 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent Removal as a Moderation Strategy: Compliance and Other Outcomes in the ChangeMyView Community
Oct 21, 2019

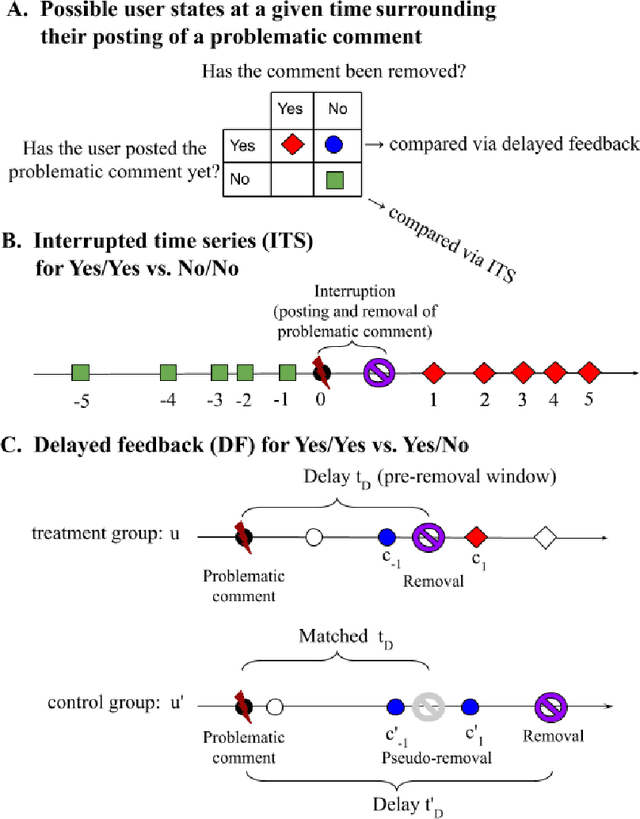
Moderators of online communities often employ comment deletion as a tool. We ask here whether, beyond the positive effects of shielding a community from undesirable content, does comment removal actually cause the behavior of the comment's author to improve? We examine this question in a particularly well-moderated community, the ChangeMyView subreddit. The standard analytic approach of interrupted time-series analysis unfortunately cannot answer this question of causality because it fails to distinguish the effect of having made a non-compliant comment from the effect of being subjected to moderator removal of that comment. We therefore leverage a "delayed feedback" approach based on the observation that some users may remain active between the time when they posted the non-compliant comment and the time when that comment is deleted. Applying this approach to such users, we reveal the causal role of comment deletion in reducing immediate noncompliance rates, although we do not find evidence of it having a causal role in inducing other behavior improvements. Our work thus empirically demonstrates both the promise and some potential limits of content removal as a positive moderation strategy, and points to future directions for identifying causal effects from observational data.
Trouble on the Horizon: Forecasting the Derailment of Online Conversations as they Develop
Sep 03, 2019
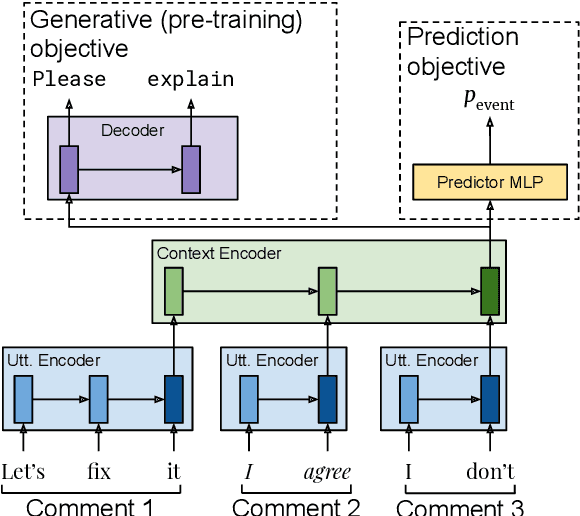
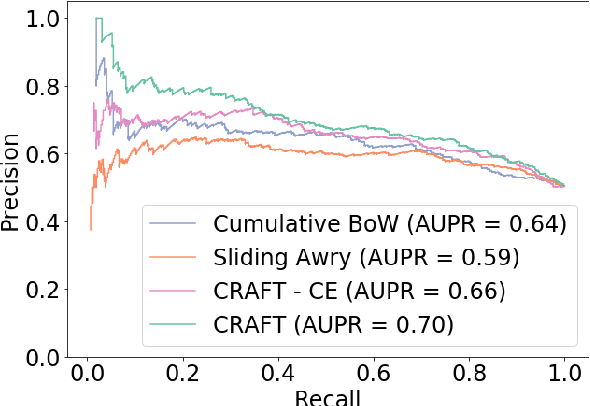
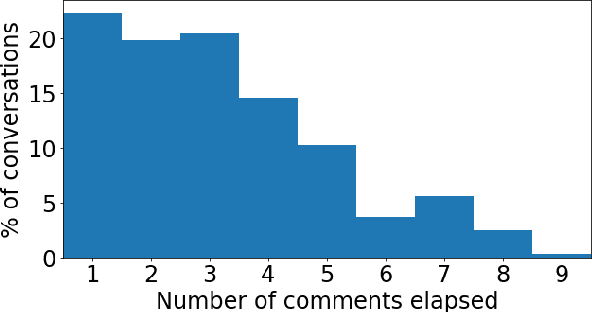
Online discussions often derail into toxic exchanges between participants. Recent efforts mostly focused on detecting antisocial behavior after the fact, by analyzing single comments in isolation. To provide more timely notice to human moderators, a system needs to preemptively detect that a conversation is heading towards derailment before it actually turns toxic. This means modeling derailment as an emerging property of a conversation rather than as an isolated utterance-level event. Forecasting emerging conversational properties, however, poses several inherent modeling challenges. First, since conversations are dynamic, a forecasting model needs to capture the flow of the discussion, rather than properties of individual comments. Second, real conversations have an unknown horizon: they can end or derail at any time; thus a practical forecasting model needs to assess the risk in an online fashion, as the conversation develops. In this work we introduce a conversational forecasting model that learns an unsupervised representation of conversational dynamics and exploits it to predict future derailment as the conversation develops. By applying this model to two new diverse datasets of online conversations with labels for antisocial events, we show that it outperforms state-of-the-art systems at forecasting derailment.
Finding Your Voice: The Linguistic Development of Mental Health Counselors
Jun 17, 2019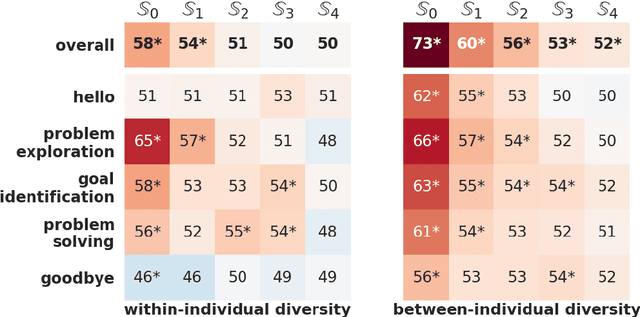
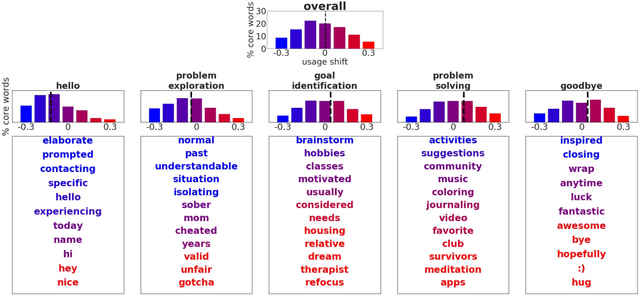
Mental health counseling is an enterprise with profound societal importance where conversations play a primary role. In order to acquire the conversational skills needed to face a challenging range of situations, mental health counselors must rely on training and on continued experience with actual clients. However, in the absence of large scale longitudinal studies, the nature and significance of this developmental process remain unclear. For example, prior literature suggests that experience might not translate into consequential changes in counselor behavior. This has led some to even argue that counseling is a profession without expertise. In this work, we develop a computational framework to quantify the extent to which individuals change their linguistic behavior with experience and to study the nature of this evolution. We use our framework to conduct a large longitudinal study of mental health counseling conversations, tracking over 3,400 counselors across their tenure. We reveal that overall, counselors do indeed change their conversational behavior to become more diverse across interactions, developing an individual voice that distinguishes them from other counselors. Furthermore, a finer-grained investigation shows that the rate and nature of this diversification vary across functionally different conversational components.
Asking the Right Question: Inferring Advice-Seeking Intentions from Personal Narratives
Apr 02, 2019
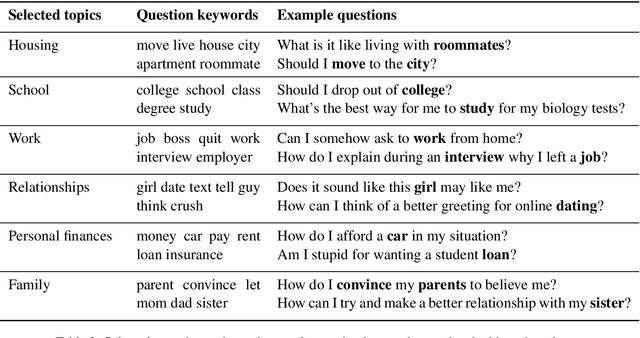

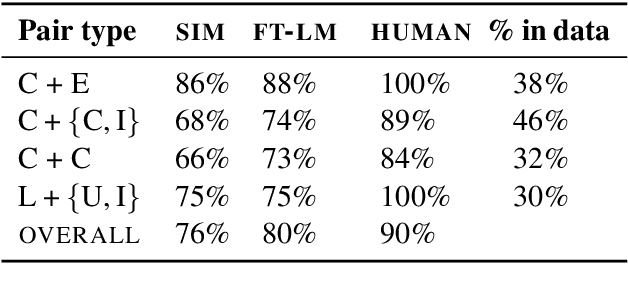
People often share personal narratives in order to seek advice from others. To properly infer the narrator's intention, one needs to apply a certain degree of common sense and social intuition. To test the capabilities of NLP systems to recover such intuition, we introduce the new task of inferring what is the advice-seeking goal behind a personal narrative. We formulate this as a cloze test, where the goal is to identify which of two advice-seeking questions was removed from a given narrative. The main challenge in constructing this task is finding pairs of semantically plausible advice-seeking questions for given narratives. To address this challenge, we devise a method that exploits commonalities in experiences people share online to automatically extract pairs of questions that are appropriate candidates for the cloze task. This results in a dataset of over 20,000 personal narratives, each matched with a pair of related advice-seeking questions: one actually intended by the narrator, and the other one not. The dataset covers a very broad array of human experiences, from dating, to career options, to stolen iPads. We use human annotation to determine the degree to which the task relies on common sense and social intuition in addition to a semantic understanding of the narrative. By introducing several baselines for this new task we demonstrate its feasibility and identify avenues for better modeling the intention of the narrator.
Trajectories of Blocked Community Members: Redemption, Recidivism and Departure
Feb 22, 2019
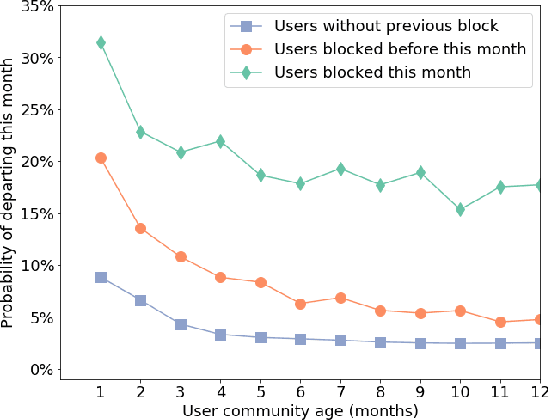
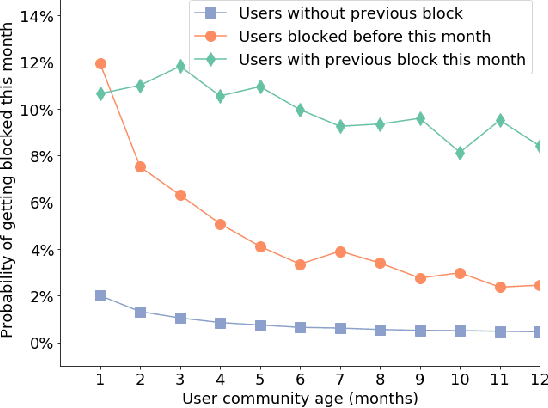
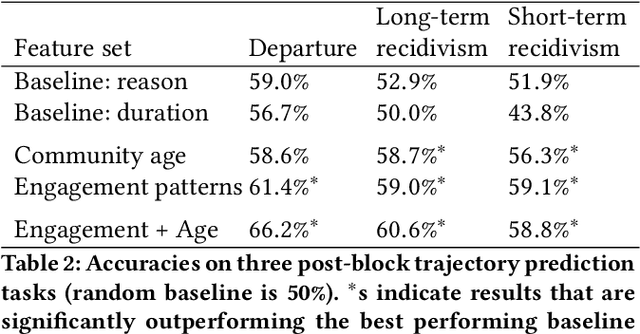
Community norm violations can impair constructive communication and collaboration online. As a defense mechanism, community moderators often address such transgressions by temporarily blocking the perpetrator. Such actions, however, come with the cost of potentially alienating community members. Given this tradeoff, it is essential to understand to what extent, and in which situations, this common moderation practice is effective in reinforcing community rules. In this work, we introduce a computational framework for studying the future behavior of blocked users on Wikipedia. After their block expires, they can take several distinct paths: they can reform and adhere to the rules, but they can also recidivate, or straight-out abandon the community. We reveal that these trajectories are tied to factors rooted both in the characteristics of the blocked individual and in whether they perceived the block to be fair and justified. Based on these insights, we formulate a series of prediction tasks aiming to determine which of these paths a user is likely to take after being blocked for their first offense, and demonstrate the feasibility of these new tasks. Overall, this work builds towards a more nuanced approach to moderation by highlighting the tradeoffs that are in play.
WikiConv: A Corpus of the Complete Conversational History of a Large Online Collaborative Community
Oct 31, 2018
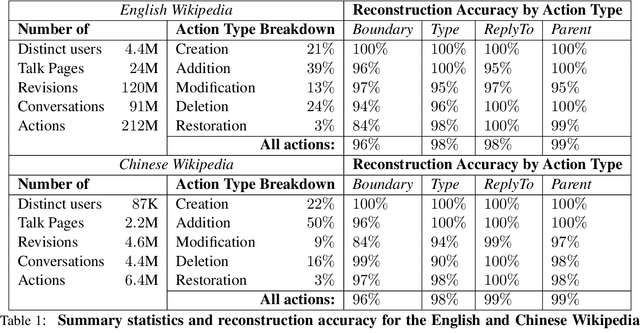

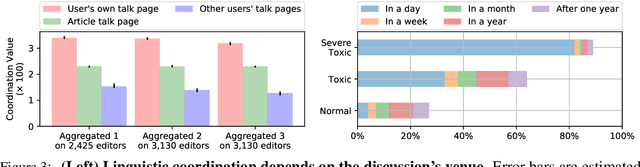
We present a corpus that encompasses the complete history of conversations between contributors to Wikipedia, one of the largest online collaborative communities. By recording the intermediate states of conversations---including not only comments and replies, but also their modifications, deletions and restorations---this data offers an unprecedented view of online conversation. This level of detail supports new research questions pertaining to the process (and challenges) of large-scale online collaboration. We illustrate the corpus' potential with two case studies that highlight new perspectives on earlier work. First, we explore how a person's conversational behavior depends on how they relate to the discussion's venue. Second, we show that community moderation of toxic behavior happens at a higher rate than previously estimated. Finally the reconstruction framework is designed to be language agnostic, and we show that it can extract high quality conversational data in both Chinese and English.
Conversations Gone Awry: Detecting Early Signs of Conversational Failure
May 14, 2018

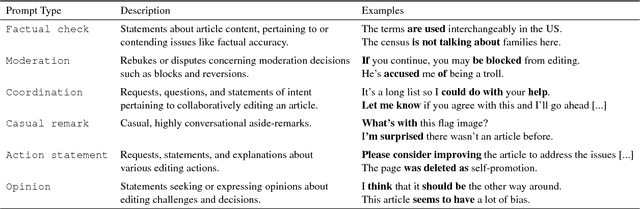
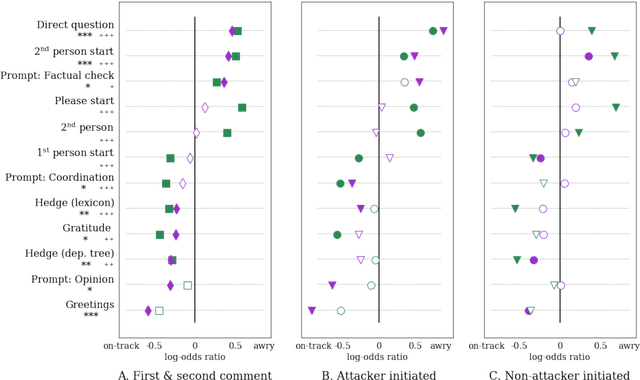
One of the main challenges online social systems face is the prevalence of antisocial behavior, such as harassment and personal attacks. In this work, we introduce the task of predicting from the very start of a conversation whether it will get out of hand. As opposed to detecting undesirable behavior after the fact, this task aims to enable early, actionable prediction at a time when the conversation might still be salvaged. To this end, we develop a framework for capturing pragmatic devices---such as politeness strategies and rhetorical prompts---used to start a conversation, and analyze their relation to its future trajectory. Applying this framework in a controlled setting, we demonstrate the feasibility of detecting early warning signs of antisocial behavior in online discussions.
Asking Too Much? The Rhetorical Role of Questions in Political Discourse
Aug 07, 2017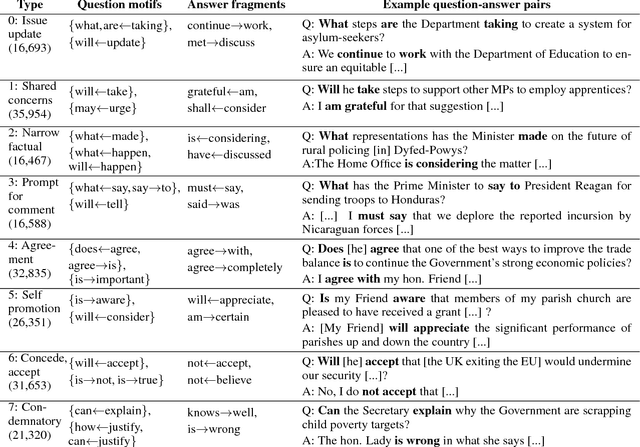
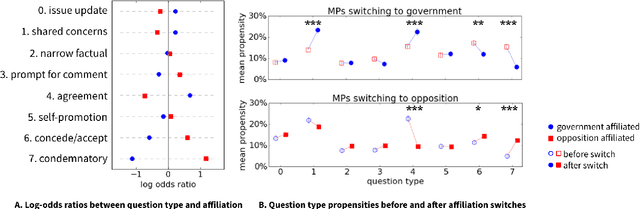
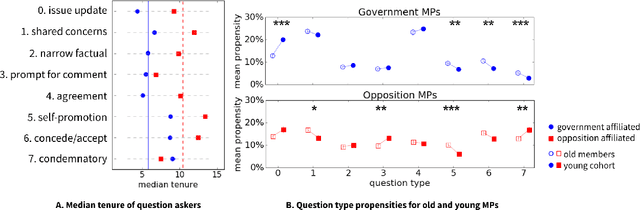

Questions play a prominent role in social interactions, performing rhetorical functions that go beyond that of simple informational exchange. The surface form of a question can signal the intention and background of the person asking it, as well as the nature of their relation with the interlocutor. While the informational nature of questions has been extensively examined in the context of question-answering applications, their rhetorical aspects have been largely understudied. In this work we introduce an unsupervised methodology for extracting surface motifs that recur in questions, and for grouping them according to their latent rhetorical role. By applying this framework to the setting of question sessions in the UK parliament, we show that the resulting typology encodes key aspects of the political discourse---such as the bifurcation in questioning behavior between government and opposition parties---and reveals new insights into the effects of a legislator's tenure and political career ambitions.
Community Identity and User Engagement in a Multi-Community Landscape
May 26, 2017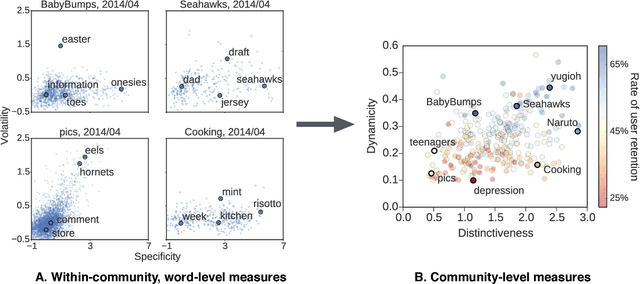


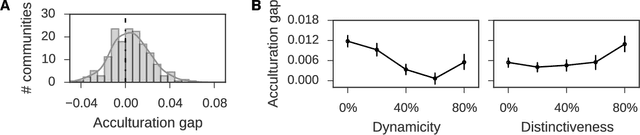
A community's identity defines and shapes its internal dynamics. Our current understanding of this interplay is mostly limited to glimpses gathered from isolated studies of individual communities. In this work we provide a systematic exploration of the nature of this relation across a wide variety of online communities. To this end we introduce a quantitative, language-based typology reflecting two key aspects of a community's identity: how distinctive, and how temporally dynamic it is. By mapping almost 300 Reddit communities into the landscape induced by this typology, we reveal regularities in how patterns of user engagement vary with the characteristics of a community. Our results suggest that the way new and existing users engage with a community depends strongly and systematically on the nature of the collective identity it fosters, in ways that are highly consequential to community maintainers. For example, communities with distinctive and highly dynamic identities are more likely to retain their users. However, such niche communities also exhibit much larger acculturation gaps between existing users and newcomers, which potentially hinder the integration of the latter. More generally, our methodology reveals differences in how various social phenomena manifest across communities, and shows that structuring the multi-community landscape can lead to a better understanding of the systematic nature of this diversity.
Loyalty in Online Communities
May 24, 2017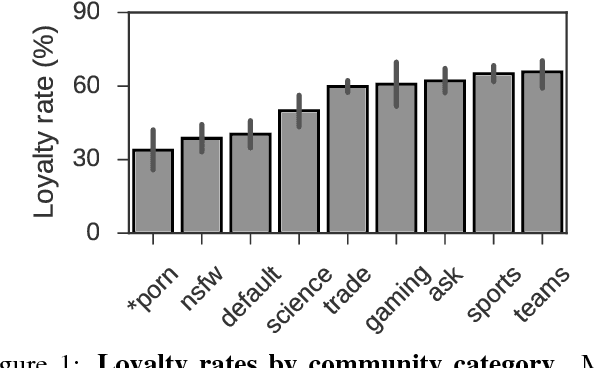
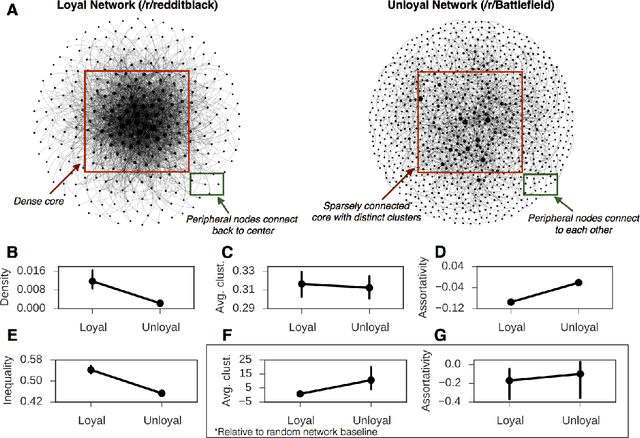
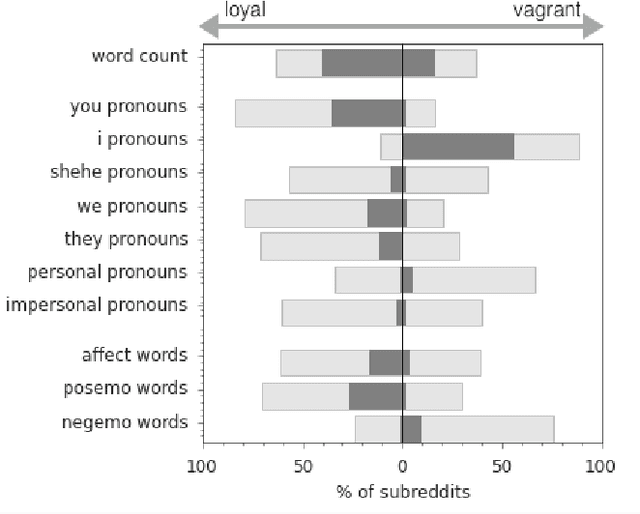
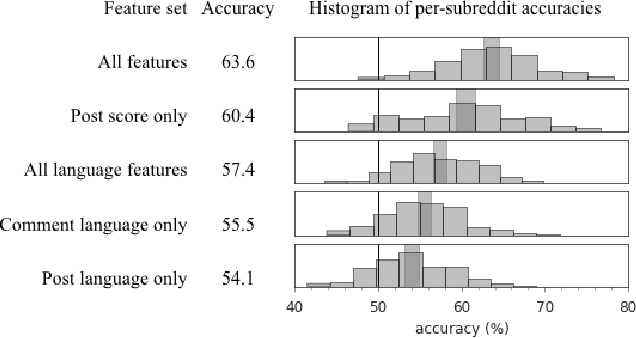
Loyalty is an essential component of multi-community engagement. When users have the choice to engage with a variety of different communities, they often become loyal to just one, focusing on that community at the expense of others. However, it is unclear how loyalty is manifested in user behavior, or whether loyalty is encouraged by certain community characteristics. In this paper we operationalize loyalty as a user-community relation: users loyal to a community consistently prefer it over all others; loyal communities retain their loyal users over time. By exploring this relation using a large dataset of discussion communities from Reddit, we reveal that loyalty is manifested in remarkably consistent behaviors across a wide spectrum of communities. Loyal users employ language that signals collective identity and engage with more esoteric, less popular content, indicating they may play a curational role in surfacing new material. Loyal communities have denser user-user interaction networks and lower rates of triadic closure, suggesting that community-level loyalty is associated with more cohesive interactions and less fragmentation into subgroups. We exploit these general patterns to predict future rates of loyalty. Our results show that a user's propensity to become loyal is apparent from their first interactions with a community, suggesting that some users are intrinsically loyal from the very beginning.