 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Exposure Burst Image Restoration
Mar 23, 2026Burst image restoration aims to reconstruct a high-quality image from burst images, which are typically captured using manually designed exposure settings. Although these exposure settings significantly influence the final restoration performance, the problem of finding optimal exposure settings has been overlooked. In this paper, we present Dynamic Exposure Burst Image Restoration (DEBIR), a novel burst image restoration pipeline that enhances restoration quality by dynamically predicting exposure times tailored to the shooting environment. In our pipeline, Burst Auto-Exposure Network (BAENet) estimates the optimal exposure time for each burst image based on a preview image, as well as motion magnitude and gain. Subsequently, a burst image restoration network reconstructs a high-quality image from burst images captured using these optimal exposure times. For training, we introduce a differentiable burst simulator and a three-stage training strategy. Our experiments demonstrate that our pipeline achieves state-of-the-art restoration quality. Furthermore, we validate the effectiveness of our approach on a real-world camera system, demonstrating its practicality.
Learning Shared Filter Bases for Efficient ConvNets
Jul 01, 2020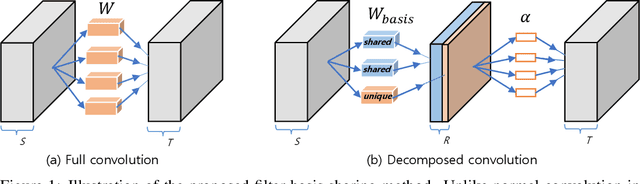

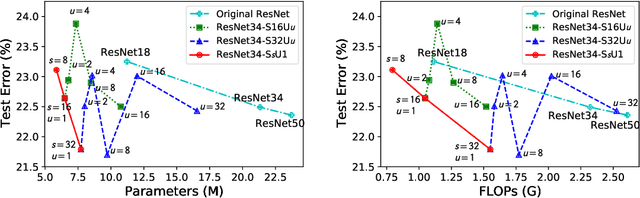
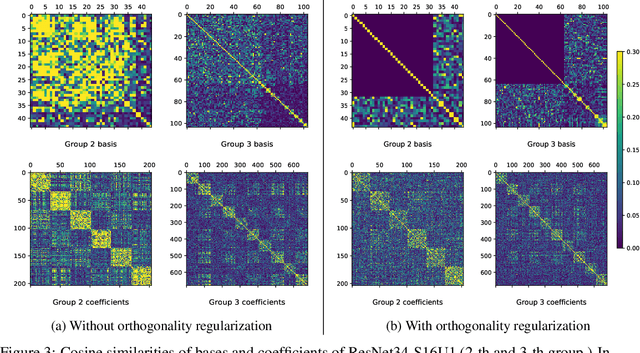
Modern convolutional neural networks (ConvNets) achieve state-of-the-art performance for many computer vision tasks. However, such high performance requires millions of parameters and high computational costs. Recently, inspired by the iterative structure of modern ConvNets, such as ResNets, parameter sharing among repetitive convolution layers has been proposed to reduce the size of parameters. However, naive sharing of convolution filters poses many challenges such as overfitting and vanishing/exploding gradients. Furthermore, parameter sharing often increases computational complexity due to additional operations. In this paper, we propose to exploit the linear structure of convolution filters for effective and efficient sharing of parameters among iterative convolution layers. Instead of sharing convolution filters themselves, we hypothesize that a filter basis of linearly-decomposed convolution layers is a more effective unit for sharing parameters since a filter basis is an intrinsic and reusable building block constituting diverse high dimensional convolution filters. The representation power and peculiarity of individual convolution layers are further increased by adding a small number of layer-specific non-shared components to the filter basis. We show empirically that enforcing orthogonality to shared filter bases can mitigate the difficulty in training shared parameters. Experimental results show that our approach achieves significant reductions both in model parameters and computational costs while maintaining competitive, and often better, performance than non-shared baseline networks.