 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence Analysis of Asynchronous Federated Learning with Gradient Compression for Non-Convex Optimization
Apr 28, 2025



Gradient compression is an effective technique for reducing communication costs in federated learning (FL), and error feedback (EF) is usually adopted to remedy the compression errors. However, there remains a lack of systematic study on these techniques in asynchronous FL. In this paper, we fill this gap by analyzing the convergence behaviors of FL under different frameworks. We firstly consider a basic asynchronous FL framework AsynFL, and provide an improved convergence analysis that relies on fewer assumptions and yields a superior convergence rate than prior studies. Then, we consider a variant framework with gradient compression, AsynFLC. We show sufficient conditions for its convergence to the optimum, indicating the interaction between asynchronous delay and compression rate. Our analysis also demonstrates that asynchronous delay amplifies the variance caused by compression, thereby hindering convergence, and such an impact is exacerbated by high data heterogeneity. Furthermore, we study the convergence of AsynFLC-EF, the framework that further integrates EF. We prove that EF can effectively reduce the variance of gradient estimation despite asynchronous delay, which enables AsynFLC-EF to match the convergence rate of AsynFL. We also show that the impact of asynchronous delay on EF is limited to slowing down the higher-order convergence term. Experimental results substantiate our analytical findings very well.
FedCME: Client Matching and Classifier Exchanging to Handle Data Heterogeneity in Federated Learning
Jul 17, 2023



Data heterogeneity across clients is one of the key challenges in Federated Learning (FL), which may slow down the global model convergence and even weaken global model performance. Most existing approaches tackle the heterogeneity by constraining local model updates through reference to global information provided by the server. This can alleviate the performance degradation on the aggregated global model. Different from existing methods, we focus the information exchange between clients, which could also enhance the effectiveness of local training and lead to generate a high-performance global model. Concretely, we propose a novel FL framework named FedCME by client matching and classifier exchanging. In FedCME, clients with large differences in data distribution will be matched in pairs, and then the corresponding pair of clients will exchange their classifiers at the stage of local training in an intermediate moment. Since the local data determines the local model training direction, our method can correct update direction of classifiers and effectively alleviate local update divergence. Besides, we propose feature alignment to enhance the training of the feature extractor. Experimental results demonstrate that FedCME performs better than FedAvg, FedProx, MOON and FedRS on popular federated learning benchmarks including FMNIST and CIFAR10, in the case where data are heterogeneous.
PFL-MoE: Personalized Federated Learning Based on Mixture of Experts
Dec 31, 2020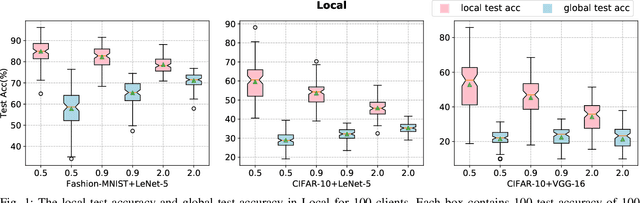
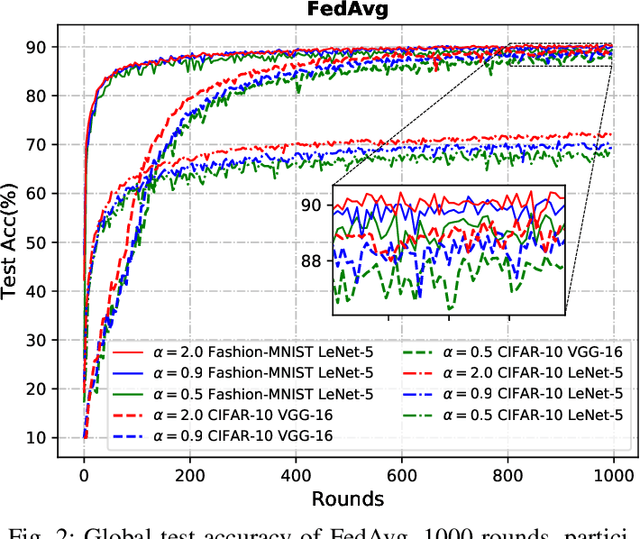
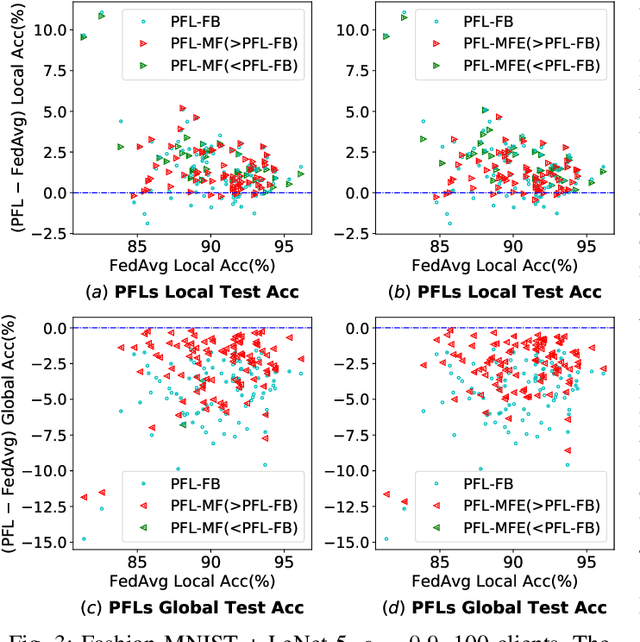
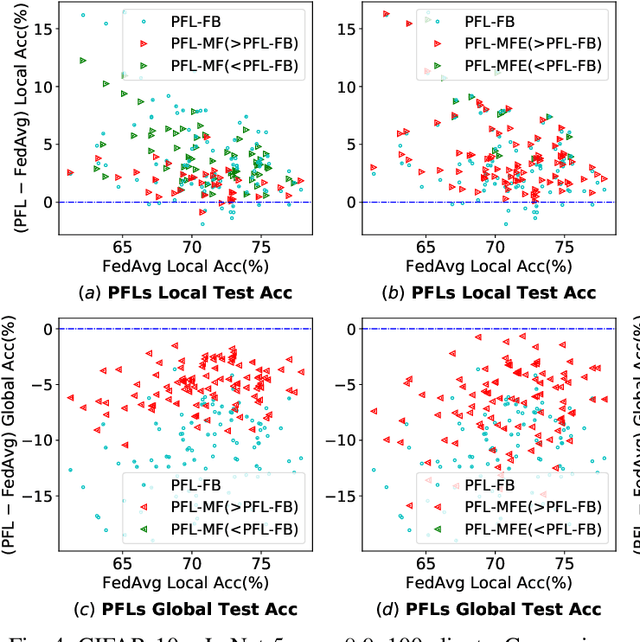
Federated learning (FL) is an emerging distributed machine learning paradigm that avoids data sharing among training nodes so as to protect data privacy. Under coordination of the FL server, each client conducts model training using its own computing resource and private data set. The global model can be created by aggregating the training results of clients. To cope with highly non-IID data distributions, personalized federated learning (PFL) has been proposed to improve overall performance by allowing each client to learn a personalized model. However, one major drawback of a personalized model is the loss of generalization. To achieve model personalization while maintaining generalization, in this paper, we propose a new approach, named PFL-MoE, which mixes outputs of the personalized model and global model via the MoE architecture. PFL-MoE is a generic approach and can be instantiated by integrating existing PFL algorithms. Particularly, we propose the PFL-MF algorithm which is an instance of PFL-MoE based on the freeze-base PFL algorithm. We further improve PFL-MF by enhancing the decision-making ability of MoE gating network and propose a variant algorithm PFL-MFE. We demonstrate the effectiveness of PFL-MoE by training the LeNet-5 and VGG-16 models on the Fashion-MNIST and CIFAR-10 datasets with non-IID partitions.