 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentanglement-based Cross-Domain Feature Augmentation for Effective Unsupervised Domain Adaptive Person Re-identification
Mar 25, 2021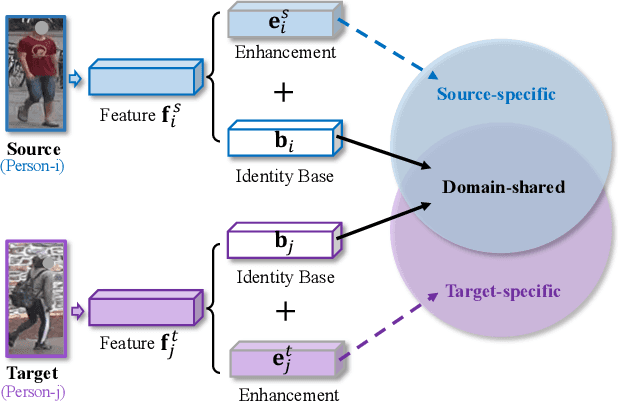
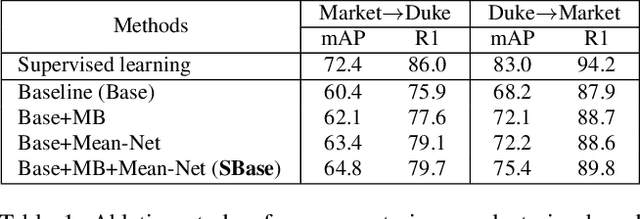
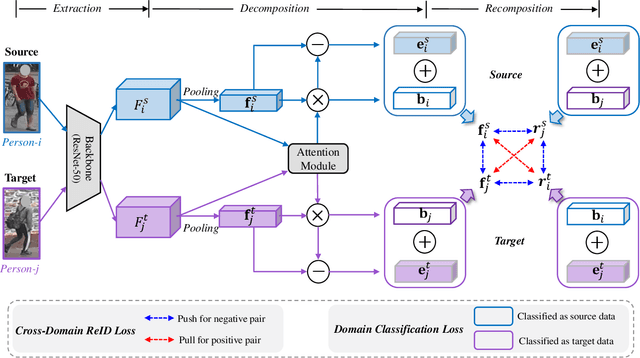
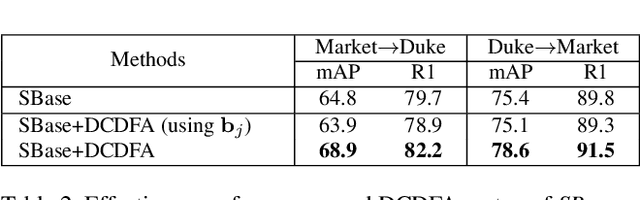
Unsupervised domain adaptive (UDA) person re-identification (ReID) aims to transfer the knowledge from the labeled source domain to the unlabeled target domain for person matching. One challenge is how to generate target domain samples with reliable labels for training. To address this problem, we propose a Disentanglement-based Cross-Domain Feature Augmentation (DCDFA) strategy, where the augmented features characterize well the target and source domain data distributions while inheriting reliable identity labels. Particularly, we disentangle each sample feature into a robust domain-invariant/shared feature and a domain-specific feature, and perform cross-domain feature recomposition to enhance the diversity of samples used in the training, with the constraints of cross-domain ReID loss and domain classification loss. Each recomposed feature, obtained based on the domain-invariant feature (which enables a reliable inheritance of identity) and an enhancement from a domain specific feature (which enables the approximation of real distributions), is thus an "ideal" augmentation. Extensive experimental results demonstrate the effectiveness of our method, which achieves the state-of-the-art performance.
MetaAlign: Coordinating Domain Alignment and Classification for Unsupervised Domain Adaptation
Mar 25, 2021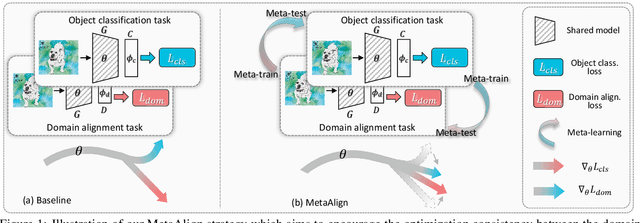
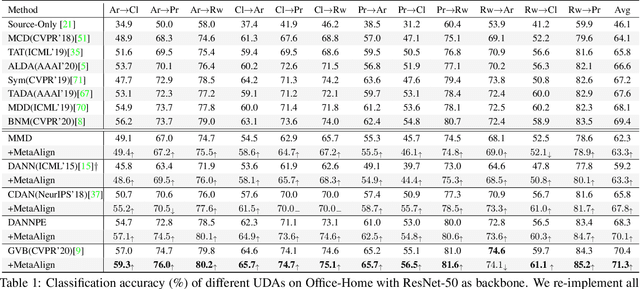
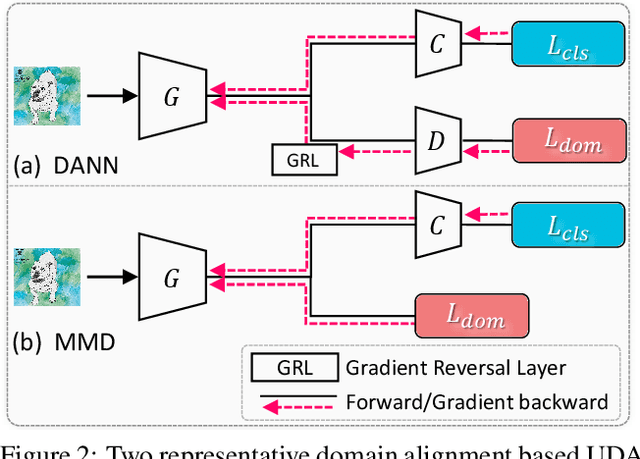
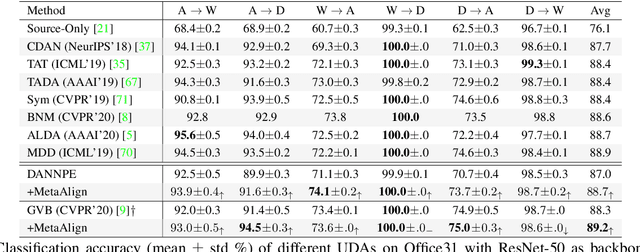
For unsupervised domain adaptation (UDA), to alleviate the effect of domain shift, many approaches align the source and target domains in the feature space by adversarial learning or by explicitly aligning their statistics. However, the optimization objective of such domain alignment is generally not coordinated with that of the object classification task itself such that their descent directions for optimization may be inconsistent. This will reduce the effectiveness of domain alignment in improving the performance of UDA. In this paper, we aim to study and alleviate the optimization inconsistency problem between the domain alignment and classification tasks. We address this by proposing an effective meta-optimization based strategy dubbed MetaAlign, where we treat the domain alignment objective and the classification objective as the meta-train and meta-test tasks in a meta-learning scheme. MetaAlign encourages both tasks to be optimized in a coordinated way, which maximizes the inner product of the gradients of the two tasks during training. Experimental results demonstrate the effectiveness of our proposed method on top of various alignment-based baseline approaches, for tasks of object classification and object detection. MetaAlign helps achieve the state-of-the-art performance.
Re-energizing Domain Discriminator with Sample Relabeling for Adversarial Domain Adaptation
Mar 22, 2021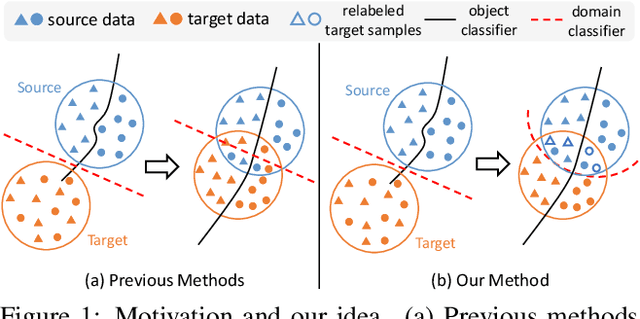
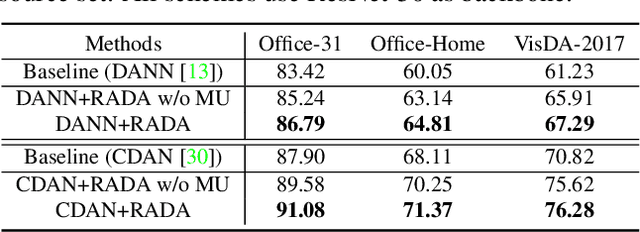
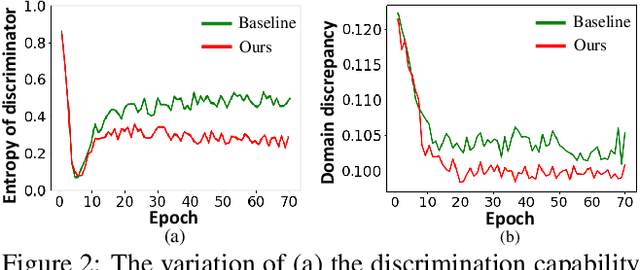
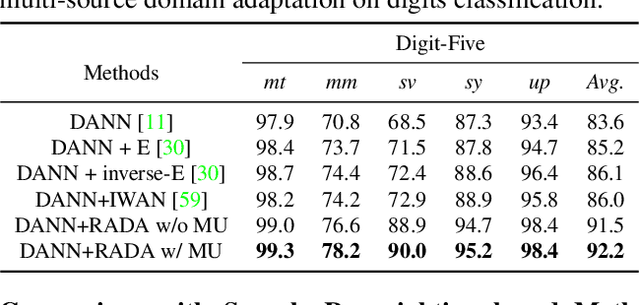
Many unsupervised domain adaptation (UDA) methods exploit domain adversarial training to align the features to reduce domain gap, where a feature extractor is trained to fool a domain discriminator in order to have aligned feature distributions. The discrimination capability of the domain classifier w.r.t the increasingly aligned feature distributions deteriorates as training goes on, thus cannot effectively further drive the training of feature extractor. In this work, we propose an efficient optimization strategy named Re-enforceable Adversarial Domain Adaptation (RADA) which aims to re-energize the domain discriminator during the training by using dynamic domain labels. Particularly, we relabel the well aligned target domain samples as source domain samples on the fly. Such relabeling makes the less separable distributions more separable, and thus leads to a more powerful domain classifier w.r.t. the new data distributions, which in turn further drives feature alignment. Extensive experiments on multiple UDA benchmarks demonstrate the effectiveness and superiority of our RADA.
Generalizing to Unseen Domains: A Survey on Domain Generalization
Mar 10, 2021

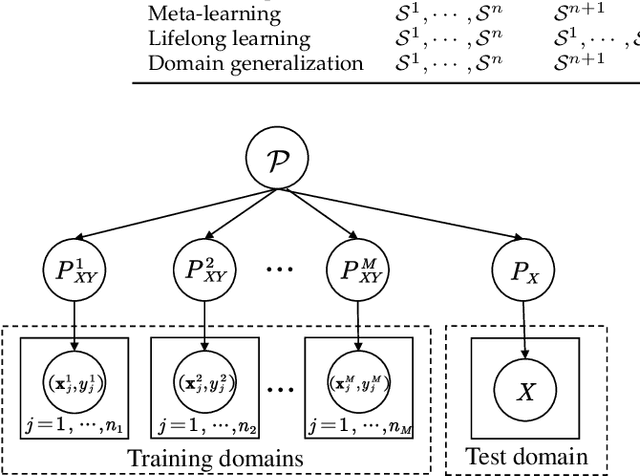
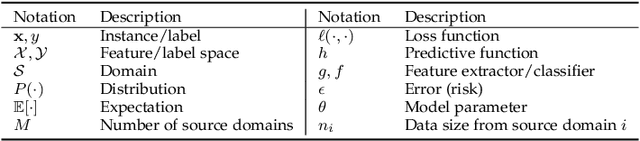
Domain generalization (DG), i.e., out-of-distribution generalization, has attracted increased interests in recent years. Domain generalization deals with a challenging setting where one or several different but related domain(s) are given, and the goal is to learn a model that can generalize to an unseen test domain. For years, great progress has been achieved. This paper presents the first review for recent advances in domain generalization. First, we provide a formal definition of domain generalization and discuss several related fields. Next, we thoroughly review the theories related to domain generalization and carefully analyze the theory behind generalization. Then, we categorize recent algorithms into three classes and present them in detail: data manipulation, representation learning, and learning strategy, each of which contains several popular algorithms. Third, we introduce the commonly used datasets and applications. Finally, we summarize existing literature and present some potential research topics for the future.
AttributeNet: Attribute Enhanced Vehicle Re-Identification
Feb 07, 2021
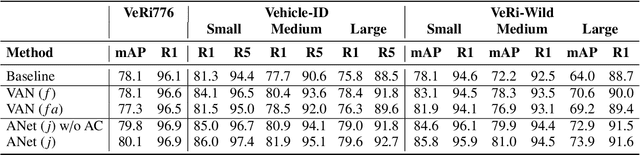
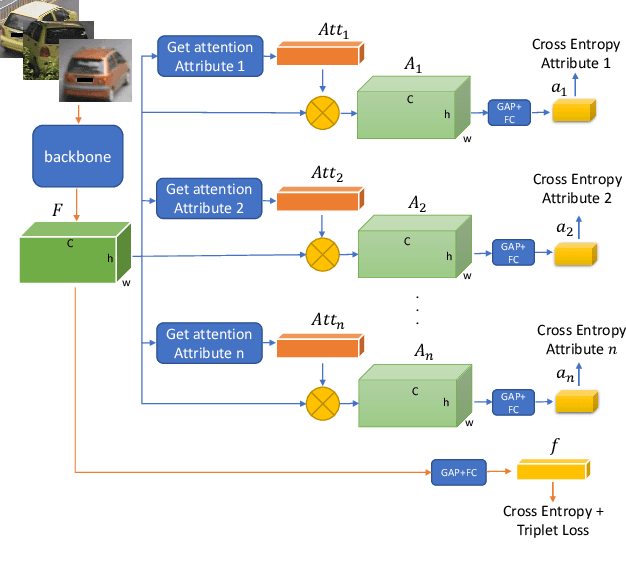

Vehicle Re-Identification (V-ReID) is a critical task that associates the same vehicle across images from different camera viewpoints. Many works explore attribute clues to enhance V-ReID; however, there is usually a lack of effective interaction between the attribute-related modules and final V-ReID objective. In this work, we propose a new method to efficiently explore discriminative information from vehicle attributes (e.g., color and type). We introduce AttributeNet (ANet) that jointly extracts identity-relevant features and attribute features. We enable the interaction by distilling the ReID-helpful attribute feature and adding it into the general ReID feature to increase the discrimination power. Moreover, we propose a constraint, named Amelioration Constraint (AC), which encourages the feature after adding attribute features onto the general ReID feature to be more discriminative than the original general ReID feature. We validate the effectiveness of our framework on three challenging datasets. Experimental results show that our method achieves state-of-the-art performance.
Style Normalization and Restitution for DomainGeneralization and Adaptation
Jan 03, 2021
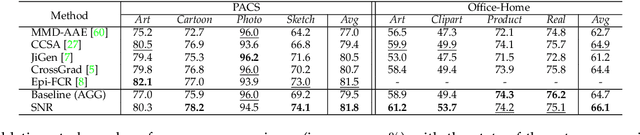
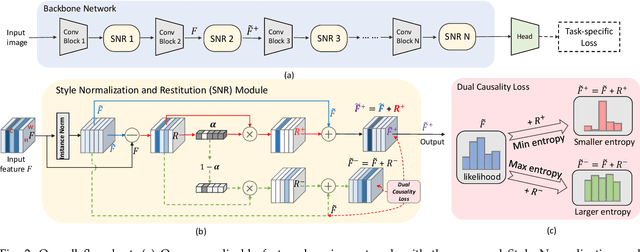
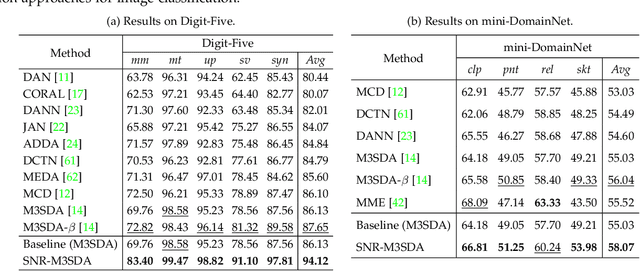
For many practical computer vision applications, the learned models usually have high performance on the datasets used for training but suffer from significant performance degradation when deployed in new environments, where there are usually style differences between the training images and the testing images. An effective domain generalizable model is expected to be able to learn feature representations that are both generalizable and discriminative. In this paper, we design a novel Style Normalization and Restitution module (SNR) to simultaneously ensure both high generalization and discrimination capability of the networks. In the SNR module, particularly, we filter out the style variations (e.g, illumination, color contrast) by performing Instance Normalization (IN) to obtain style normalized features, where the discrepancy among different samples and domains is reduced. However, such a process is task-ignorant and inevitably removes some task-relevant discriminative information, which could hurt the performance. To remedy this, we propose to distill task-relevant discriminative features from the residual (i.e, the difference between the original feature and the style normalized feature) and add them back to the network to ensure high discrimination. Moreover, for better disentanglement, we enforce a dual causality loss constraint in the restitution step to encourage the better separation of task-relevant and task-irrelevant features. We validate the effectiveness of our SNR on different computer vision tasks, including classification, semantic segmentation, and object detection. Experiments demonstrate that our SNR module is capable of improving the performance of networks for domain generalization (DG) and unsupervised domain adaptation (UDA) on many tasks. Code are available at https://github.com/microsoft/SNR.
Exploiting Sample Uncertainty for Domain Adaptive Person Re-Identification
Dec 17, 2020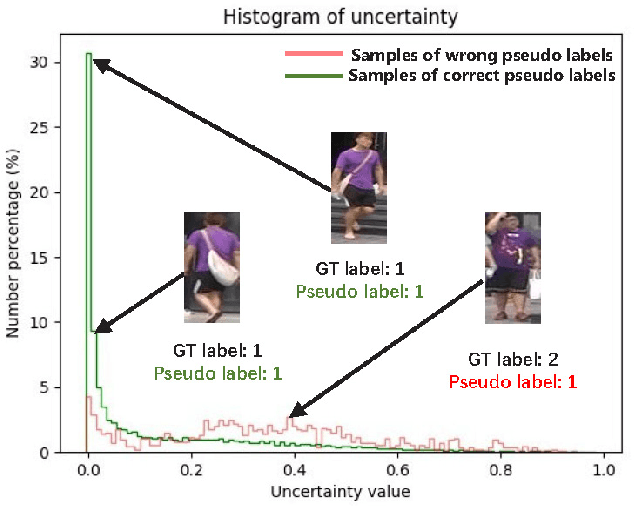
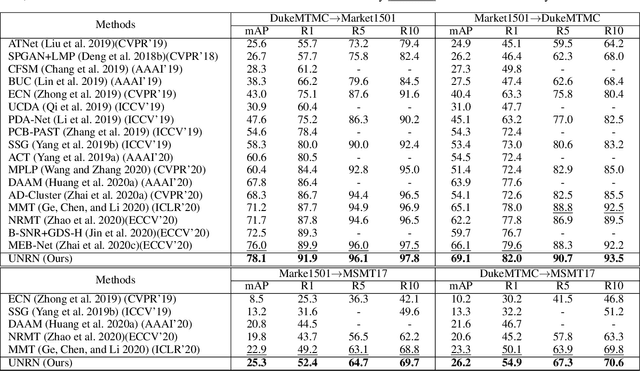
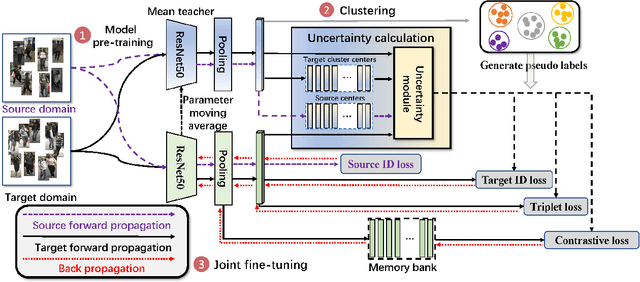
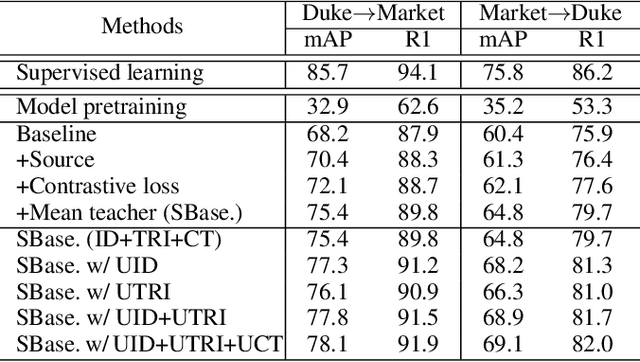
Many unsupervised domain adaptive (UDA) person re-identification (ReID) approaches combine clustering-based pseudo-label prediction with feature fine-tuning. However, because of domain gap, the pseudo-labels are not always reliable and there are noisy/incorrect labels. This would mislead the feature representation learning and deteriorate the performance. In this paper, we propose to estimate and exploit the credibility of the assigned pseudo-label of each sample to alleviate the influence of noisy labels, by suppressing the contribution of noisy samples. We build our baseline framework using the mean teacher method together with an additional contrastive loss. We have observed that a sample with a wrong pseudo-label through clustering in general has a weaker consistency between the output of the mean teacher model and the student model. Based on this finding, we propose to exploit the uncertainty (measured by consistency levels) to evaluate the reliability of the pseudo-label of a sample and incorporate the uncertainty to re-weight its contribution within various ReID losses, including the identity (ID) classification loss per sample, the triplet loss, and the contrastive loss. Our uncertainty-guided optimization brings significant improvement and achieves the state-of-the-art performance on benchmark datasets.
Uncertainty-Aware Few-Shot Image Classification
Oct 09, 2020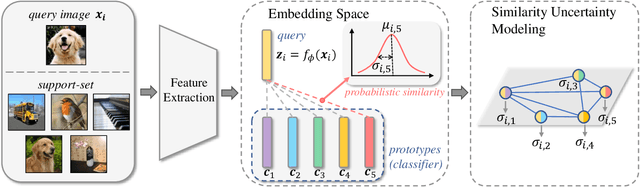

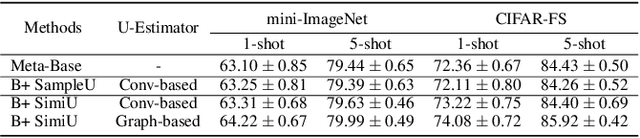
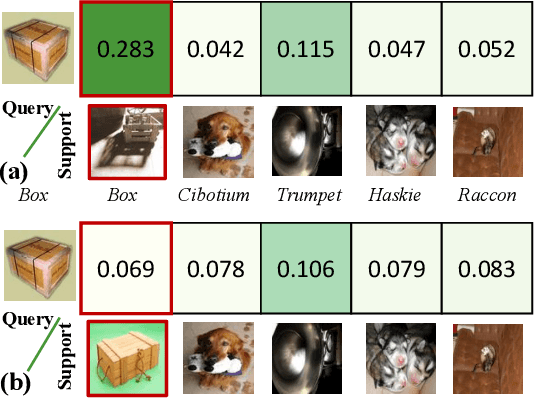
Few-shot image classification aims to learn to recognize new categories from limited labelled data. Recently, metric learning based approaches have been widely investigated which classify a query sample by finding the nearest prototype from the support set based on the feature similarities. For few-shot classification, the calculated similarity of a query-support pair depends on both the query and the support. The network has different confidences/uncertainty on the calculated similarities of the different pairs and there are observation noises on the similarity. Understanding and modeling the uncertainty on the similarity could promote better exploitation of the limited samples in optimization. However, this is still underexplored in few-shot learning. In this work, we propose Uncertainty-Aware Few-Shot (UAFS) image classification by modeling uncertainty of the similarities of query-support pairs and performing uncertainty-aware optimization. Particularly, we design a graph-based model to jointly estimate the uncertainty of similarities between a query and the prototypes in the support set. We optimize the network based on the modeled uncertainty by converting the observed similarity to a probabilistic similarity distribution to be robust to observation noises. Extensive experiments show our proposed method brings significant improvements on top of a strong baseline and achieves the state-of-the-art performance.
Feature Alignment and Restoration for Domain Generalization and Adaptation
Jun 22, 2020

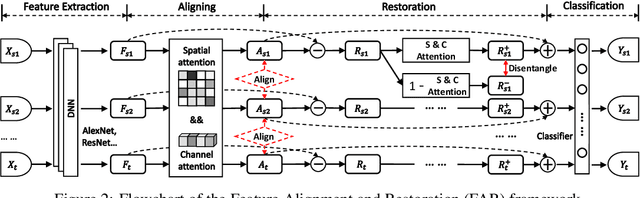
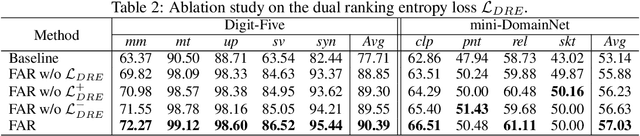
For domain generalization (DG) and unsupervised domain adaptation (UDA), cross domain feature alignment has been widely explored to pull the feature distributions of different domains in order to learn domain-invariant representations. However, the feature alignment is in general task-ignorant and could result in degradation of the discrimination power of the feature representation and thus hinders the high performance. In this paper, we propose a unified framework termed Feature Alignment and Restoration (FAR) to simultaneously ensure high generalization and discrimination power of the networks for effective DG and UDA. Specifically, we perform feature alignment (FA) across domains by aligning the moments of the distributions of attentively selected features to reduce their discrepancy. To ensure high discrimination, we propose a Feature Restoration (FR) operation to distill task-relevant features from the residual information and use them to compensate for the aligned features. For better disentanglement, we enforce a dual ranking entropy loss constraint in the FR step to encourage the separation of task-relevant and task-irrelevant features. Extensive experiments on multiple classification benchmarks demonstrate the high performance and strong generalization of our FAR framework for both domain generalization and unsupervised domain adaptation.
Rethinking Classification Loss Designs for Person Re-identification with a Unified View
Jun 08, 2020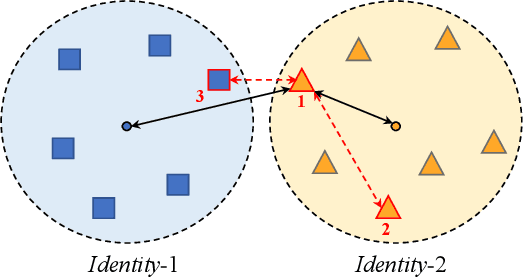

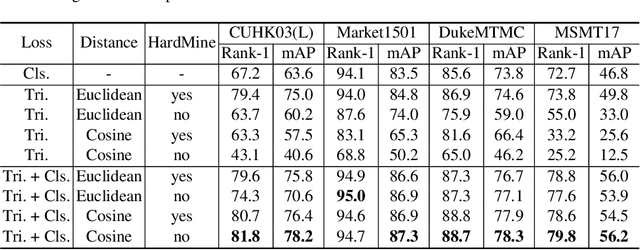
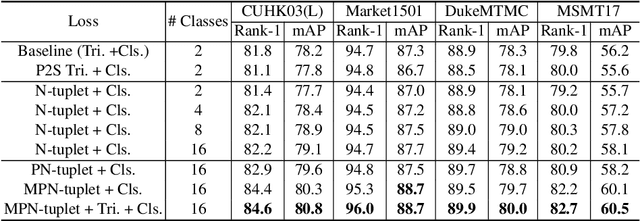
Person Re-identification (ReID) aims at matching a person of interest across images. In convolutional neural networks (CNNs) based approaches, loss design plays a role of metric learning which guides the feature learning process to pull closer features of the same identity and to push far apart features of different identities. In recent years, the combination of classification loss and triplet loss achieves superior performance and is predominant in ReID. In this paper, we rethink these loss functions within a generalized formulation and argue that triplet-based optimization can be viewed as a two-class subsampling classification, which performs classification over two sampled categories based on instance similarities. Furthermore, we present a case study which demonstrates that increasing the number of simultaneously considered instance classes significantly improves the ReID performance, since it is aligned better with the ReID test/inference process. With the multi-class subsampling classification incorporated, we provide a strong baseline which achieves the state-of-the-art performance on the benchmark person ReID datasets. Finally, we propose a new meta prototypical N-tuple loss for more efficient multi-class subsampling classification. We aim to inspire more new loss designs in the person ReID field.