 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning with a Progression Function
Aug 02, 2020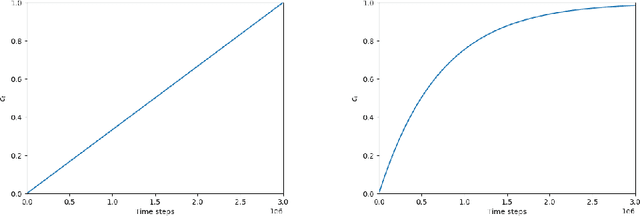
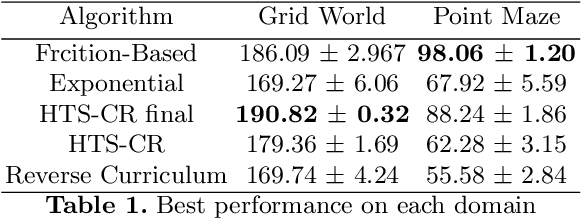
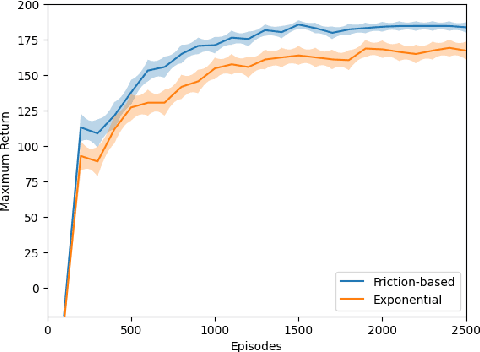
Curriculum Learning for Reinforcement Learning is an increasingly popular technique that involves training an agent on a defined sequence of intermediate tasks, called a Curriculum, to increase the agent's performance and learning speed. This paper introduces a novel paradigm for automatic curriculum generation based on a progression of task complexity. Different progression functions are introduced, including an autonomous online task progression based on the performance of the agent. The progression function also determines how long the agent should train on each intermediate task, which is an open problem in other task-based curriculum approaches. The benefits and wide applicability of our approach are shown by empirically comparing its performance to two state-of-the-art Curriculum Learning algorithms on a grid world and on a complex simulated navigation domain.
Deep Reinforcement Learning with Graph-based State Representations
Apr 29, 2020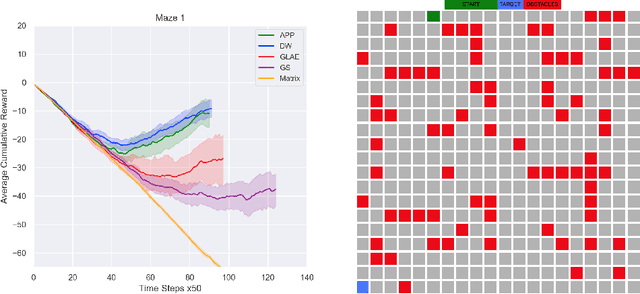
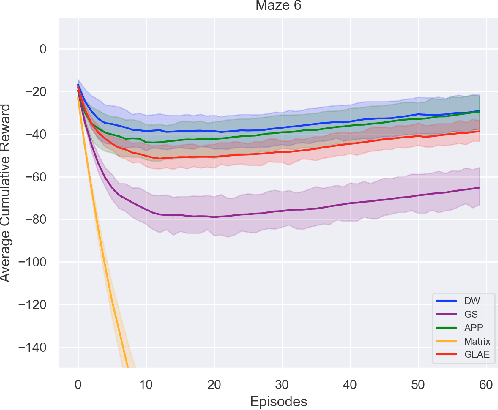
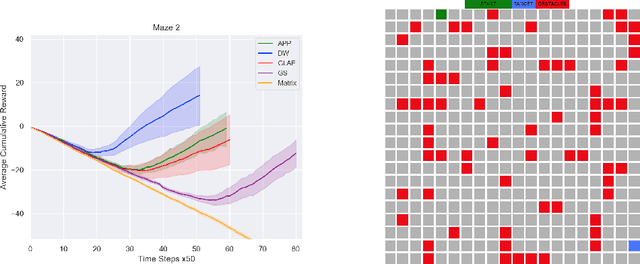
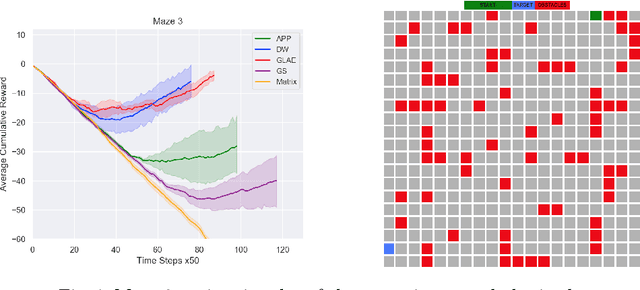
Deep RL approaches build much of their success on the ability of the deep neural network to generate useful internal representations. Nevertheless, they suffer from a high sample-complexity and starting with a good input representation can have a significant impact on the performance. In this paper, we exploit the fact that the underlying Markov decision process (MDP) represents a graph, which enables us to incorporate the topological information for effective state representation learning. Motivated by the recent success of node representations for several graph analytical tasks we specifically investigate the capability of node representation learning methods to effectively encode the topology of the underlying MDP in Deep RL. To this end we perform a comparative analysis of several models chosen from 4 different classes of representation learning algorithms for policy learning in grid-world navigation tasks, which are representative of a large class of RL problems. We find that all embedding methods outperform the commonly used matrix representation of grid-world environments in all of the studied cases. Moreoever, graph convolution based methods are outperformed by simpler random walk based methods and graph linear autoencoders.
Uniform State Abstraction For Reinforcement Learning
Apr 06, 2020
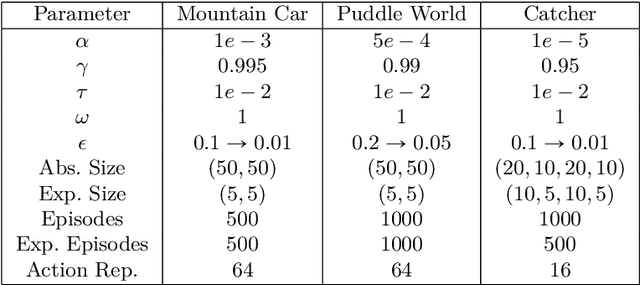
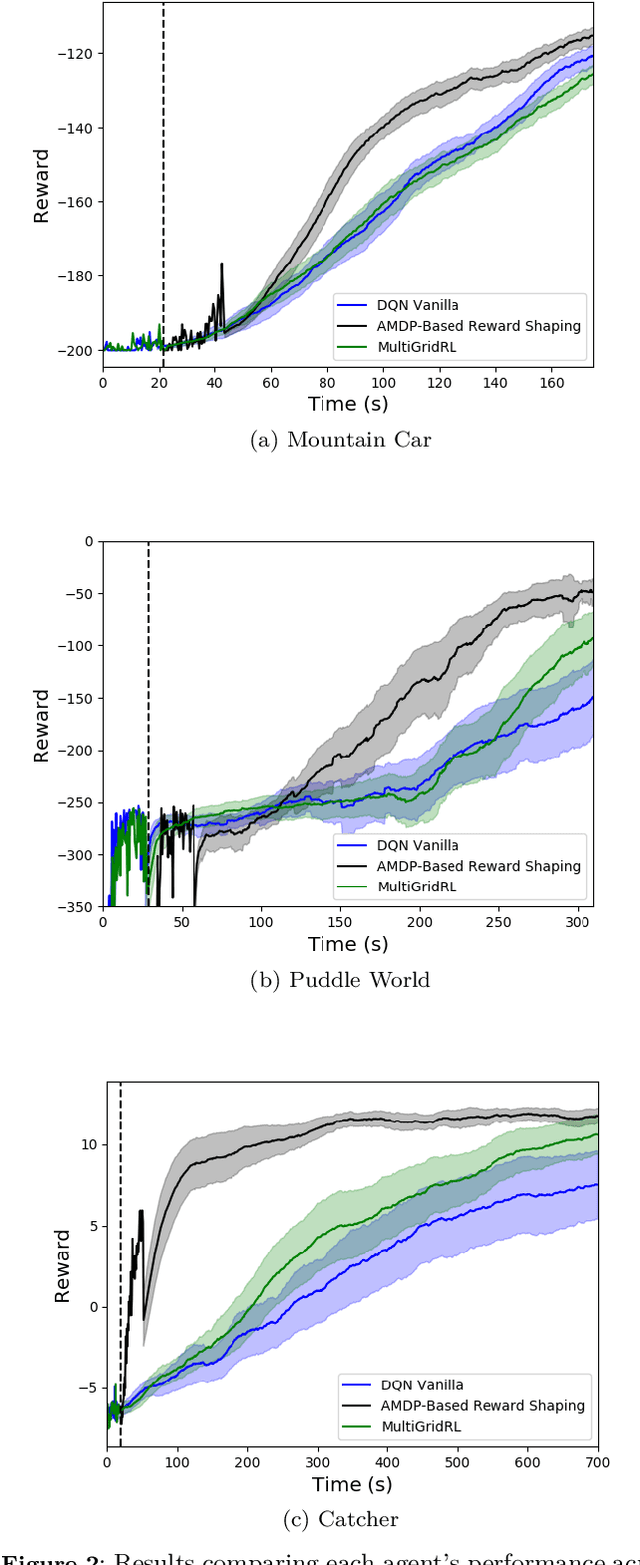
Potential Based Reward Shaping combined with a potential function based on appropriately defined abstract knowledge has been shown to significantly improve learning speed in Reinforcement Learning. MultiGrid Reinforcement Learning (MRL) has further shown that such abstract knowledge in the form of a potential function can be learned almost solely from agent interaction with the environment. However, we show that MRL faces the problem of not extending well to work with Deep Learning. In this paper we extend and improve MRL to take advantage of modern Deep Learning algorithms such as Deep Q-Networks (DQN). We show that DQN augmented with our approach perform significantly better on continuous control tasks than its Vanilla counterpart and DQN augmented with MRL.
Resource Abstraction for Reinforcement Learning in Multiagent Congestion Problems
Mar 13, 2019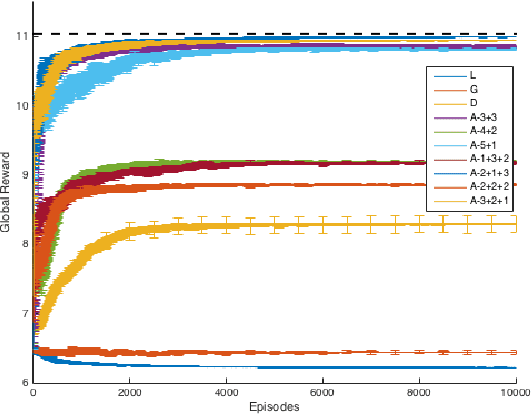
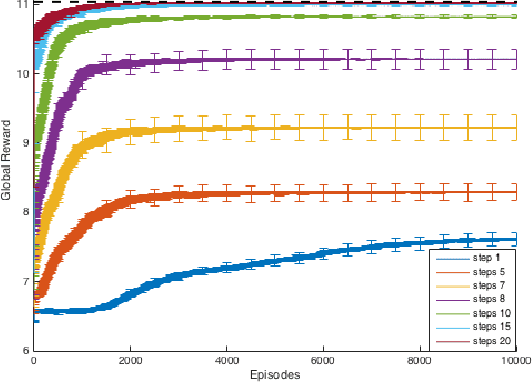
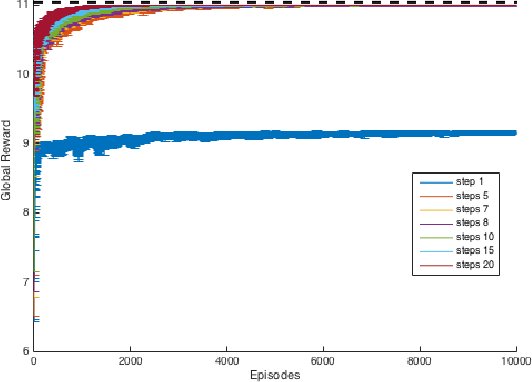
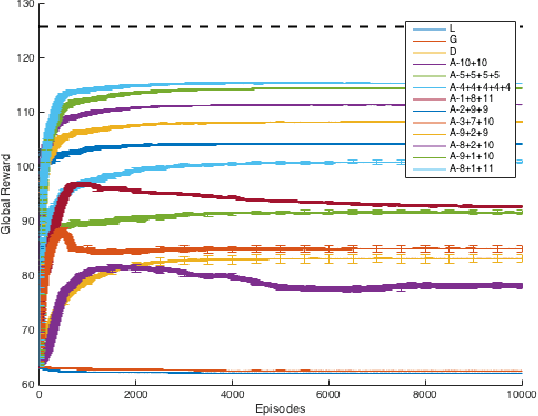
Real-world congestion problems (e.g. traffic congestion) are typically very complex and large-scale. Multiagent reinforcement learning (MARL) is a promising candidate for dealing with this emerging complexity by providing an autonomous and distributed solution to these problems. However, there are three limiting factors that affect the deployability of MARL approaches to congestion problems. These are learning time, scalability and decentralised coordination i.e. no communication between the learning agents. In this paper we introduce Resource Abstraction, an approach that addresses these challenges by allocating the available resources into abstract groups. This abstraction creates new reward functions that provide a more informative signal to the learning agents and aid the coordination amongst them. Experimental work is conducted on two benchmark domains from the literature, an abstract congestion problem and a realistic traffic congestion problem. The current state-of-the-art for solving multiagent congestion problems is a form of reward shaping called difference rewards. We show that the system using Resource Abstraction significantly improves the learning speed and scalability, and achieves the highest possible or near-highest joint performance/social welfare for both congestion problems in large-scale scenarios involving up to 1000 reinforcement learning agents.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
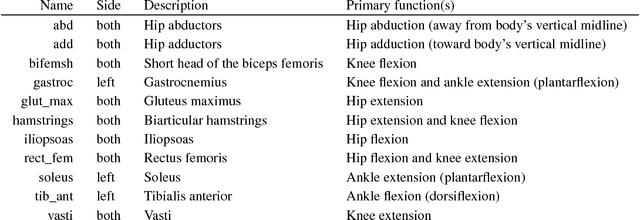
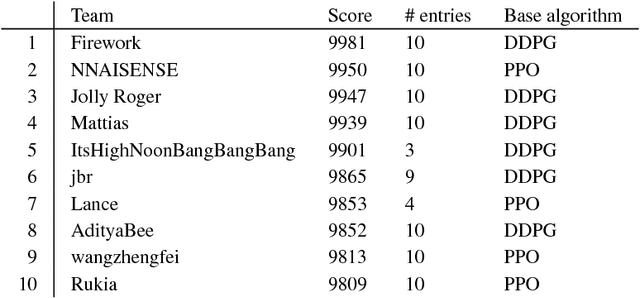

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Deep Multi-Agent Reinforcement Learning with Relevance Graphs
Nov 30, 2018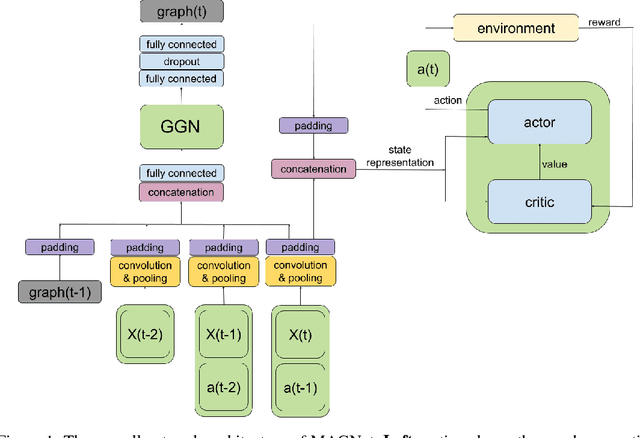
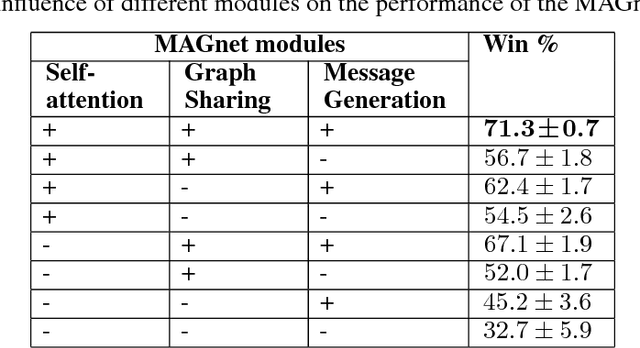
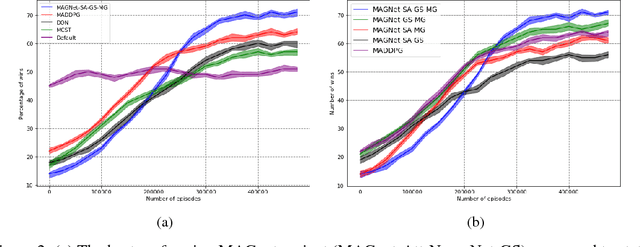
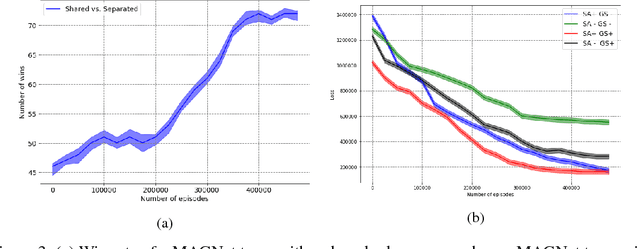
Over recent years, deep reinforcement learning has shown strong successes in complex single-agent tasks, and more recently this approach has also been applied to multi-agent domains. In this paper, we propose a novel approach, called MAGnet, to multi-agent reinforcement learning (MARL) that utilizes a relevance graph representation of the environment obtained by a self-attention mechanism, and a message-generation technique inspired by the NerveNet architecture. We applied our MAGnet approach to the Pommerman game and the results show that it significantly outperforms state-of-the-art MARL solutions, including DQN, MADDPG, and MCTS.