 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-estimation under Two-Phase Multiwave Sampling with Applications to Prediction-Powered Inference
Feb 18, 2026In two-phase multiwave sampling, inexpensive measurements are collected on a large sample and expensive, more informative measurements are adaptively obtained on subsets of units across multiple waves. Adaptively collecting the expensive measurements can increase efficiency but complicates statistical inference. We give valid estimators and confidence intervals for M-estimation under adaptive two-phase multiwave sampling. We focus on the case where proxies for the expensive variables -- such as predictions from pretrained machine learning models -- are available for all units and propose a Multiwave Predict-Then-Debias estimator that combines proxy information with the expensive, higher-quality measurements to improve efficiency while removing bias. We establish asymptotic linearity and normality and propose asymptotically valid confidence intervals. We also develop an approximately greedy sampling strategy that improves efficiency relative to uniform sampling. Data-based simulation studies support the theoretical results and demonstrate efficiency gains.
Conformal Prediction Sets for Instance Segmentation
Feb 10, 2026Current instance segmentation models achieve high performance on average predictions, but lack principled uncertainty quantification: their outputs are not calibrated, and there is no guarantee that a predicted mask is close to the ground truth. To address this limitation, we introduce a conformal prediction algorithm to generate adaptive confidence sets for instance segmentation. Given an image and a pixel coordinate query, our algorithm generates a confidence set of instance predictions for that pixel, with a provable guarantee for the probability that at least one of the predictions has high Intersection-Over-Union (IoU) with the true object instance mask. We apply our algorithm to instance segmentation examples in agricultural field delineation, cell segmentation, and vehicle detection. Empirically, we find that our prediction sets vary in size based on query difficulty and attain the target coverage, outperforming existing baselines such as Learn Then Test, Conformal Risk Control, and morphological dilation-based methods. We provide versions of the algorithm with asymptotic and finite sample guarantees.
Demystifying Prediction Powered Inference
Jan 28, 2026Machine learning predictions are increasingly used to supplement incomplete or costly-to-measure outcomes in fields such as biomedical research, environmental science, and social science. However, treating predictions as ground truth introduces bias while ignoring them wastes valuable information. Prediction-Powered Inference (PPI) offers a principled framework that leverages predictions from large unlabeled datasets to improve statistical efficiency while maintaining valid inference through explicit bias correction using a smaller labeled subset. Despite its potential, the growing PPI variants and the subtle distinctions between them have made it challenging for practitioners to determine when and how to apply these methods responsibly. This paper demystifies PPI by synthesizing its theoretical foundations, methodological extensions, connections to existing statistics literature, and diagnostic tools into a unified practical workflow. Using the Mosaiks housing price data, we show that PPI variants produce tighter confidence intervals than complete-case analysis, but that double-dipping, i.e. reusing training data for inference, leads to anti-conservative confidence intervals and coverages. Under missing-not-at-random mechanisms, all methods, including classical inference using only labeled data, yield biased estimates. We provide a decision flowchart linking assumption violations to appropriate PPI variants, a summary table of selective methods, and practical diagnostic strategies for evaluating core assumptions. By framing PPI as a general recipe rather than a single estimator, this work bridges methodological innovation and applied practice, helping researchers responsibly integrate predictions into valid inference.
Prediction-Powered Inference with Imputed Covariates and Nonuniform Sampling
Jan 30, 2025



Machine learning models are increasingly used to produce predictions that serve as input data in subsequent statistical analyses. For example, computer vision predictions of economic and environmental indicators based on satellite imagery are used in downstream regressions; similarly, language models are widely used to approximate human ratings and opinions in social science research. However, failure to properly account for errors in the machine learning predictions renders standard statistical procedures invalid. Prior work uses what we call the Predict-Then-Debias estimator to give valid confidence intervals when machine learning algorithms impute missing variables, assuming a small complete sample from the population of interest. We expand the scope by introducing bootstrap confidence intervals that apply when the complete data is a nonuniform (i.e., weighted, stratified, or clustered) sample and to settings where an arbitrary subset of features is imputed. Importantly, the method can be applied to many settings without requiring additional calculations. We prove that these confidence intervals are valid under no assumptions on the quality of the machine learning model and are no wider than the intervals obtained by methods that do not use machine learning predictions.
Two Shifts for Crop Mapping: Leveraging Aggregate Crop Statistics to Improve Satellite-based Maps in New Regions
Sep 02, 2021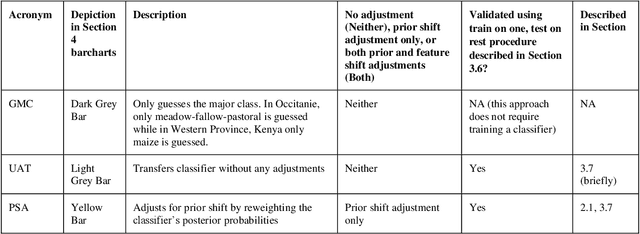
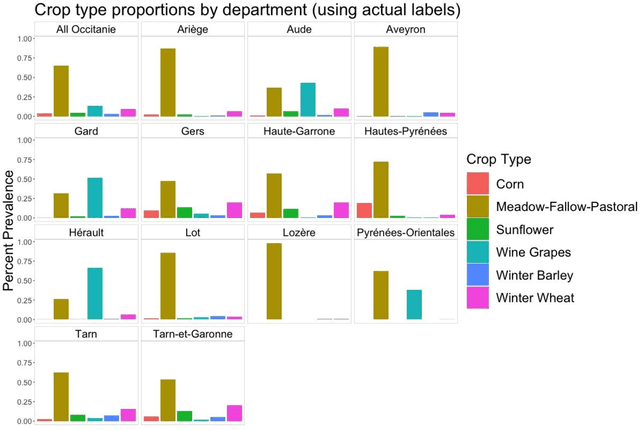
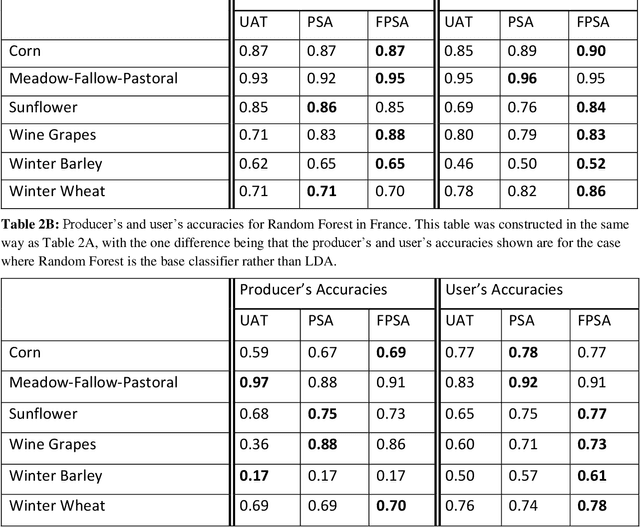
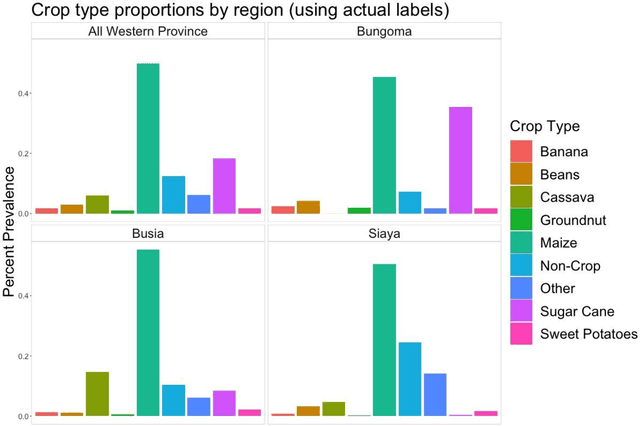
Crop type mapping at the field level is critical for a variety of applications in agricultural monitoring, and satellite imagery is becoming an increasingly abundant and useful raw input from which to create crop type maps. Still, in many regions crop type mapping with satellite data remains constrained by a scarcity of field-level crop labels for training supervised classification models. When training data is not available in one region, classifiers trained in similar regions can be transferred, but shifts in the distribution of crop types as well as transformations of the features between regions lead to reduced classification accuracy. We present a methodology that uses aggregate-level crop statistics to correct the classifier by accounting for these two types of shifts. To adjust for shifts in the crop type composition we present a scheme for properly reweighting the posterior probabilities of each class that are output by the classifier. To adjust for shifts in features we propose a method to estimate and remove linear shifts in the mean feature vector. We demonstrate that this methodology leads to substantial improvements in overall classification accuracy when using Linear Discriminant Analysis (LDA) to map crop types in Occitanie, France and in Western Province, Kenya. When using LDA as our base classifier, we found that in France our methodology led to percent reductions in misclassifications ranging from 2.8% to 42.2% (mean = 21.9%) over eleven different training departments, and in Kenya the percent reductions in misclassification were 6.6%, 28.4%, and 42.7% for three training regions. While our methodology was statistically motivated by the LDA classifier, it can be applied to any type of classifier. As an example, we demonstrate its successful application to improve a Random Forest classifier.
* This is the revised version of the paper which was submitted to Remote Sensing of Environment on May 3, 2021, immediately prior to acceptance for publication