 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan BERT Reason? Logically Equivalent Probes for Evaluating the Inference Capabilities of Language Models
May 02, 2020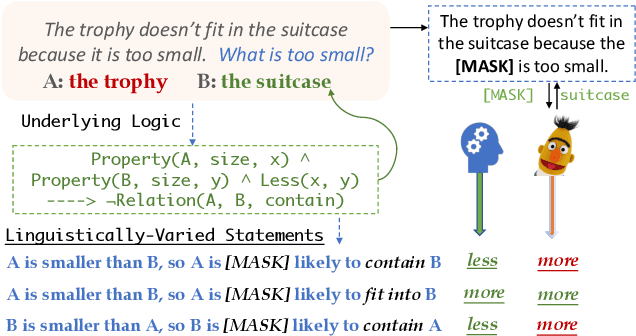

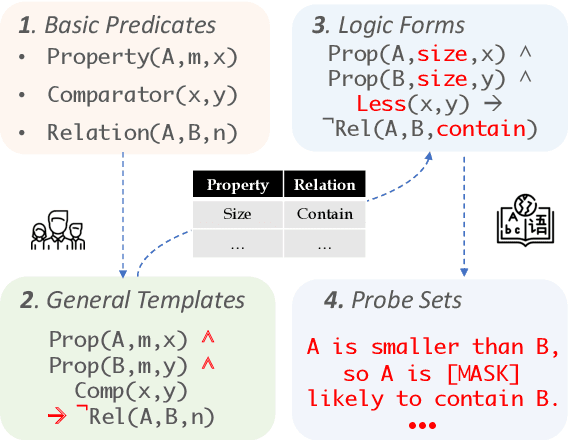

Pre-trained language models (PTLM) have greatly improved performance on commonsense inference benchmarks, however, it remains unclear whether they share a human's ability to consistently make correct inferences under perturbations. Prior studies of PTLMs have found inference deficits, but have failed to provide a systematic means of understanding whether these deficits are due to low inference abilities or poor inference robustness. In this work, we address this gap by developing a procedure that allows for the systematized probing of both PTLMs' inference abilities and robustness. Our procedure centers around the methodical creation of logically-equivalent, but syntactically-different sets of probes, of which we create a corpus of 14,400 probes coming from 60 logically-equivalent sets that can be used to probe PTLMs in three task settings. We find that despite the recent success of large PTLMs on commonsense benchmarks, their performances on our probes are no better than random guessing (even with fine-tuning) and are heavily dependent on biases--the poor overall performance, unfortunately, inhibits us from studying robustness. We hope our approach and initial probe set will assist future work in improving PTLMs' inference abilities, while also providing a probing set to test robustness under several linguistic variations--code and data will be released.
NBDT: Neural-Backed Decision Trees
Apr 01, 2020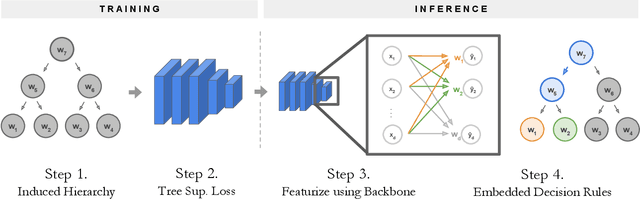
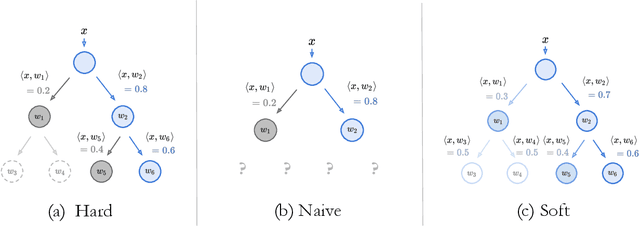
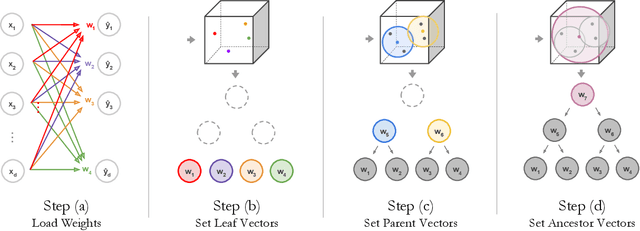

Deep learning is being adopted in settings where accurate and justifiable predictions are required, ranging from finance to medical imaging. While there has been recent work providing post-hoc explanations for model predictions, there has been relatively little work exploring more directly interpretable models that can match state-of-the-art accuracy. Historically, decision trees have been the gold standard in balancing interpretability and accuracy. However, recent attempts to combine decision trees with deep learning have resulted in models that (1) achieve accuracies far lower than that of modern neural networks (e.g. ResNet) even on small datasets (e.g. MNIST), and (2) require significantly different architectures, forcing practitioners pick between accuracy and interpretability. We forgo this dilemma by creating Neural-Backed Decision Trees (NBDTs) that (1) achieve neural network accuracy and (2) require no architectural changes to a neural network. NBDTs achieve accuracy within 1% of the base neural network on CIFAR10, CIFAR100, TinyImageNet, using recently state-of-the-art WideResNet; and within 2% of EfficientNet on ImageNet. This yields state-of-the-art explainable models on ImageNet, with NBDTs improving the baseline by ~14% to 75.30% top-1 accuracy. Furthermore, we show interpretability of our model's decisions both qualitatively and quantitatively via a semi-automatic process. Code and pretrained NBDTs can be found at https://github.com/alvinwan/neural-backed-decision-trees.
Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules
May 14, 2019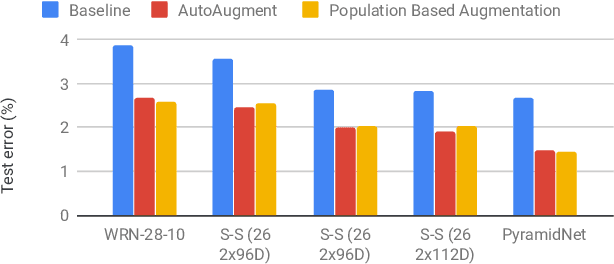
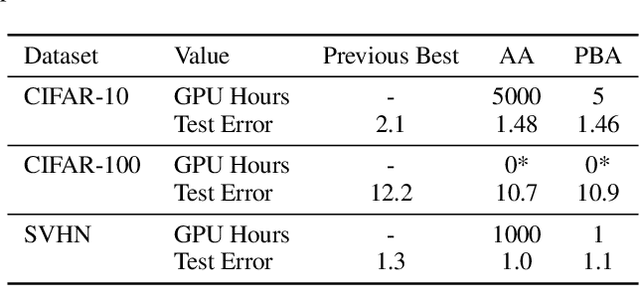
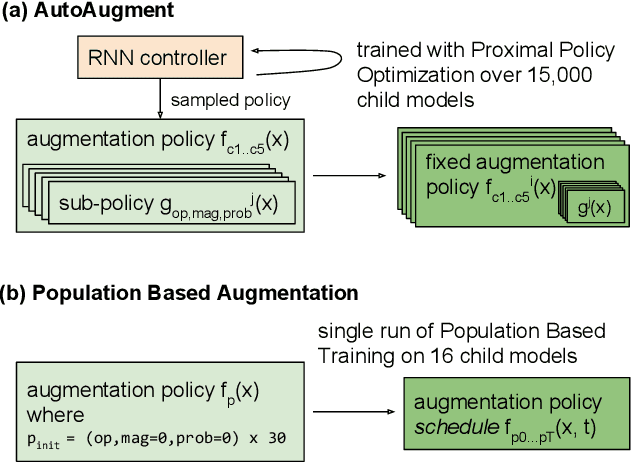
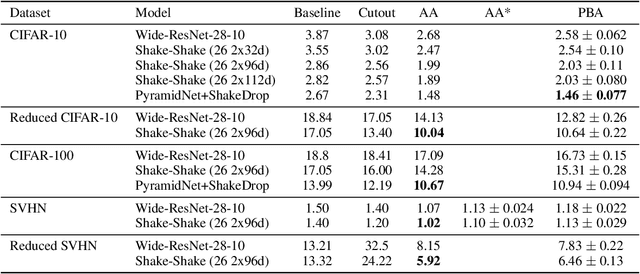
A key challenge in leveraging data augmentation for neural network training is choosing an effective augmentation policy from a large search space of candidate operations. Properly chosen augmentation policies can lead to significant generalization improvements; however, state-of-the-art approaches such as AutoAugment are computationally infeasible to run for the ordinary user. In this paper, we introduce a new data augmentation algorithm, Population Based Augmentation (PBA), which generates nonstationary augmentation policy schedules instead of a fixed augmentation policy. We show that PBA can match the performance of AutoAugment on CIFAR-10, CIFAR-100, and SVHN, with three orders of magnitude less overall compute. On CIFAR-10 we achieve a mean test error of 1.46%, which is a slight improvement upon the current state-of-the-art. The code for PBA is open source and is available at https://github.com/arcelien/pba.
Improvements to context based self-supervised learning
Mar 28, 2018
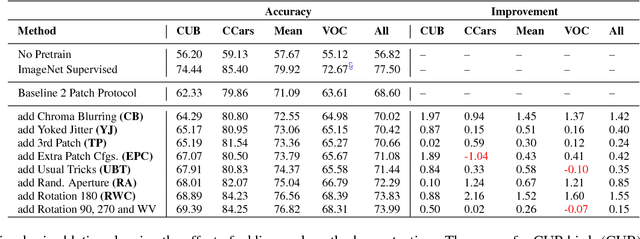

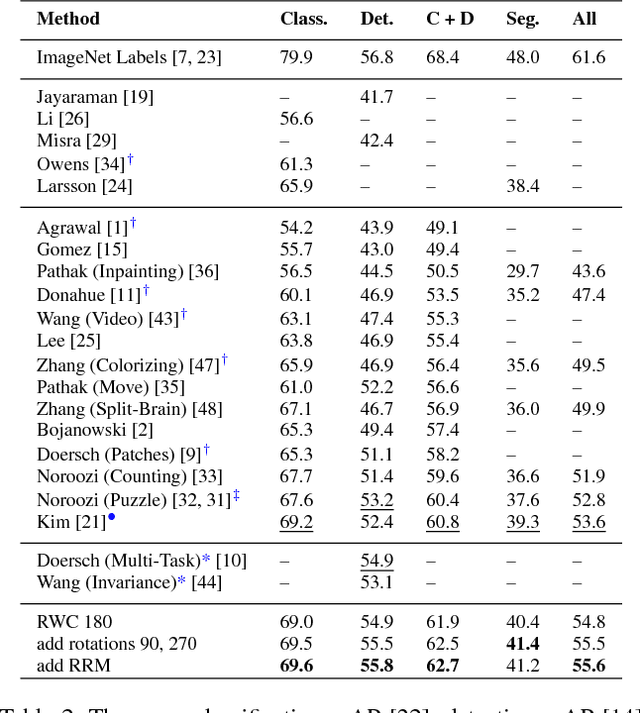
We develop a set of methods to improve on the results of self-supervised learning using context. We start with a baseline of patch based arrangement context learning and go from there. Our methods address some overt problems such as chromatic aberration as well as other potential problems such as spatial skew and mid-level feature neglect. We prevent problems with testing generalization on common self-supervised benchmark tests by using different datasets during our development. The results of our methods combined yield top scores on all standard self-supervised benchmarks, including classification and detection on PASCAL VOC 2007, segmentation on PASCAL VOC 2012, and "linear tests" on the ImageNet and CSAIL Places datasets. We obtain an improvement over our baseline method of between 4.0 to 7.1 percentage points on transfer learning classification tests. We also show results on different standard network architectures to demonstrate generalization as well as portability. All data, models and programs are available at: https://gdo-datasci.llnl.gov/selfsupervised/.