 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Concept Learning for Uncovering Latent Themes in Large Text Collections
May 08, 2023



Experts across diverse disciplines are often interested in making sense of large text collections. Traditionally, this challenge is approached either by noisy unsupervised techniques such as topic models, or by following a manual theme discovery process. In this paper, we expand the definition of a theme to account for more than just a word distribution, and include generalized concepts deemed relevant by domain experts. Then, we propose an interactive framework that receives and encodes expert feedback at different levels of abstraction. Our framework strikes a balance between automation and manual coding, allowing experts to maintain control of their study while reducing the manual effort required.
Analysis of Climate Campaigns on Social Media using Bayesian Model Averaging
May 06, 2023



Climate change is the defining issue of our time, and we are at a defining moment. Various interest groups, social movement organizations, and individuals engage in collective action on this issue on social media. In addition, issue advocacy campaigns on social media often arise in response to ongoing societal concerns, especially those faced by energy industries. Our goal in this paper is to analyze how those industries, their advocacy group, and climate advocacy group use social media to influence the narrative on climate change. In this work, we propose a minimally supervised model soup [56] approach combined with messaging themes to identify the stances of climate ads on Facebook. Finally, we release our stance dataset, model, and set of themes related to climate campaigns for future work on opinion mining and the automatic detection of climate change stances.
KNOD: Domain Knowledge Distilled Tree Decoder for Automated Program Repair
Feb 03, 2023Automated Program Repair (APR) improves software reliability by generating patches for a buggy program automatically. Recent APR techniques leverage deep learning (DL) to build models to learn to generate patches from existing patches and code corpora. While promising, DL-based APR techniques suffer from the abundant syntactically or semantically incorrect patches in the patch space. These patches often disobey the syntactic and semantic domain knowledge of source code and thus cannot be the correct patches to fix a bug. We propose a DL-based APR approach KNOD, which incorporates domain knowledge to guide patch generation in a direct and comprehensive way. KNOD has two major novelties, including (1) a novel three-stage tree decoder, which directly generates Abstract Syntax Trees of patched code according to the inherent tree structure, and (2) a novel domain-rule distillation, which leverages syntactic and semantic rules and teacher-student distributions to explicitly inject the domain knowledge into the decoding procedure during both the training and inference phases. We evaluate KNOD on three widely-used benchmarks. KNOD fixes 72 bugs on the Defects4J v1.2, 25 bugs on the QuixBugs, and 50 bugs on the additional Defects4J v2.0 benchmarks, outperforming all existing APR tools.
Towards Few-Shot Identification of Morality Frames using In-Context Learning
Feb 03, 2023



Data scarcity is a common problem in NLP, especially when the annotation pertains to nuanced socio-linguistic concepts that require specialized knowledge. As a result, few-shot identification of these concepts is desirable. Few-shot in-context learning using pre-trained Large Language Models (LLMs) has been recently applied successfully in many NLP tasks. In this paper, we study few-shot identification of a psycho-linguistic concept, Morality Frames (Roy et al., 2021), using LLMs. Morality frames are a representation framework that provides a holistic view of the moral sentiment expressed in text, identifying the relevant moral foundation (Haidt and Graham, 2007) and at a finer level of granularity, the moral sentiment expressed towards the entities mentioned in the text. Previous studies relied on human annotation to identify morality frames in text which is expensive. In this paper, we propose prompting-based approaches using pretrained Large Language Models for identification of morality frames, relying only on few-shot exemplars. We compare our models' performance with few-shot RoBERTa and found promising results.
Towards Explaining Subjective Ground of Individuals on Social Media
Nov 18, 2022Large-scale language models have been reducing the gap between machines and humans in understanding the real world, yet understanding an individual's theory of mind and behavior from text is far from being resolved. This research proposes a neural model -- Subjective Ground Attention -- that learns subjective grounds of individuals and accounts for their judgments on situations of others posted on social media. Using simple attention modules as well as taking one's previous activities into consideration, we empirically show that our model provides human-readable explanations of an individual's subjective preference in judging social situations. We further qualitatively evaluate the explanations generated by the model and claim that our model learns an individual's subjective orientation towards abstract moral concepts
Weakly Supervised Learning for Analyzing Political Campaigns on Facebook
Oct 19, 2022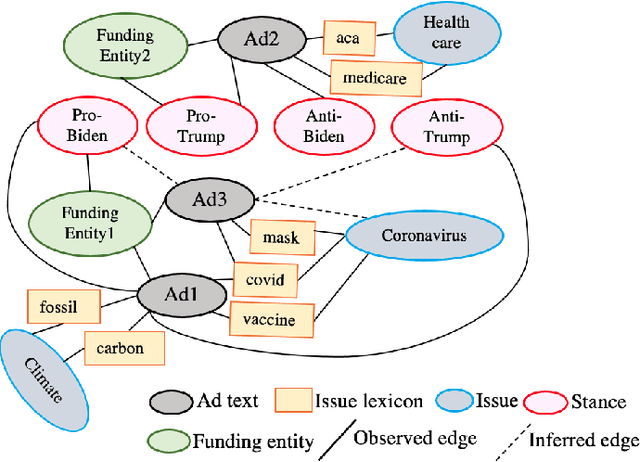
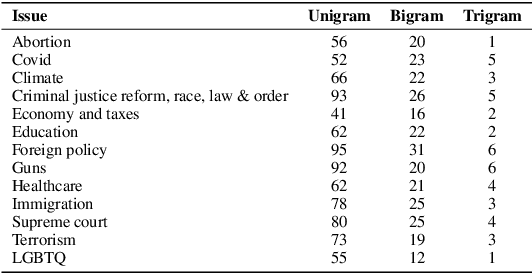
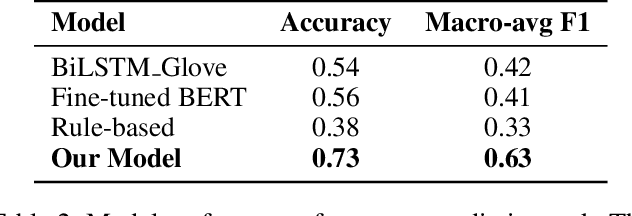
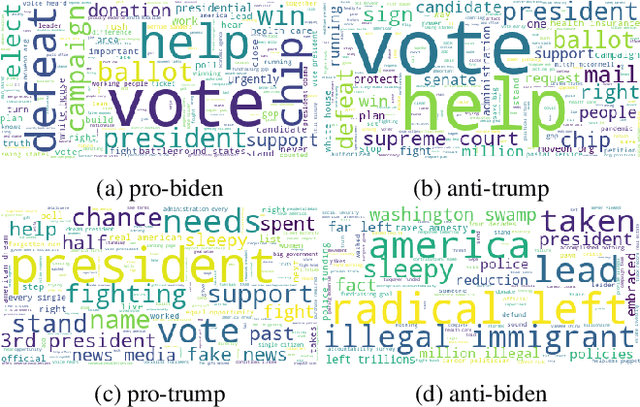
Social media platforms are currently the main channel for political messaging, allowing politicians to target specific demographics and adapt based on their reactions. However, making this communication transparent is challenging, as the messaging is tightly coupled with its intended audience and often echoed by multiple stakeholders interested in advancing specific policies. Our goal in this paper is to take a first step towards understanding these highly decentralized settings. We propose a weakly supervised approach to identify the stance and issue of political ads on Facebook and analyze how political campaigns use some kind of demographic targeting by location, gender, or age. Furthermore, we analyze the temporal dynamics of the political ads on election polls.
Understanding COVID-19 Vaccine Campaign on Facebook using Minimal Supervision
Oct 18, 2022
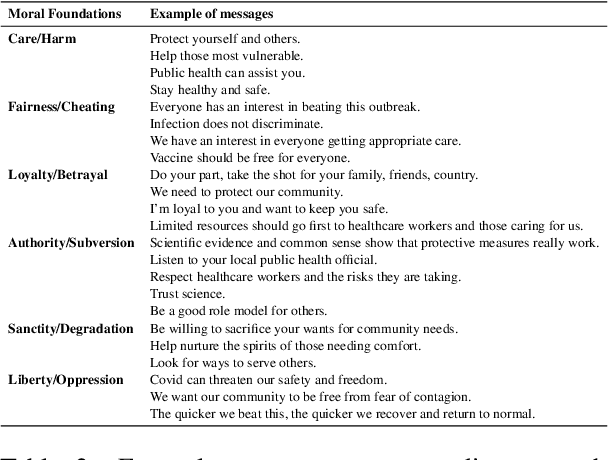
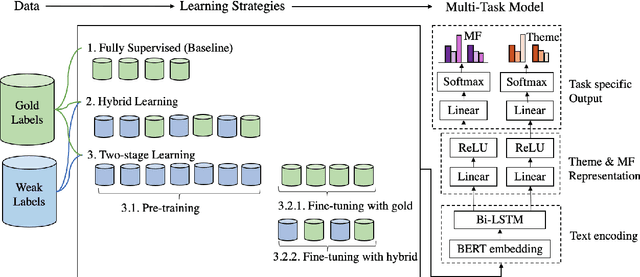
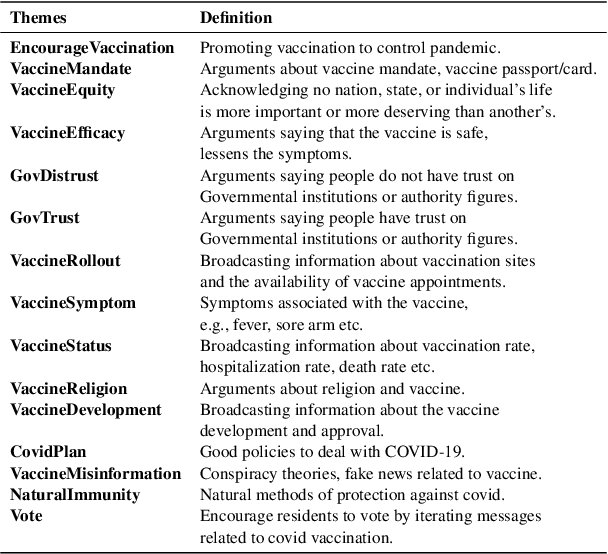
In the age of social media, where billions of internet users share information and opinions, the negative impact of pandemics is not limited to the physical world. It provokes a surge of incomplete, biased, and incorrect information, also known as an infodemic. This global infodemic jeopardizes measures to control the pandemic by creating panic, vaccine hesitancy, and fragmented social response. Platforms like Facebook allow advertisers to adapt their messaging to target different demographics and help alleviate or exacerbate the infodemic problem depending on their content. In this paper, we propose a minimally supervised multi-task learning framework for understanding messaging on Facebook related to the covid vaccine by identifying ad themes and moral foundations. Furthermore, we perform a more nuanced thematic analysis of messaging tactics of vaccine campaigns on social media so that policymakers can make better decisions on pandemic control.
A Holistic Framework for Analyzing the COVID-19 Vaccine Debate
May 03, 2022


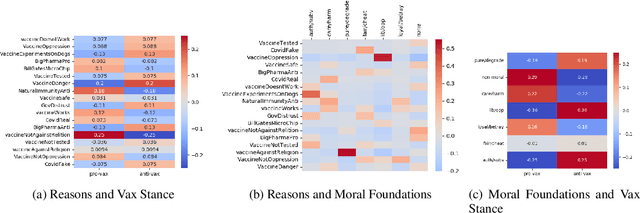
The Covid-19 pandemic has led to infodemic of low quality information leading to poor health decisions. Combating the outcomes of this infodemic is not only a question of identifying false claims, but also reasoning about the decisions individuals make. In this work we propose a holistic analysis framework connecting stance and reason analysis, and fine-grained entity level moral sentiment analysis. We study how to model the dependencies between the different level of analysis and incorporate human insights into the learning process. Experiments show that our framework provides reliable predictions even in the low-supervision settings.
Automated Attack Synthesis by Extracting Finite State Machines from Protocol Specification Documents
Feb 18, 2022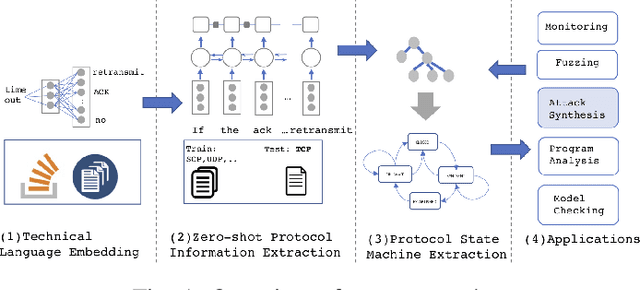
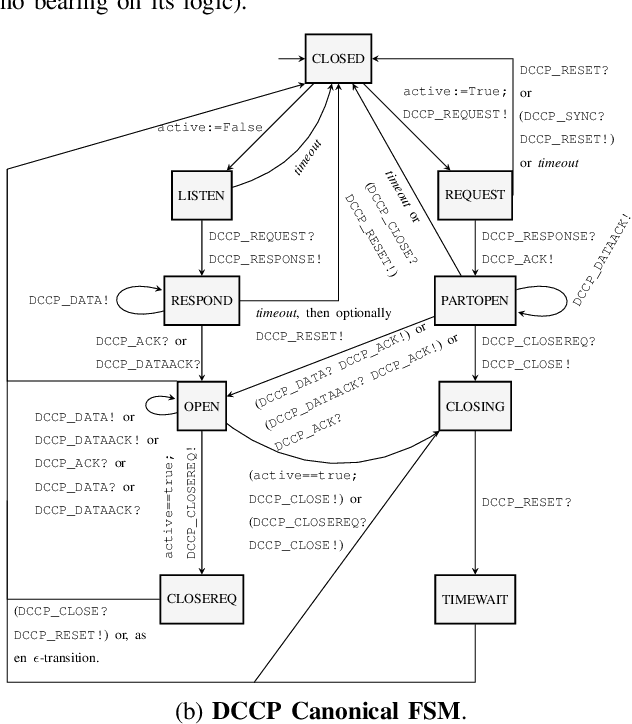

Automated attack discovery techniques, such as attacker synthesis or model-based fuzzing, provide powerful ways to ensure network protocols operate correctly and securely. Such techniques, in general, require a formal representation of the protocol, often in the form of a finite state machine (FSM). Unfortunately, many protocols are only described in English prose, and implementing even a simple network protocol as an FSM is time-consuming and prone to subtle logical errors. Automatically extracting protocol FSMs from documentation can significantly contribute to increased use of these techniques and result in more robust and secure protocol implementations. In this work we focus on attacker synthesis as a representative technique for protocol security, and on RFCs as a representative format for protocol prose description. Unlike other works that rely on rule-based approaches or use off-the-shelf NLP tools directly, we suggest a data-driven approach for extracting FSMs from RFC documents. Specifically, we use a hybrid approach consisting of three key steps: (1) large-scale word-representation learning for technical language, (2) focused zero-shot learning for mapping protocol text to a protocol-independent information language, and (3) rule-based mapping from protocol-independent information to a specific protocol FSM. We show the generalizability of our FSM extraction by using the RFCs for six different protocols: BGPv4, DCCP, LTP, PPTP, SCTP and TCP. We demonstrate how automated extraction of an FSM from an RFC can be applied to the synthesis of attacks, with TCP and DCCP as case-studies. Our approach shows that it is possible to automate attacker synthesis against protocols by using textual specifications such as RFCs.
Identifying Morality Frames in Political Tweets using Relational Learning
Sep 09, 2021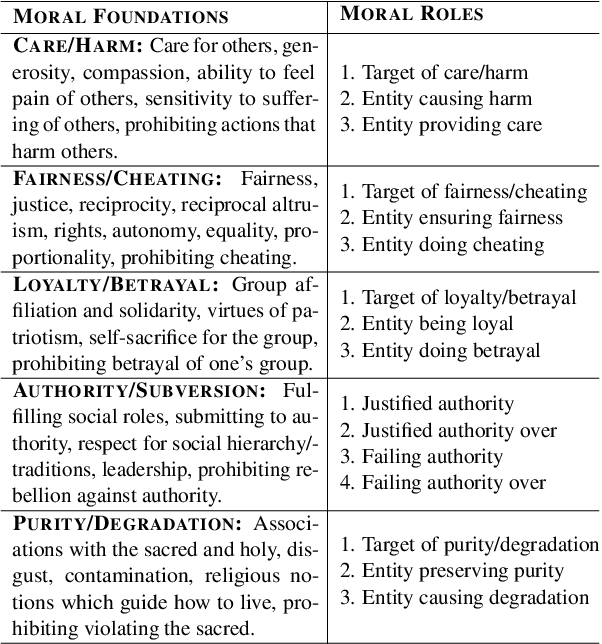
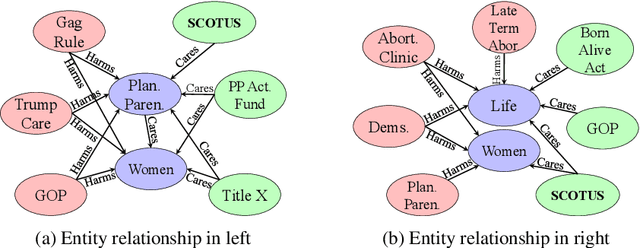
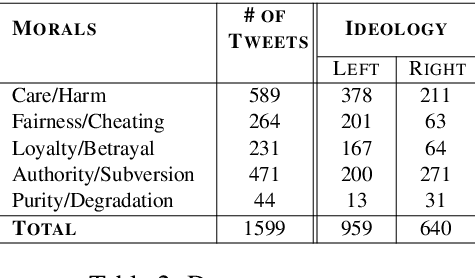
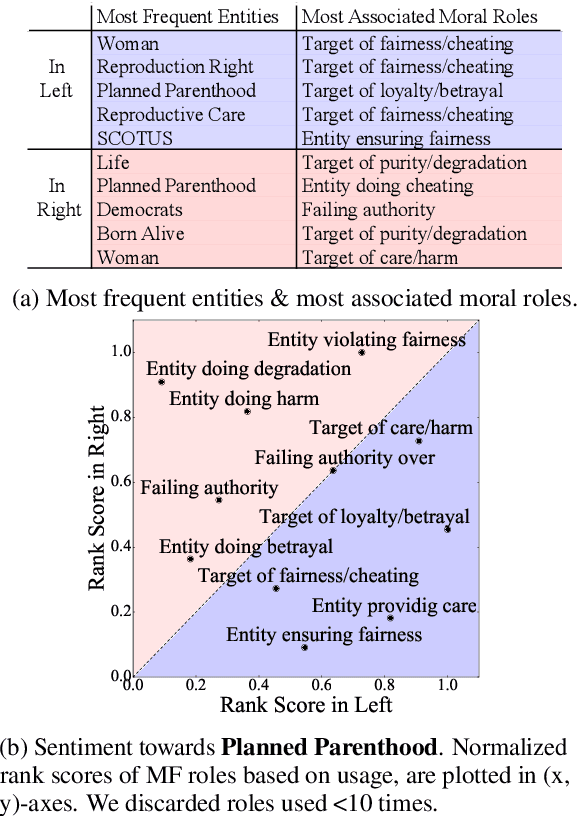
Extracting moral sentiment from text is a vital component in understanding public opinion, social movements, and policy decisions. The Moral Foundation Theory identifies five moral foundations, each associated with a positive and negative polarity. However, moral sentiment is often motivated by its targets, which can correspond to individuals or collective entities. In this paper, we introduce morality frames, a representation framework for organizing moral attitudes directed at different entities, and come up with a novel and high-quality annotated dataset of tweets written by US politicians. Then, we propose a relational learning model to predict moral attitudes towards entities and moral foundations jointly. We do qualitative and quantitative evaluations, showing that moral sentiment towards entities differs highly across political ideologies.