 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENEIDE: A High Quality Silver Standard Dataset for Named Entity Recognition and Linking in Historical Italian
Mar 31, 2026This paper introduces ENEIDE (Extracting Named Entities from Italian Digital Editions), a silver standard dataset for Named Entity Recognition and Linking (NERL) in historical Italian texts. The corpus comprises 2,111 documents with over 8,000 entity annotations semi-automatically extracted from two scholarly digital editions: Digital Zibaldone, the philosophical diary of the Italian poet Giacomo Leopardi (1798--1837), and Aldo Moro Digitale, the complete works of the Italian politician Aldo Moro (1916--1978). Annotations cover multiple entity types (person, location, organization, literary work) linked to Wikidata identifiers, including NIL entities that cannot be mapped to the knowledge graph. To the best of our knowledge, ENEIDE represents the first multi-domain, publicly available NERL dataset for historical Italian with training, development, and test splits. We present a methodology for semi-automatic annotations extraction from manually curated scholarly digital editions, including quality control and annotation enhancement procedures. Baseline experiments using state-of-the-art models demonstrate the dataset's challenge for NERL and the gap between zero-shot approaches and fine-tuned models. The dataset's diachronic coverage spanning two centuries makes it particularly suitable for temporal entity disambiguation and cross-domain evaluation. ENEIDE is released under a CC BY-NC-SA 4.0 license.
It's All About the Confidence: An Unsupervised Approach for Multilingual Historical Entity Linking using Large Language Models
Jan 13, 2026Despite the recent advancements in NLP with the advent of Large Language Models (LLMs), Entity Linking (EL) for historical texts remains challenging due to linguistic variation, noisy inputs, and evolving semantic conventions. Existing solutions either require substantial training data or rely on domain-specific rules that limit scalability. In this paper, we present MHEL-LLaMo (Multilingual Historical Entity Linking with Large Language MOdels), an unsupervised ensemble approach combining a Small Language Model (SLM) and an LLM. MHEL-LLaMo leverages a multilingual bi-encoder (BELA) for candidate retrieval and an instruction-tuned LLM for NIL prediction and candidate selection via prompt chaining. Our system uses SLM's confidence scores to discriminate between easy and hard samples, applying an LLM only for hard cases. This strategy reduces computational costs while preventing hallucinations on straightforward cases. We evaluate MHEL-LLaMo on four established benchmarks in six European languages (English, Finnish, French, German, Italian and Swedish) from the 19th and 20th centuries. Results demonstrate that MHEL-LLaMo outperforms state-of-the-art models without requiring fine-tuning, offering a scalable solution for low-resource historical EL. The implementation of MHEL-LLaMo is available on Github.
DELICATE: Diachronic Entity LInking using Classes And Temporal Evidence
Nov 13, 2025



In spite of the remarkable advancements in the field of Natural Language Processing, the task of Entity Linking (EL) remains challenging in the field of humanities due to complex document typologies, lack of domain-specific datasets and models, and long-tail entities, i.e., entities under-represented in Knowledge Bases (KBs). The goal of this paper is to address these issues with two main contributions. The first contribution is DELICATE, a novel neuro-symbolic method for EL on historical Italian which combines a BERT-based encoder with contextual information from Wikidata to select appropriate KB entities using temporal plausibility and entity type consistency. The second contribution is ENEIDE, a multi-domain EL corpus in historical Italian semi-automatically extracted from two annotated editions spanning from the 19th to the 20th century and including literary and political texts. Results show how DELICATE outperforms other EL models in historical Italian even if compared with larger architectures with billions of parameters. Moreover, further analyses reveal how DELICATE confidence scores and features sensitivity provide results which are more explainable and interpretable than purely neural methods.
Named Entity Recognition in Historical Italian: The Case of Giacomo Leopardi's Zibaldone
May 26, 2025The increased digitization of world's textual heritage poses significant challenges for both computer science and literary studies. Overall, there is an urgent need of computational techniques able to adapt to the challenges of historical texts, such as orthographic and spelling variations, fragmentary structure and digitization errors. The rise of large language models (LLMs) has revolutionized natural language processing, suggesting promising applications for Named Entity Recognition (NER) on historical documents. In spite of this, no thorough evaluation has been proposed for Italian texts. This research tries to fill the gap by proposing a new challenging dataset for entity extraction based on a corpus of 19th century scholarly notes, i.e. Giacomo Leopardi's Zibaldone (1898), containing 2,899 references to people, locations and literary works. This dataset was used to carry out reproducible experiments with both domain-specific BERT-based models and state-of-the-art LLMs such as LLaMa3.1. Results show that instruction-tuned models encounter multiple difficulties handling historical humanistic texts, while fine-tuned NER models offer more robust performance even with challenging entity types such as bibliographic references.
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
Multimodal Search on Iconclass using Vision-Language Pre-Trained Models
Jun 23, 2023

Terminology sources, such as controlled vocabularies, thesauri and classification systems, play a key role in digitizing cultural heritage. However, Information Retrieval (IR) systems that allow to query and explore these lexical resources often lack an adequate representation of the semantics behind the user's search, which can be conveyed through multiple expression modalities (e.g., images, keywords or textual descriptions). This paper presents the implementation of a new search engine for one of the most widely used iconography classification system, Iconclass. The novelty of this system is the use of a pre-trained vision-language model, namely CLIP, to retrieve and explore Iconclass concepts using visual or textual queries.
A Knowledge Graph Embeddings based Approach for Author Name Disambiguation using Literals
Jan 24, 2022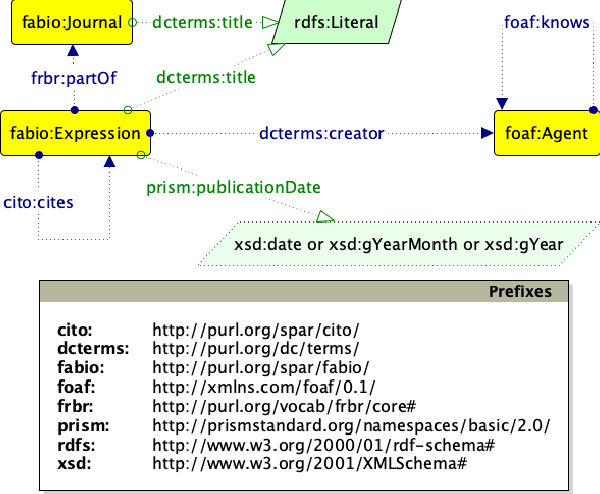

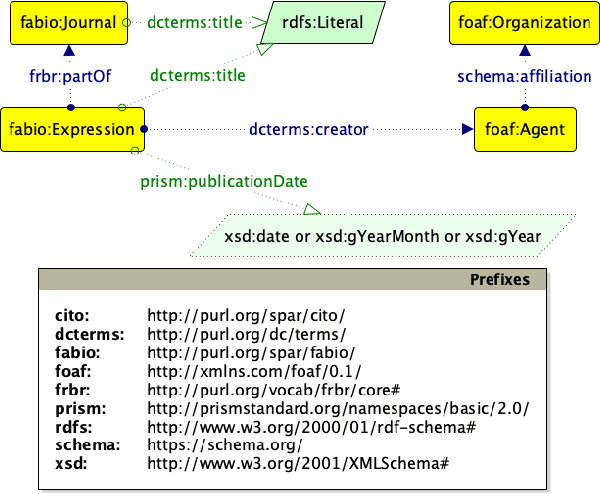

Scholarly data is growing continuously containing information about the articles from plethora of venues including conferences, journals, etc. Many initiatives have been taken to make scholarly data available in the for of Knowledge Graphs (KGs). These efforts to standardize these data and make them accessible have also lead to many challenges such as exploration of scholarly articles, ambiguous authors, etc. This study more specifically targets the problem of Author Name Disambiguation (AND) on Scholarly KGs and presents a novel framework, Literally Author Name Disambiguation (LAND), which utilizes Knowledge Graph Embeddings (KGEs) using multimodal literal information generated from these KGs. This framework is based on three components: 1) Multimodal KGEs, 2) A blocking procedure, and finally, 3) Hierarchical Agglomerative Clustering. Extensive experiments have been conducted on two newly created KGs: (i) KG containing information from Scientometrics Journal from 1978 onwards (OC-782K), and (ii) a KG extracted from a well-known benchmark for AND provided by AMiner (AMiner-534K). The results show that our proposed architecture outperforms our baselines of 8-14\% in terms of F$_1$ score and shows competitive performances on a challenging benchmark such as AMiner. The code and the datasets are publicly available through Github (https://github.com/sntcristian/and-kge) and Zenodo (https://zenodo.org/record/5675787\#.YcCJzL3MJTY) respectively.