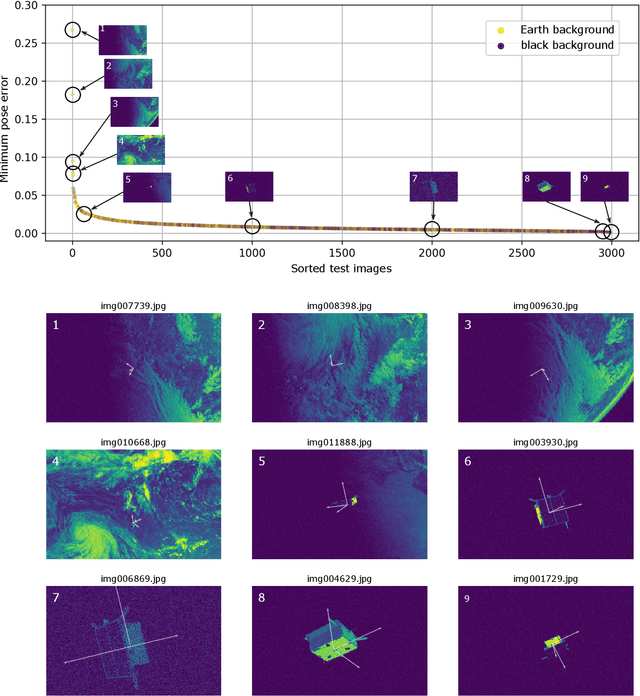
Reliable pose estimation of uncooperative satellites is a key technology for enabling future on-orbit servicing and debris removal missions. The Kelvins Satellite Pose Estimation Challenge aims at evaluating and comparing monocular vision-based approaches and pushing the state-of-the-art on this problem. This work is based on the Satellite Pose Estimation Dataset, the first publicly available machine learning set of synthetic and real spacecraft imagery. The choice of dataset reflects one of the unique challenges associated with spaceborne computer vision tasks, namely the lack of spaceborne images to train and validate the developed algorithms. This work briefly reviews the basic properties and the collection process of the dataset which was made publicly available. The competition design, including the definition of performance metrics and the adopted testbed, is also discussed. Furthermore, the submissions of the 48 participants are analyzed to compare the performance of their approaches and uncover what factors make the satellite pose estimation problem especially challenging.
Neural Network Architecture Search with Differentiable Cartesian Genetic Programming for Regression
Jul 03, 2019
The ability to design complex neural network architectures which enable effective training by stochastic gradient descent has been the key for many achievements in the field of deep learning. However, developing such architectures remains a challenging and resourceintensive process full of trial-and-error iterations. All in all, the relation between the network topology and its ability to model the data remains poorly understood. We propose to encode neural networks with a differentiable variant of Cartesian Genetic Programming (dCGPANN) and present a memetic algorithm for architecture design: local searches with gradient descent learn the network parameters while evolutionary operators act on the dCGPANN genes shaping the network architecture towards faster learning. Studying a particular instance of such a learning scheme, we are able to improve the starting feed forward topology by learning how to rewire and prune links, adapt activation functions and introduce skip connections for chosen regression tasks. The evolved network architectures require less space for network parameters and reach, given the same amount of time, a significantly lower error on average.
Super-Resolution of PROBA-V Images Using Convolutional Neural Networks
Jul 03, 2019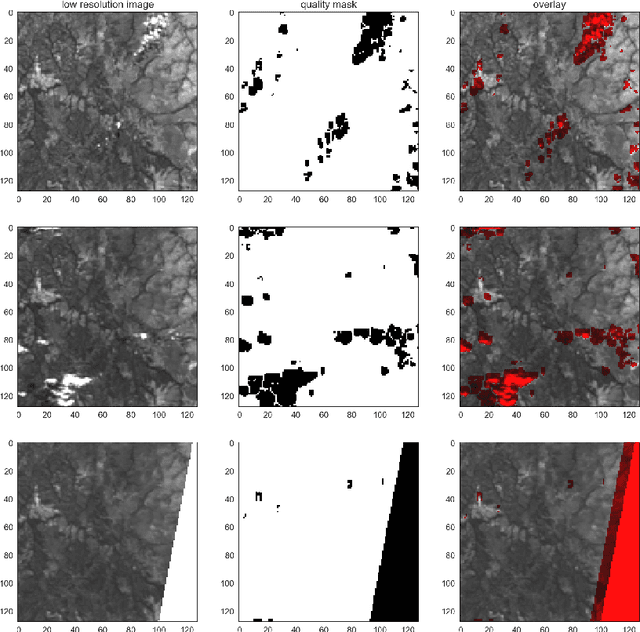
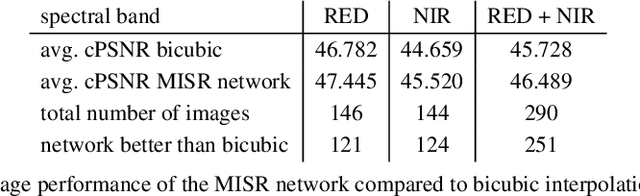
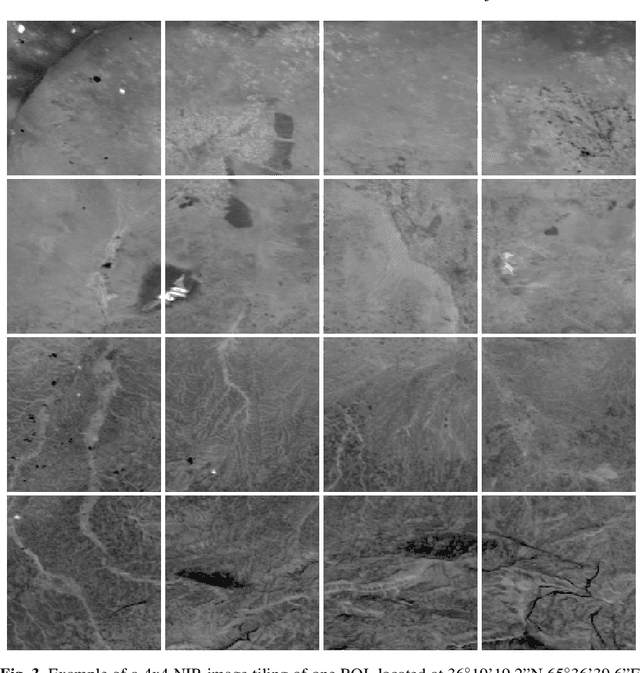
ESA's PROBA-V Earth observation satellite enables us to monitor our planet at a large scale, studying the interaction between vegetation and climate and provides guidance for important decisions on our common global future. However, the interval at which high resolution images are recorded spans over several days, in contrast to the availability of lower resolution images which is often daily. We collect an extensive dataset of both, high and low resolution images taken by PROBA-V instruments during monthly periods to investigate Multi Image Super-resolution, a technique to merge several low resolution images to one image of higher quality. We propose a convolutional neural network that is able to cope with changes in illumination, cloud coverage and landscape features which are challenges introduced by the fact that the different images are taken over successive satellite passages over the same region. Given a bicubic upscaling of low resolution images taken under optimal conditions, we find the Peak Signal to Noise Ratio of the reconstructed image of the network to be higher for a large majority of different scenes. This shows that applied machine learning has the potential to enhance large amounts of previously collected earth observation data during multiple satellite passes.
Interplanetary Transfers via Deep Representations of the Optimal Policy and/or of the Value Function
Apr 18, 2019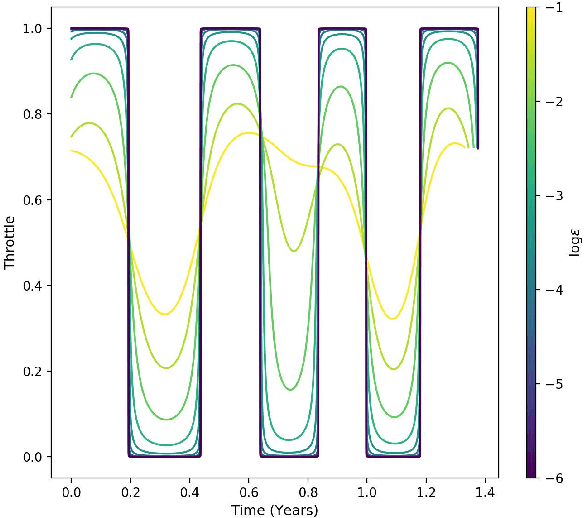
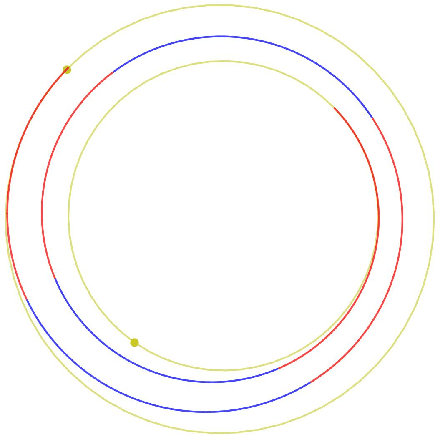
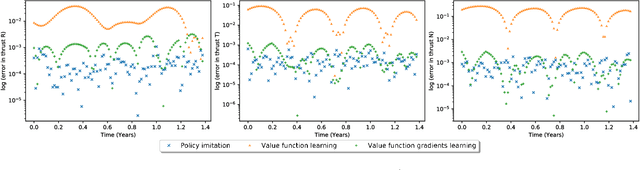
A number of applications to interplanetary trajectories have been recently proposed based on deep networks. These approaches often rely on the availability of a large number of optimal trajectories to learn from. In this paper we introduce a new method to quickly create millions of optimal spacecraft trajectories from a single nominal trajectory. Apart from the generation of the nominal trajectory, no additional optimal control problems need to be solved as all the trajectories, by construction, satisfy Pontryagin's minimum principle and the relevant transversality conditions. We then consider deep feed forward neural networks and benchmark three learning methods on the created dataset: policy imitation, value function learning and value function gradient learning. Our results are shown for the case of the interplanetary trajectory optimization problem of reaching Venus orbit, with the nominal trajectory starting from the Earth. We find that both policy imitation and value function gradient learning are able to learn the optimal state feedback, while in the case of value function learning the optimal policy is not captured, only the final value of the optimal propellant mass is.
Learning a Family of Optimal State Feedback Controllers
Feb 27, 2019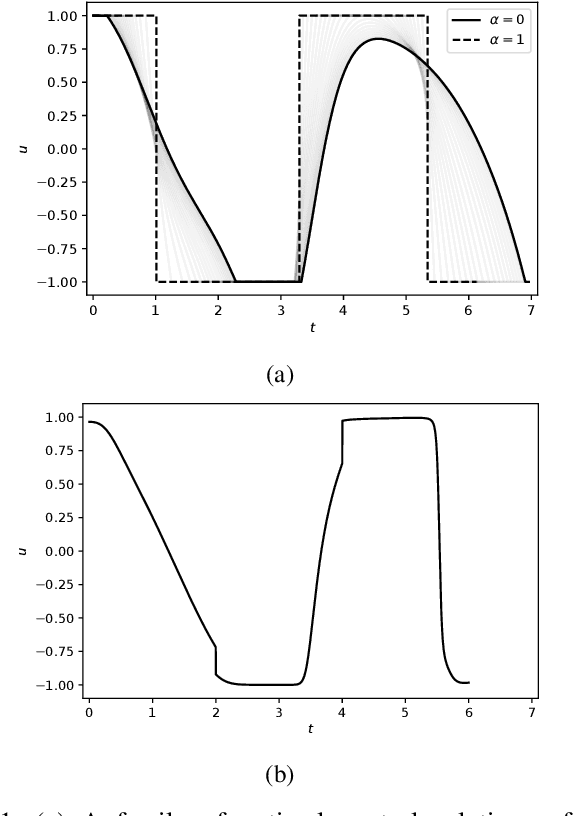
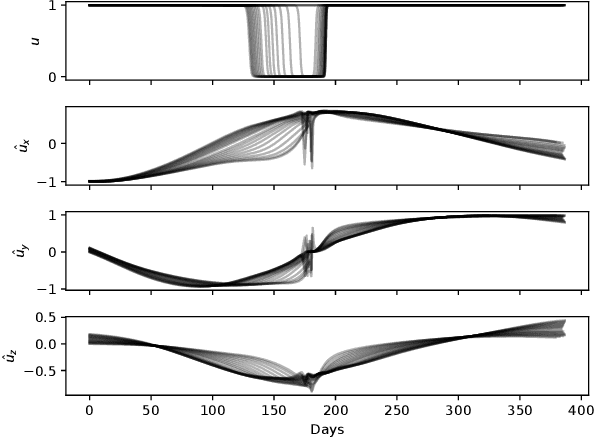
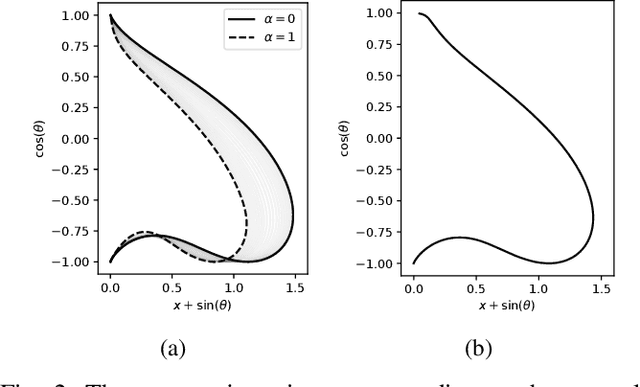
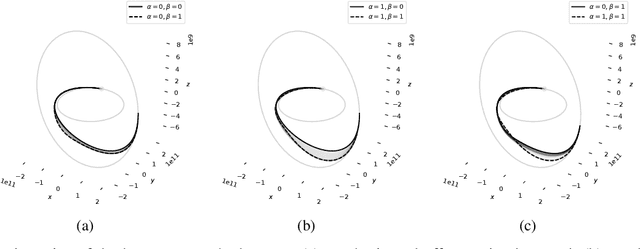
Solving optimal control problems is well known to be very computationally demanding. In this paper we show how a combination of Pontryagin's minimum principle and machine learning can be used to learn optimal feedback controllers for a parametric cost function. This enables an unmanned system with limited computational resources to run optimal feedback controllers, and furthermore change the objective being optimised on the fly in response to external events. Thus, a time optimal control policy can be changed to a fuel optimal one, in the event of e.g., fuel leakage. The proposed approach is illustrated on both a standard inverted pendulum swing-up problem and a more complex interplanetary spacecraft orbital transfer.
Learning the optimal state-feedback via supervised imitation learning
Jan 07, 2019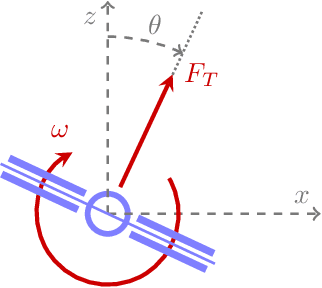

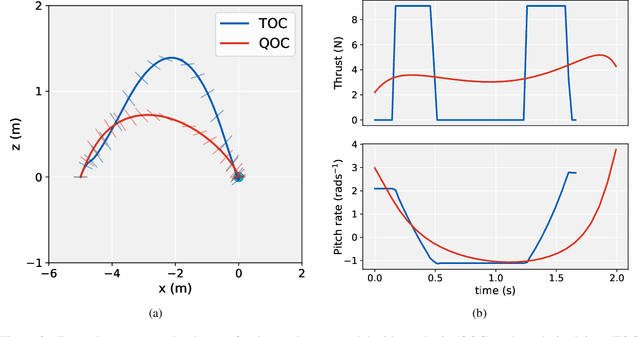

Imitation learning is a control design paradigm that seeks to learn a control policy reproducing demonstrations from experts. By substituting expert's demonstrations for optimal behaviours, the same paradigm leads to the design of control policies closely approximating the optimal state-feedback. This approach requires training a machine learning algorithm (in our case deep neural networks) directly on state-control pairs originating from optimal trajectories. We have shown in previous work that, when restricted to relatively low-dimensional state and control spaces, this approach is very successful in several deterministic, non-linear problems in continuous-time. In this work, we refine our previous studies using as test case a simple quadcopter model with quadratic and time-optimal objective functions. We describe in detail the best learning pipeline we have developed and that is able to approximate via deep neural networks the state-feedback map to a very high accuracy. We introduce the use of the softplus activation function in the hidden units showing how it results in a smoother control profile whilst retaining the benefits of ReLUs. We show how to evaluate the optimality of the trained state-feedback, and find that already with two layers the objective function reached and its optimal value differ by less than one percent. We later consider also an additional metric linked to the system asymptotic behaviour - time taken to converge to the policy's fixed point. With respect to these metrics, we show that improvements in the mean average error do not necessarily correspond to significant improvements.
A Survey on Artificial Intelligence Trends in Spacecraft Guidance Dynamics and Control
Dec 07, 2018The rapid developments of Artificial Intelligence in the last decade are influencing Aerospace Engineering to a great extent and research in this context is proliferating. We share our observations on the recent developments in the area of Spacecraft Guidance Dynamics and Control, giving selected examples on success stories that have been motivated by mission designs. Our focus is on evolutionary optimisation, tree searches and machine learning, including deep learning and reinforcement learning as the key technologies and drivers for current and future research in the field. From a high-level perspective, we survey various scenarios for which these approaches have been successfully applied or are under strong scientific investigation. Whenever possible, we highlight the relations and synergies that can be obtained by combining different techniques and projects towards future domains for which newly emerging artificial intelligence techniques are expected to become game changers.