 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Financial Sentiment Analysis with Annotators Instruction Assisted Prompting: Enhancing Contextual Interpretation and Stock Prediction Accuracy
May 09, 2025Financial sentiment analysis (FSA) presents unique challenges to LLMs that surpass those in typical sentiment analysis due to the nuanced language used in financial contexts. The prowess of these models is often undermined by the inherent subjectivity of sentiment classifications in existing benchmark datasets like Financial Phrasebank. These datasets typically feature undefined sentiment classes that reflect the highly individualized perspectives of annotators, leading to significant variability in annotations. This variability results in an unfair expectation for LLMs during benchmarking, where they are tasked to conjecture the subjective viewpoints of human annotators without sufficient context. In this paper, we introduce the Annotators' Instruction Assisted Prompt, a novel evaluation prompt designed to redefine the task definition of FSA for LLMs. By integrating detailed task instructions originally intended for human annotators into the LLMs' prompt framework, AIAP aims to standardize the understanding of sentiment across both human and machine interpretations, providing a fair and context-rich foundation for sentiment analysis. We utilize a new dataset, WSBS, derived from the WallStreetBets subreddit to demonstrate how AIAP significantly enhances LLM performance by aligning machine operations with the refined task definitions. Experimental results demonstrate that AIAP enhances LLM performance significantly, with improvements up to 9.08. This context-aware approach not only yields incremental gains in performance but also introduces an innovative sentiment-indexing method utilizing model confidence scores. This method enhances stock price prediction models and extracts more value from the financial sentiment analysis, underscoring the significance of WSB as a critical source of financial text. Our research offers insights into both improving FSA through better evaluation methods.
MLCTR: A Fast Scalable Coupled Tensor Completion Based on Multi-Layer Non-Linear Matrix Factorization
Sep 04, 2021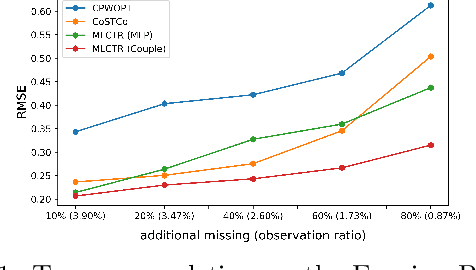

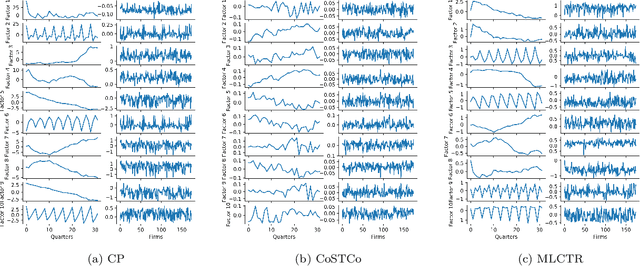
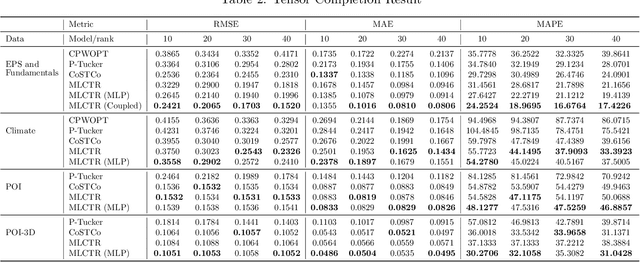
Firms earning prediction plays a vital role in investment decisions, dividends expectation, and share price. It often involves multiple tensor-compatible datasets with non-linear multi-way relationships, spatiotemporal structures, and different levels of sparsity. Current non-linear tensor completion algorithms tend to learn noisy embedding and incur overfitting. This paper focuses on the embedding learning aspect of the tensor completion problem and proposes a new multi-layer neural network architecture for tensor factorization and completion (MLCTR). The network architecture entails multiple advantages: a series of low-rank matrix factorizations (MF) building blocks to minimize overfitting, interleaved transfer functions in each layer for non-linearity, and by-pass connections to reduce the gradient diminishing problem and increase the depths of neural networks. Furthermore, the model employs Stochastic Gradient Descent(SGD) based optimization for fast convergence in training. Our algorithm is highly efficient for imputing missing values in the EPS data. Experiments confirm that our strategy of incorporating non-linearity in factor matrices demonstrates impressive performance in embedding learning and end-to-end tensor models, and outperforms approaches with non-linearity in the phase of reconstructing tensors from factor matrices.