 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimationBench: Are Video Models Good at Character-Centric Animation?
Apr 16, 2026Video generation has advanced rapidly, with recent methods producing increasingly convincing animated results. However, existing benchmarks-largely designed for realistic videos-struggle to evaluate animation-style generation with its stylized appearance, exaggerated motion, and character-centric consistency. Moreover, they also rely on fixed prompt sets and rigid pipelines, offering limited flexibility for open-domain content and custom evaluation needs. To address this gap, we introduce AnimationBench, the first systematic benchmark for evaluating animation image-to-video generation. AnimationBench operationalizes the Twelve Basic Principles of Animation and IP Preservation into measurable evaluation dimensions, together with Broader Quality Dimensions including semantic consistency, motion rationality, and camera motion consistency. The benchmark supports both a standardized close-set evaluation for reproducible comparison and a flexible open-set evaluation for diagnostic analysis, and leverages visual-language models for scalable assessment. Extensive experiments show that AnimationBench aligns well with human judgment and exposes animation-specific quality differences overlooked by realism-oriented benchmarks, leading to more informative and discriminative evaluation of state-of-the-art I2V models.
MLCTR: A Fast Scalable Coupled Tensor Completion Based on Multi-Layer Non-Linear Matrix Factorization
Sep 04, 2021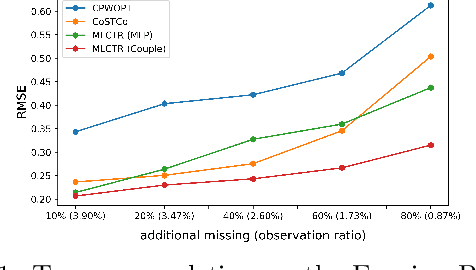

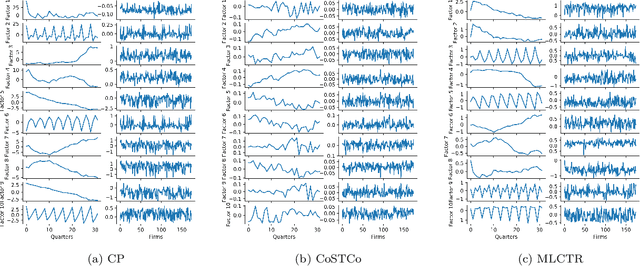
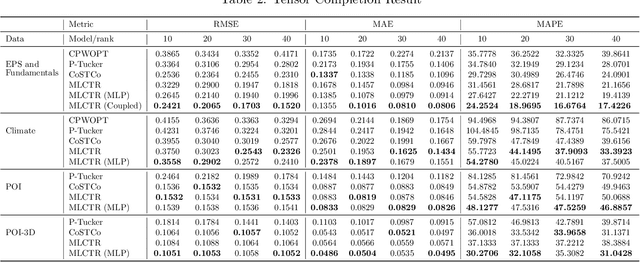
Firms earning prediction plays a vital role in investment decisions, dividends expectation, and share price. It often involves multiple tensor-compatible datasets with non-linear multi-way relationships, spatiotemporal structures, and different levels of sparsity. Current non-linear tensor completion algorithms tend to learn noisy embedding and incur overfitting. This paper focuses on the embedding learning aspect of the tensor completion problem and proposes a new multi-layer neural network architecture for tensor factorization and completion (MLCTR). The network architecture entails multiple advantages: a series of low-rank matrix factorizations (MF) building blocks to minimize overfitting, interleaved transfer functions in each layer for non-linearity, and by-pass connections to reduce the gradient diminishing problem and increase the depths of neural networks. Furthermore, the model employs Stochastic Gradient Descent(SGD) based optimization for fast convergence in training. Our algorithm is highly efficient for imputing missing values in the EPS data. Experiments confirm that our strategy of incorporating non-linearity in factor matrices demonstrates impressive performance in embedding learning and end-to-end tensor models, and outperforms approaches with non-linearity in the phase of reconstructing tensors from factor matrices.