 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dense Exploration for LLM Reinforcement Learning via Pivot-Driven Resampling
Feb 15, 2026Effective exploration is a key challenge in reinforcement learning for large language models: discovering high-quality trajectories within a limited sampling budget from the vast natural language sequence space. Existing methods face notable limitations: GRPO samples exclusively from the root, saturating high-probability trajectories while leaving deep, error-prone states under-explored. Tree-based methods blindly disperse budgets across trivial or unrecoverable states, causing sampling dilution that fails to uncover rare correct suffixes and destabilizes local baselines. To address this, we propose Deep Dense Exploration (DDE), a strategy that focuses exploration on $\textit{pivots}$-deep, recoverable states within unsuccessful trajectories. We instantiate DDE with DEEP-GRPO, which introduces three key innovations: (1) a lightweight data-driven utility function that automatically balances recoverability and depth bias to identify pivot states; (2) local dense resampling at each pivot to increase the probability of discovering correct subsequent trajectories; and (3) a dual-stream optimization objective that decouples global policy learning from local corrective updates. Experiments on mathematical reasoning benchmarks demonstrate that our method consistently outperforms GRPO, tree-based methods, and other strong baselines.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
May 29, 2025Enhancing the reasoning capabilities of large language models effectively using reinforcement learning (RL) remains a crucial challenge. Existing approaches primarily adopt two contrasting advantage estimation granularities: Token-level methods (e.g., PPO) aim to provide the fine-grained advantage signals but suffer from inaccurate estimation due to difficulties in training an accurate critic model. On the other extreme, trajectory-level methods (e.g., GRPO) solely rely on a coarse-grained advantage signal from the final reward, leading to imprecise credit assignment. To address these limitations, we propose Segment Policy Optimization (SPO), a novel RL framework that leverages segment-level advantage estimation at an intermediate granularity, achieving a better balance by offering more precise credit assignment than trajectory-level methods and requiring fewer estimation points than token-level methods, enabling accurate advantage estimation based on Monte Carlo (MC) without a critic model. SPO features three components with novel strategies: (1) flexible segment partition; (2) accurate segment advantage estimation; and (3) policy optimization using segment advantages, including a novel probability-mask strategy. We further instantiate SPO for two specific scenarios: (1) SPO-chain for short chain-of-thought (CoT), featuring novel cutpoint-based partition and chain-based advantage estimation, achieving $6$-$12$ percentage point improvements in accuracy over PPO and GRPO on GSM8K. (2) SPO-tree for long CoT, featuring novel tree-based advantage estimation, which significantly reduces the cost of MC estimation, achieving $7$-$11$ percentage point improvements over GRPO on MATH500 under 2K and 4K context evaluation. We make our code publicly available at https://github.com/AIFrameResearch/SPO.
Creating Auxiliary Representations from Charge Definitions for Criminal Charge Prediction
Nov 12, 2019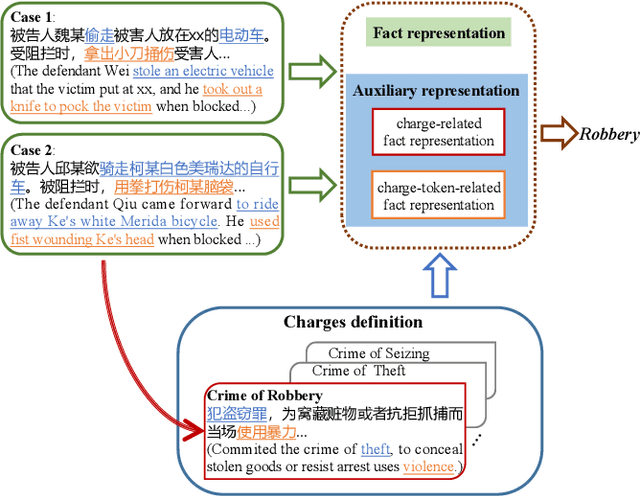
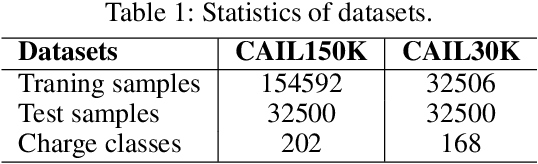
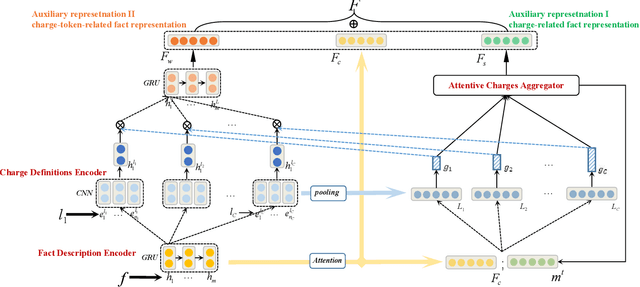
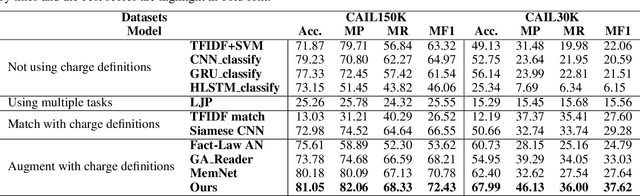
Charge prediction, determining charges for criminal cases by analyzing the textual fact descriptions, is a promising technology in legal assistant systems. In practice, the fact descriptions could exhibit a significant intra-class variation due to factors like non-normative use of language, which makes the prediction task very challenging, especially for charge classes with too few samples to cover the expression variation. In this work, we explore to use the charge definitions from criminal law to alleviate this issue. The key idea is that the expressions in a fact description should have corresponding formal terms in charge definitions, and those terms are shared across classes and could account for the diversity in the fact descriptions. Thus, we propose to create auxiliary fact representations from charge definitions to augment fact descriptions representation. The generated auxiliary representations are created through the interaction of fact description with the relevant charge definitions and terms in those definitions by integrated sentence- and word-level attention scheme. Experimental results on two datasets show that our model achieves significant improvement than baselines, especially for classes with few samples.
Question Answering over Freebase via Attentive RNN with Similarity Matrix based CNN
May 27, 2018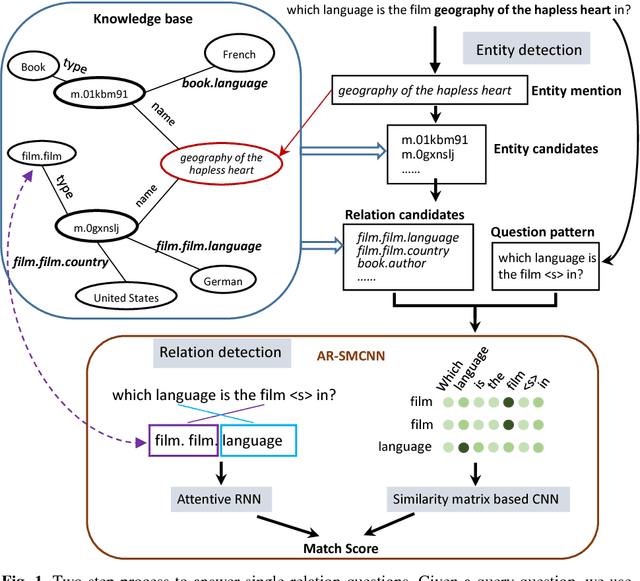
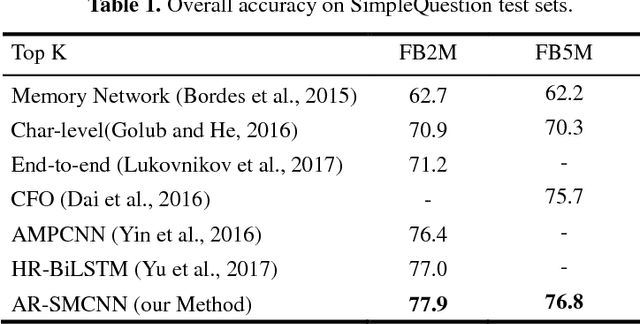
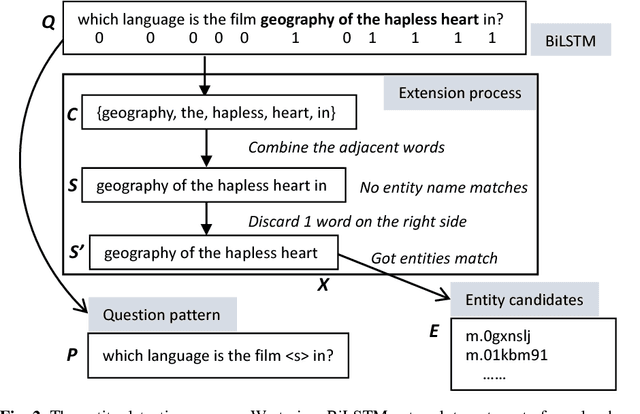
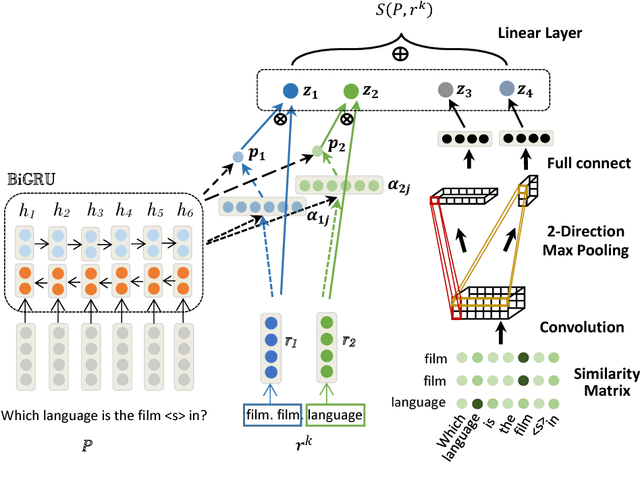
With the rapid growth of knowledge bases (KBs), question answering over knowledge base, a.k.a. KBQA has drawn huge attention in recent years. Most of the existing KBQA methods follow so called encoder-compare framework. They map the question and the KB facts to a common embedding space, in which the similarity between the question vector and the fact vectors can be conveniently computed. This, however, inevitably loses original words interaction information. To preserve more original information, we propose an attentive recurrent neural network with similarity matrix based convolutional neural network (AR-SMCNN) model, which is able to capture comprehensive hierarchical information utilizing the advantages of both RNN and CNN. We use RNN to capture semantic-level correlation by its sequential modeling nature, and use an attention mechanism to keep track of the entities and relations simultaneously. Meanwhile, we use a similarity matrix based CNN with two-directions pooling to extract literal-level words interaction matching utilizing CNNs strength of modeling spatial correlation among data. Moreover, we have developed a new heuristic extension method for entity detection, which significantly decreases the effect of noise. Our method has outperformed the state-of-the-arts on SimpleQuestion benchmark in both accuracy and efficiency.