 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-tolerant, Reliable Active Classification with Comparison Queries
Jan 15, 2020
With the explosion of massive, widely available unlabeled data in the past years, finding label and time efficient, robust learning algorithms has become ever more important in theory and in practice. We study the paradigm of active learning, in which algorithms with access to large pools of data may adaptively choose what samples to label in the hope of exponentially increasing efficiency. By introducing comparisons, an additional type of query comparing two points, we provide the first time and query efficient algorithms for learning non-homogeneous linear separators robust to bounded (Massart) noise. We further provide algorithms for a generalization of the popular Tsybakov low noise condition, and show how comparisons provide a strong reliability guarantee that is often impractical or impossible with only labels - returning a classifier that makes no errors with high probability.
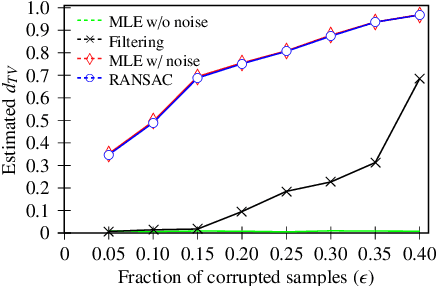
Outlier-Robust High-Dimensional Sparse Estimation via Iterative Filtering
Nov 19, 2019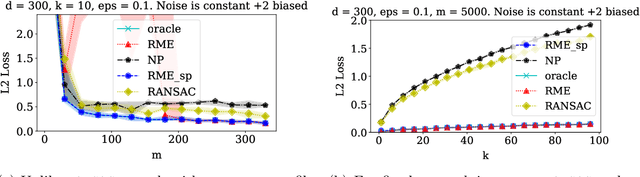
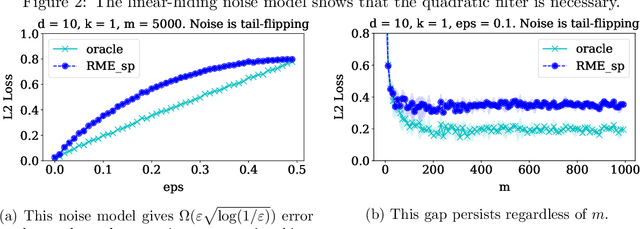
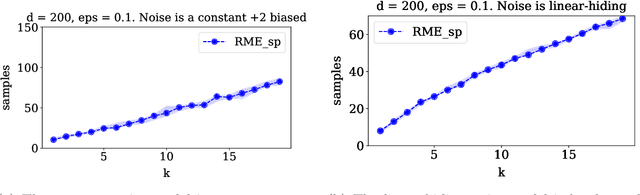
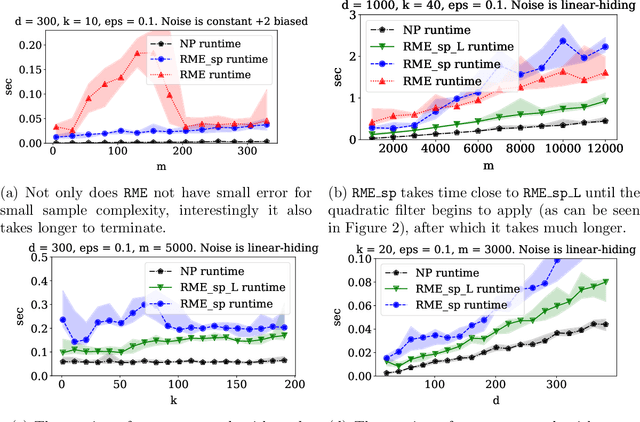
We study high-dimensional sparse estimation tasks in a robust setting where a constant fraction of the dataset is adversarially corrupted. Specifically, we focus on the fundamental problems of robust sparse mean estimation and robust sparse PCA. We give the first practically viable robust estimators for these problems. In more detail, our algorithms are sample and computationally efficient and achieve near-optimal robustness guarantees. In contrast to prior provable algorithms which relied on the ellipsoid method, our algorithms use spectral techniques to iteratively remove outliers from the dataset. Our experimental evaluation on synthetic data shows that our algorithms are scalable and significantly outperform a range of previous approaches, nearly matching the best error rate without corruptions.
The Optimal Approximation Factor in Density Estimation
Feb 10, 2019

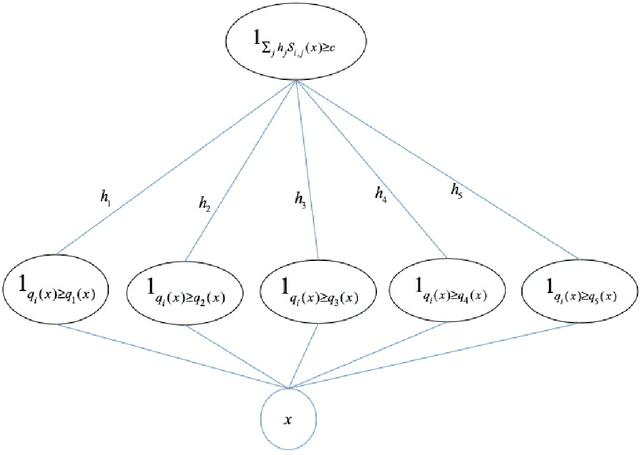
Consider the following problem: given two arbitrary densities $q_1,q_2$ and a sample-access to an unknown target density $p$, find which of the $q_i$'s is closer to $p$ in total variation. A remarkable result due to Yatracos shows that this problem is tractable in the following sense: there exists an algorithm that uses $O(\epsilon^{-2})$ samples from $p$ and outputs~$q_i$ such that with high probability, $TV(q_i,p) \leq 3\cdot\mathsf{opt} + \epsilon$, where $\mathsf{opt}= \min\{TV(q_1,p),TV(q_2,p)\}$. Moreover, this result extends to any finite class of densities $\mathcal{Q}$: there exists an algorithm that outputs the best density in $\mathcal{Q}$ up to a multiplicative approximation factor of 3. We complement and extend this result by showing that: (i) the factor 3 can not be improved if one restricts the algorithm to output a density from $\mathcal{Q}$, and (ii) if one allows the algorithm to output arbitrary densities (e.g.\ a mixture of densities from $\mathcal{Q}$), then the approximation factor can be reduced to 2, which is optimal. In particular this demonstrates an advantage of improper learning over proper in this setup. We develop two approaches to achieve the optimal approximation factor of 2: an adaptive one and a static one. Both approaches are based on a geometric point of view of the problem and rely on estimating surrogate metrics to the total variation. Our sample complexity bounds exploit techniques from {\it Adaptive Data Analysis}.
Robust Learning of Fixed-Structure Bayesian Networks
Oct 29, 2018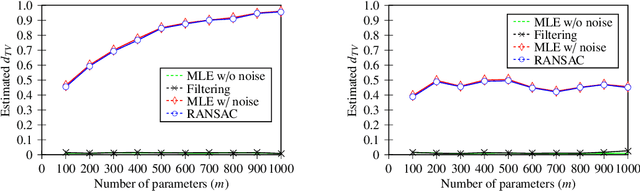
We investigate the problem of learning Bayesian networks in a robust model where an $\epsilon$-fraction of the samples are adversarially corrupted. In this work, we study the fully observable discrete case where the structure of the network is given. Even in this basic setting, previous learning algorithms either run in exponential time or lose dimension-dependent factors in their error guarantees. We provide the first computationally efficient robust learning algorithm for this problem with dimension-independent error guarantees. Our algorithm has near-optimal sample complexity, runs in polynomial time, and achieves error that scales nearly-linearly with the fraction of adversarially corrupted samples. Finally, we show on both synthetic and semi-synthetic data that our algorithm performs well in practice.
Robust polynomial regression up to the information theoretic limit
Aug 10, 2017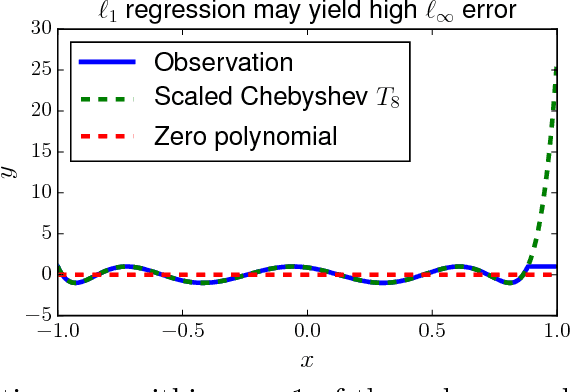
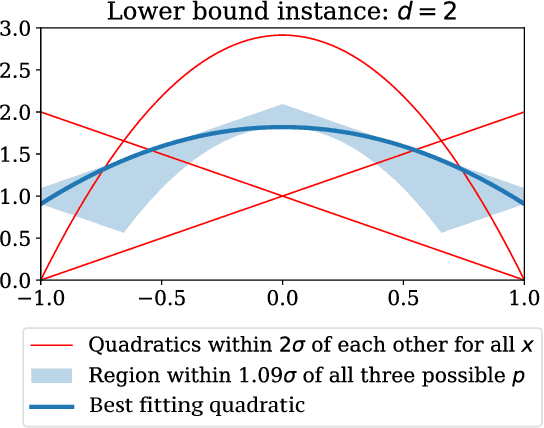
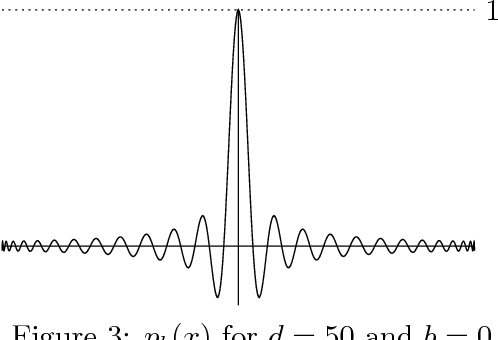
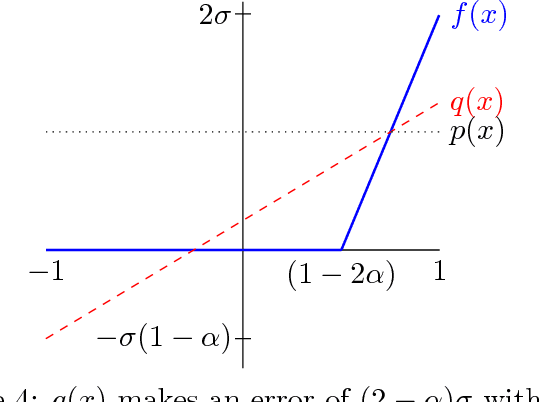
We consider the problem of robust polynomial regression, where one receives samples $(x_i, y_i)$ that are usually within $\sigma$ of a polynomial $y = p(x)$, but have a $\rho$ chance of being arbitrary adversarial outliers. Previously, it was known how to efficiently estimate $p$ only when $\rho < \frac{1}{\log d}$. We give an algorithm that works for the entire feasible range of $\rho < 1/2$, while simultaneously improving other parameters of the problem. We complement our algorithm, which gives a factor 2 approximation, with impossibility results that show, for example, that a $1.09$ approximation is impossible even with infinitely many samples.
Testing Bayesian Networks
Dec 09, 2016

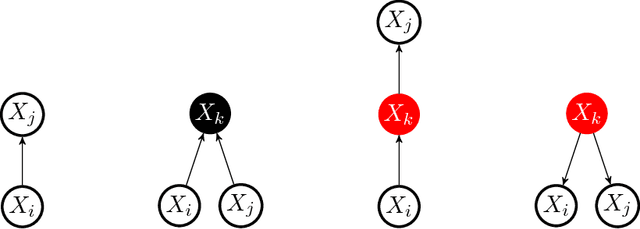

This work initiates a systematic investigation of testing {\em high-dimensional} structured distributions by focusing on testing {\em Bayesian networks} -- the prototypical family of directed graphical models. A Bayesian network is defined by a directed acyclic graph, where we associate a random variable with each node. The value at any particular node is conditionally independent of all the other non-descendant nodes once its parents are fixed. Specifically, we study the properties of identity testing and closeness testing of Bayesian networks. Our main contribution is the first non-trivial efficient testing algorithms for these problems and corresponding information-theoretic lower bounds. For a wide range of parameter settings, our testing algorithms have sample complexity {\em sublinear} in the dimension and are sample-optimal, up to constant factors.
Robust Estimators in High Dimensions without the Computational Intractability
Apr 21, 2016We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.