 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Domain Adaptation of Large Language Models for Classifying Mechanical Assembly Components
May 02, 2025The conceptual design phase represents a critical early stage in the product development process, where designers generate potential solutions that meet predefined design specifications based on functional requirements. Functional modeling, a foundational aspect of this phase, enables designers to reason about product functions before specific structural details are determined. A widely adopted approach to functional modeling is the Function-Behavior-Structure (FBS) framework, which supports the transformation of functional intent into behavioral and structural descriptions. However, the effectiveness of function-based design is often hindered by the lack of well-structured and comprehensive functional data. This scarcity can negatively impact early design decision-making and hinder the development of accurate behavioral models. Recent advances in Large Language Models (LLMs), such as those based on GPT architectures, offer a promising avenue to address this gap. LLMs have demonstrated significant capabilities in language understanding and natural language processing (NLP), making them suitable for automated classification tasks. This study proposes a novel LLM-based domain adaptation (DA) framework using fine-tuning for the automated classification of mechanical assembly parts' functions. By fine-tuning LLMs on domain-specific datasets, the traditionally manual and subjective process of function annotation can be improved in both accuracy and consistency. A case study demonstrates fine-tuning GPT-3.5 Turbo on data from the Oregon State Design Repository (OSDR), and evaluation on the A Big CAD (ABC) dataset shows that the domain-adapted LLM can generate high-quality functional data, enhancing the semantic representation of mechanical parts and supporting more effective design exploration in early-phase engineering.
RECALL-MM: A Multimodal Dataset of Consumer Product Recalls for Risk Analysis using Computational Methods and Large Language Models
Mar 29, 2025



Product recalls provide valuable insights into potential risks and hazards within the engineering design process, yet their full potential remains underutilized. In this study, we curate data from the United States Consumer Product Safety Commission (CPSC) recalls database to develop a multimodal dataset, RECALL-MM, that informs data-driven risk assessment using historical information, and augment it using generative methods. Patterns in the dataset highlight specific areas where improved safety measures could have significant impact. We extend our analysis by demonstrating interactive clustering maps that embed all recalls into a shared latent space based on recall descriptions and product names. Leveraging these data-driven tools, we explore three case studies to demonstrate the dataset's utility in identifying product risks and guiding safer design decisions. The first two case studies illustrate how designers can visualize patterns across recalled products and situate new product ideas within the broader recall landscape to proactively anticipate hazards. In the third case study, we extend our approach by employing a large language model (LLM) to predict potential hazards based solely on product images. This demonstrates the model's ability to leverage visual context to identify risk factors, revealing strong alignment with historical recall data across many hazard categories. However, the analysis also highlights areas where hazard prediction remains challenging, underscoring the importance of risk awareness throughout the design process. Collectively, this work aims to bridge the gap between historical recall data and future product safety, presenting a scalable, data-driven approach to safer engineering design.
MSEval: A Dataset for Material Selection in Conceptual Design to Evaluate Algorithmic Models
Jul 12, 2024
Material selection plays a pivotal role in many industries, from manufacturing to construction. Material selection is usually carried out after several cycles of conceptual design, during which designers iteratively refine the design solution and the intended manufacturing approach. In design research, material selection is typically treated as an optimization problem with a single correct answer. Moreover, it is also often restricted to specific types of objects or design functions, which can make the selection process computationally expensive and time-consuming. In this paper, we introduce MSEval, a novel dataset which is comprised of expert material evaluations across a variety of design briefs and criteria. This data is designed to serve as a benchmark to facilitate the evaluation and modification of machine learning models in the context of material selection for conceptual design.
Exploring the Capabilities of Large Language Models for Generating Diverse Design Solutions
May 02, 2024Access to large amounts of diverse design solutions can support designers during the early stage of the design process. In this paper, we explore the efficacy of large language models (LLM) in producing diverse design solutions, investigating the level of impact that parameter tuning and various prompt engineering techniques can have on the diversity of LLM-generated design solutions. Specifically, LLMs are used to generate a total of 4,000 design solutions across five distinct design topics, eight combinations of parameters, and eight different types of prompt engineering techniques, comparing each combination of parameter and prompt engineering method across four different diversity metrics. LLM-generated solutions are compared against 100 human-crowdsourced solutions in each design topic using the same set of diversity metrics. Results indicate that human-generated solutions consistently have greater diversity scores across all design topics. Using a post hoc logistic regression analysis we investigate whether these differences primarily exist at the semantic level. Results show that there is a divide in some design topics between humans and LLM-generated solutions, while others have no clear divide. Taken together, these results contribute to the understanding of LLMs' capabilities in generating a large volume of diverse design solutions and offer insights for future research that leverages LLMs to generate diverse design solutions for a broad range of design tasks (e.g., inspirational stimuli).
Evaluating Large Language Models for Material Selection
Apr 23, 2024Material selection is a crucial step in conceptual design due to its significant impact on the functionality, aesthetics, manufacturability, and sustainability impact of the final product. This study investigates the use of Large Language Models (LLMs) for material selection in the product design process and compares the performance of LLMs against expert choices for various design scenarios. By collecting a dataset of expert material preferences, the study provides a basis for evaluating how well LLMs can align with expert recommendations through prompt engineering and hyperparameter tuning. The divergence between LLM and expert recommendations is measured across different model configurations, prompt strategies, and temperature settings. This approach allows for a detailed analysis of factors influencing the LLMs' effectiveness in recommending materials. The results from this study highlight two failure modes, and identify parallel prompting as a useful prompt-engineering method when using LLMs for material selection. The findings further suggest that, while LLMs can provide valuable assistance, their recommendations often vary significantly from those of human experts. This discrepancy underscores the need for further research into how LLMs can be better tailored to replicate expert decision-making in material selection. This work contributes to the growing body of knowledge on how LLMs can be integrated into the design process, offering insights into their current limitations and potential for future improvements.
DesignQA: A Multimodal Benchmark for Evaluating Large Language Models' Understanding of Engineering Documentation
Apr 11, 2024



This research introduces DesignQA, a novel benchmark aimed at evaluating the proficiency of multimodal large language models (MLLMs) in comprehending and applying engineering requirements in technical documentation. Developed with a focus on real-world engineering challenges, DesignQA uniquely combines multimodal data-including textual design requirements, CAD images, and engineering drawings-derived from the Formula SAE student competition. Different from many existing MLLM benchmarks, DesignQA contains document-grounded visual questions where the input image and input document come from different sources. The benchmark features automatic evaluation metrics and is divided into segments-Rule Comprehension, Rule Compliance, and Rule Extraction-based on tasks that engineers perform when designing according to requirements. We evaluate state-of-the-art models like GPT4 and LLaVA against the benchmark, and our study uncovers the existing gaps in MLLMs' abilities to interpret complex engineering documentation. Key findings suggest that while MLLMs demonstrate potential in navigating technical documents, substantial limitations exist, particularly in accurately extracting and applying detailed requirements to engineering designs. This benchmark sets a foundation for future advancements in AI-supported engineering design processes. DesignQA is publicly available at: https://github.com/anniedoris/design_qa/.
Conceptual Design Generation Using Large Language Models
May 30, 2023Concept generation is a creative step in the conceptual design phase, where designers often turn to brainstorming, mindmapping, or crowdsourcing design ideas to complement their own knowledge of the domain. Recent advances in natural language processing (NLP) and machine learning (ML) have led to the rise of Large Language Models (LLMs) capable of generating seemingly creative outputs from textual prompts. The success of these models has led to their integration and application across a variety of domains, including art, entertainment, and other creative work. In this paper, we leverage LLMs to generate solutions for a set of 12 design problems and compare them to a baseline of crowdsourced solutions. We evaluate the differences between generated and crowdsourced design solutions through multiple perspectives, including human expert evaluations and computational metrics. Expert evaluations indicate that the LLM-generated solutions have higher average feasibility and usefulness while the crowdsourced solutions have more novelty. We experiment with prompt engineering and find that leveraging few-shot learning can lead to the generation of solutions that are more similar to the crowdsourced solutions. These findings provide insight into the quality of design solutions generated with LLMs and begins to evaluate prompt engineering techniques that could be leveraged by practitioners to generate higher-quality design solutions synergistically with LLMs.
What's in a Name? Evaluating Assembly-Part Semantic Knowledge in Language Models through User-Provided Names in CAD Files
Apr 25, 2023Semantic knowledge of part-part and part-whole relationships in assemblies is useful for a variety of tasks from searching design repositories to the construction of engineering knowledge bases. In this work we propose that the natural language names designers use in Computer Aided Design (CAD) software are a valuable source of such knowledge, and that Large Language Models (LLMs) contain useful domain-specific information for working with this data as well as other CAD and engineering-related tasks. In particular we extract and clean a large corpus of natural language part, feature and document names and use this to quantitatively demonstrate that a pre-trained language model can outperform numerous benchmarks on three self-supervised tasks, without ever having seen this data before. Moreover, we show that fine-tuning on the text data corpus further boosts the performance on all tasks, thus demonstrating the value of the text data which until now has been largely ignored. We also identify key limitations to using LLMs with text data alone, and our findings provide a strong motivation for further work into multi-modal text-geometry models. To aid and encourage further work in this area we make all our data and code publicly available.
Material Prediction for Design Automation Using Graph Representation Learning
Sep 26, 2022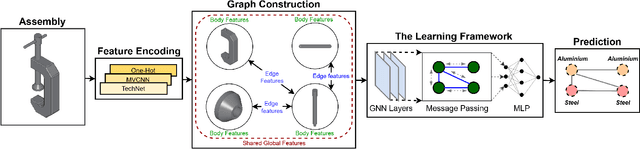
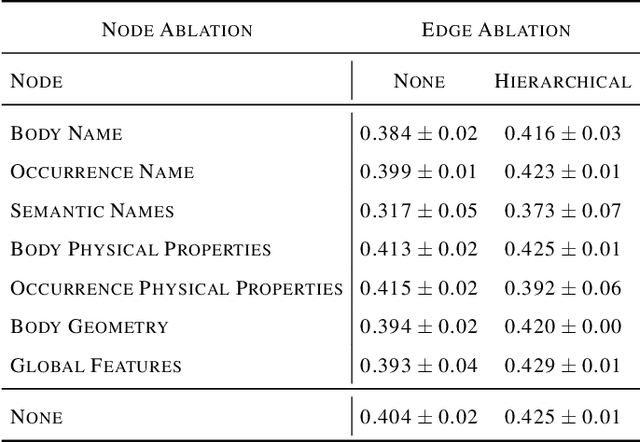
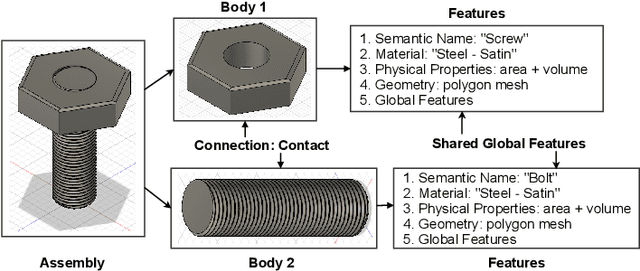
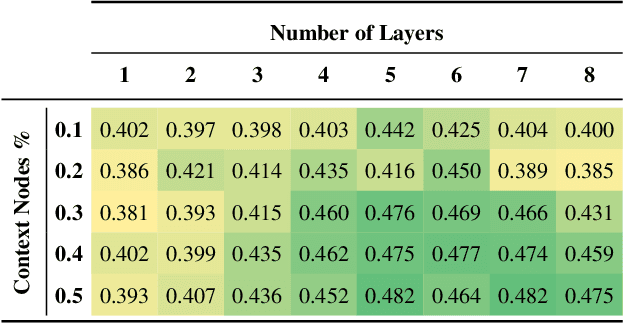
Successful material selection is critical in designing and manufacturing products for design automation. Designers leverage their knowledge and experience to create high-quality designs by selecting the most appropriate materials through performance, manufacturability, and sustainability evaluation. Intelligent tools can help designers with varying expertise by providing recommendations learned from prior designs. To enable this, we introduce a graph representation learning framework that supports the material prediction of bodies in assemblies. We formulate the material selection task as a node-level prediction task over the assembly graph representation of CAD models and tackle it using Graph Neural Networks (GNNs). Evaluations over three experimental protocols performed on the Fusion 360 Gallery dataset indicate the feasibility of our approach, achieving a 0.75 top-3 micro-f1 score. The proposed framework can scale to large datasets and incorporate designers' knowledge into the learning process. These capabilities allow the framework to serve as a recommendation system for design automation and a baseline for future work, narrowing the gap between human designers and intelligent design agents.
JoinABLe: Learning Bottom-up Assembly of Parametric CAD Joints
Nov 24, 2021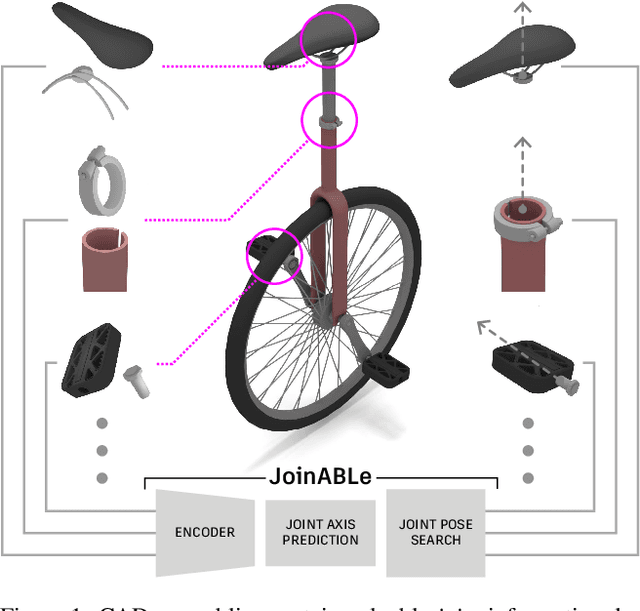
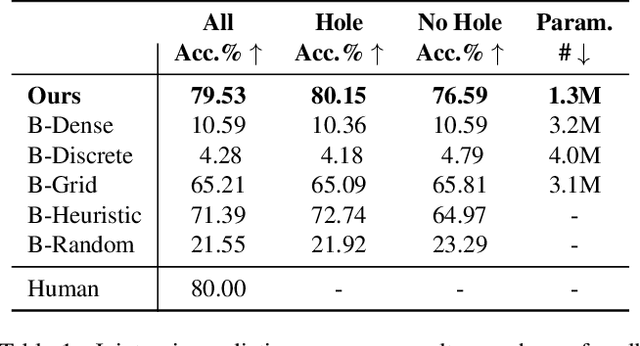
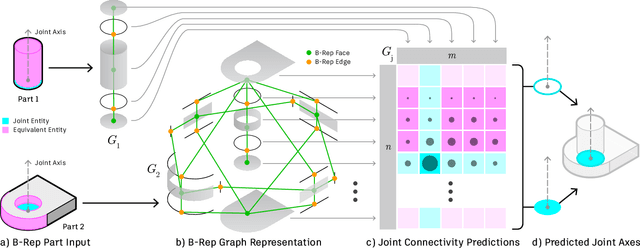
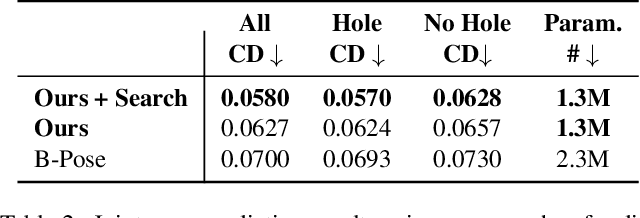
Physical products are often complex assemblies combining a multitude of 3D parts modeled in computer-aided design (CAD) software. CAD designers build up these assemblies by aligning individual parts to one another using constraints called joints. In this paper we introduce JoinABLe, a learning-based method that assembles parts together to form joints. JoinABLe uses the weak supervision available in standard parametric CAD files without the help of object class labels or human guidance. Our results show that by making network predictions over a graph representation of solid models we can outperform multiple baseline methods with an accuracy (79.53%) that approaches human performance (80%). Finally, to support future research we release the Fusion 360 Gallery assembly dataset, containing assemblies with rich information on joints, contact surfaces, holes, and the underlying assembly graph structure.