 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
SPT-NRTL: A physics-guided machine learning model to predict thermodynamically consistent activity coefficients
Sep 09, 2022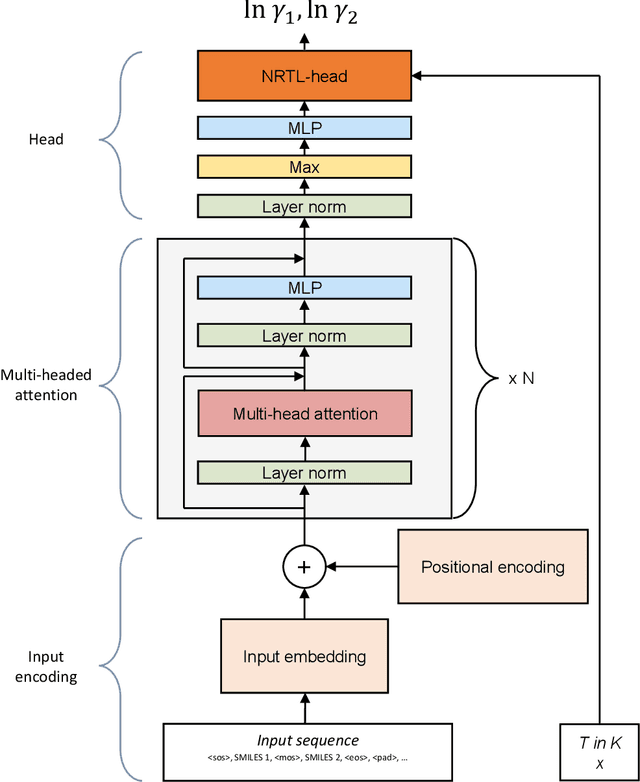
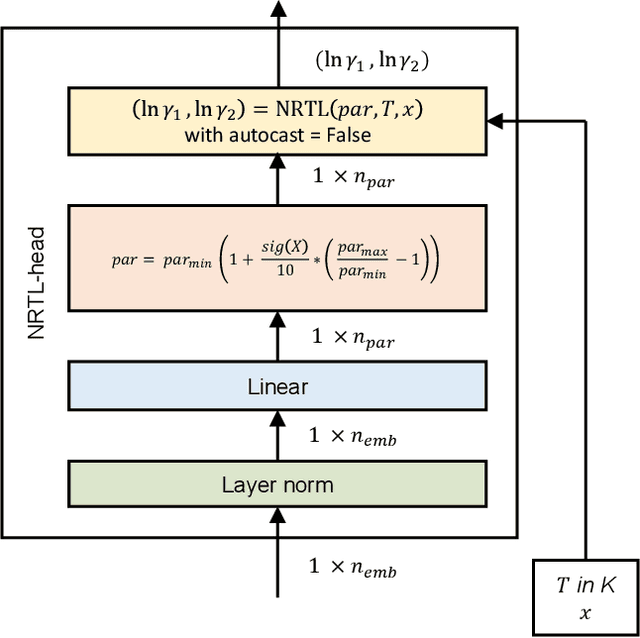
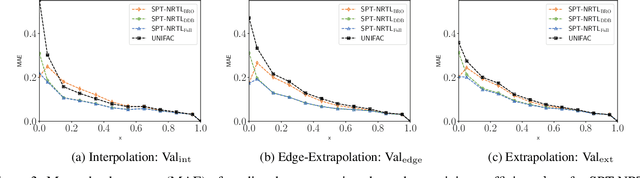
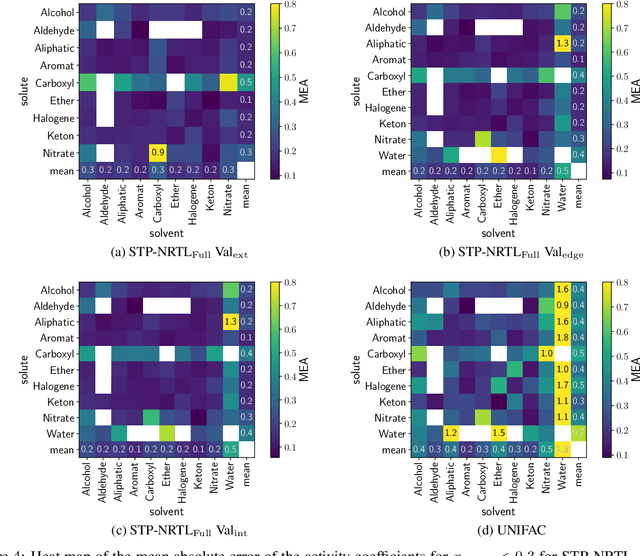
The availability of property data is one of the major bottlenecks in the development of chemical processes, often requiring time-consuming and expensive experiments or limiting the design space to a small number of known molecules. This bottleneck has been the motivation behind the continuing development of predictive property models. For the property prediction of novel molecules, group contribution methods have been groundbreaking. In recent times, machine learning has joined the more established property prediction models. However, even with recent successes, the integration of physical constraints into machine learning models remains challenging. Physical constraints are vital to many thermodynamic properties, such as the Gibbs-Dunham relation, introducing an additional layer of complexity into the prediction. Here, we introduce SPT-NRTL, a machine learning model to predict thermodynamically consistent activity coefficients and provide NRTL parameters for easy use in process simulations. The results show that SPT-NRTL achieves higher accuracy than UNIFAC in the prediction of activity coefficients across all functional groups and is able to predict many vapor-liquid-equilibria with near experimental accuracy, as illustrated for the exemplary mixtures water/ethanol and chloroform/n-hexane. To ease the application of SPT-NRTL, NRTL-parameters of 100 000 000 mixtures are calculated with SPT-NRTL and provided online.
A smile is all you need: Predicting limiting activity coefficients from SMILES with natural language processing
Jun 15, 2022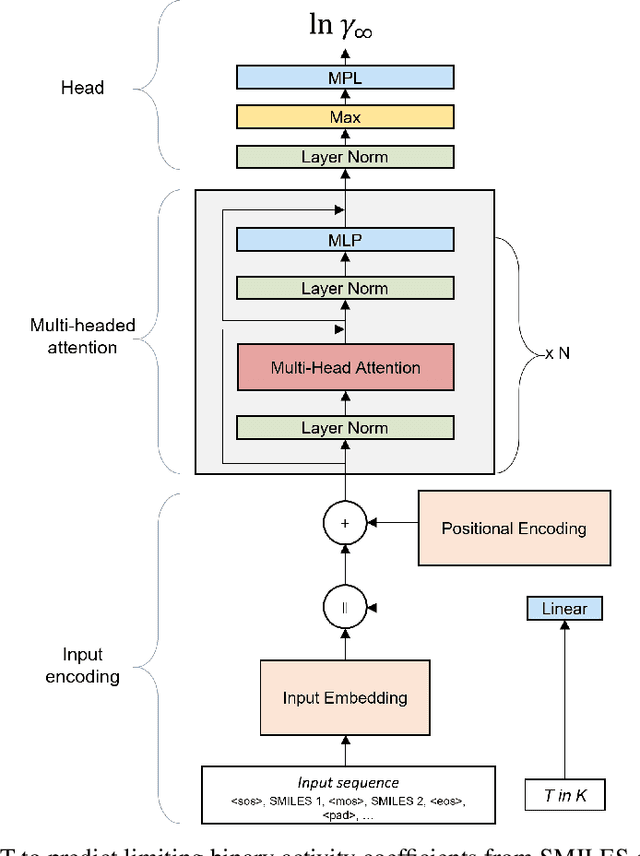
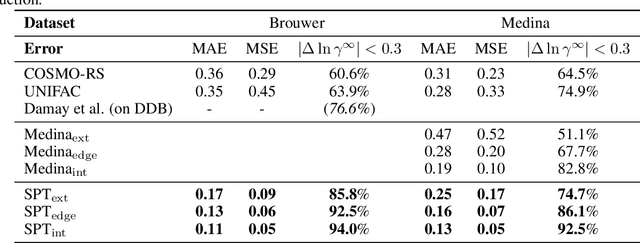
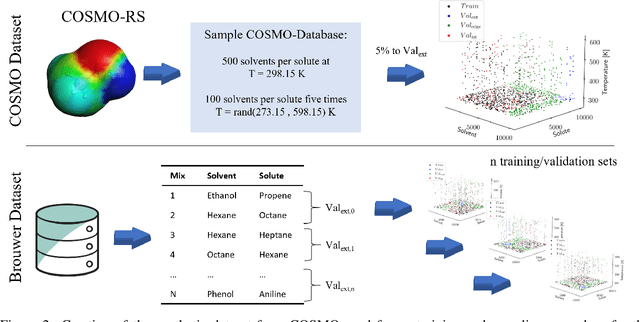
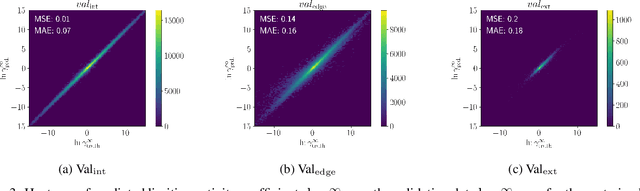
Knowledge of mixtures' phase equilibria is crucial in nature and technical chemistry. Phase equilibria calculations of mixtures require activity coefficients. However, experimental data on activity coefficients is often limited due to high cost of experiments. For an accurate and efficient prediction of activity coefficients, machine learning approaches have been recently developed. However, current machine learning approaches still extrapolate poorly for activity coefficients of unknown molecules. In this work, we introduce the SMILES-to-Properties-Transformer (SPT), a natural language processing network to predict binary limiting activity coefficients from SMILES codes. To overcome the limitations of available experimental data, we initially train our network on a large dataset of synthetic data sampled from COSMO-RS (10 Million data points) and then fine-tune the model on experimental data (20 870 data points). This training strategy enables SPT to accurately predict limiting activity coefficients even for unknown molecules, cutting the mean prediction error in half compared to state-of-the-art models for activity coefficient predictions such as COSMO-RS, UNIFAC, and improving on recent machine learning approaches.
Evaluating Large Language Models Trained on Code
Jul 14, 2021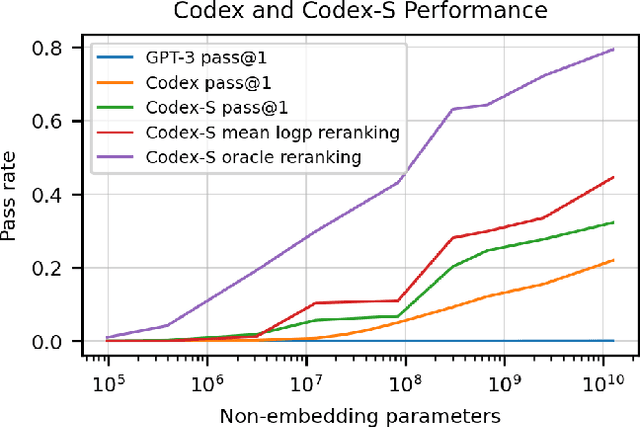
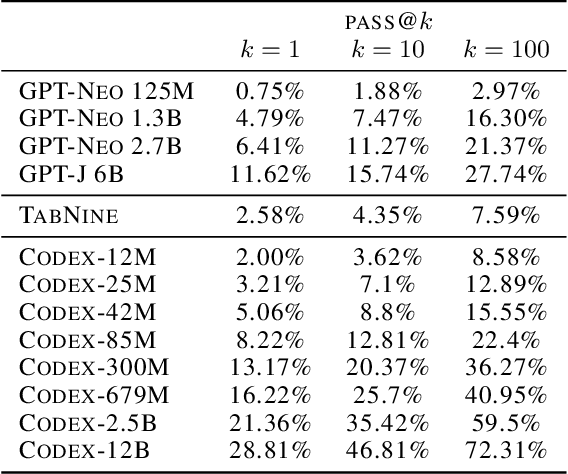
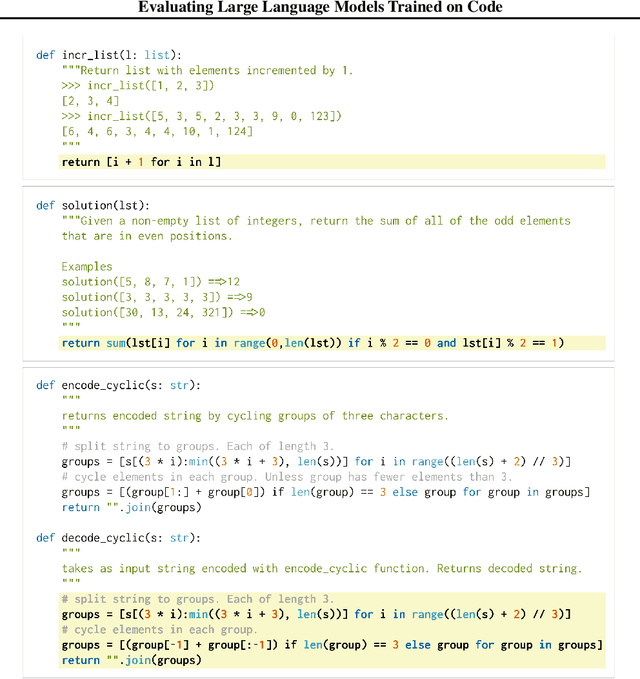
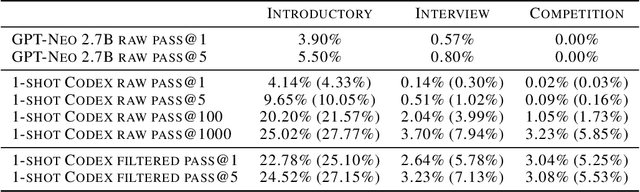
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
A Generalizable Approach to Learning Optimizers
Jun 07, 2021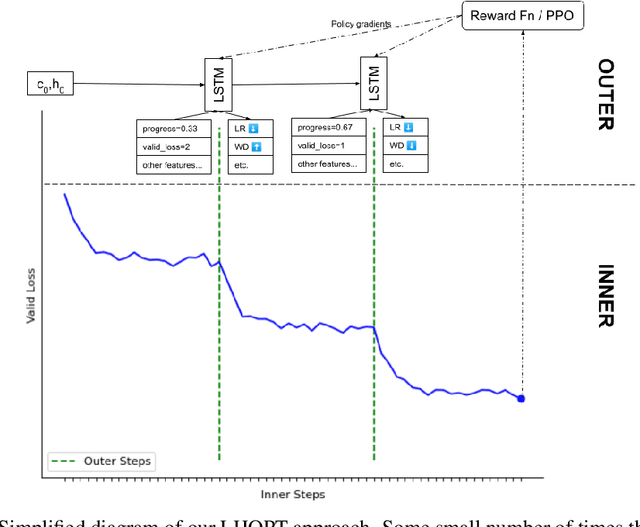
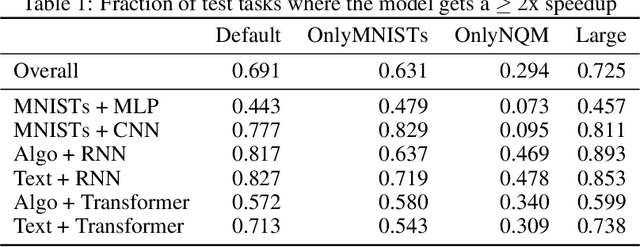
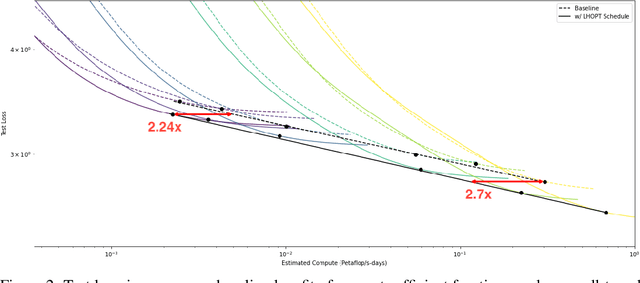
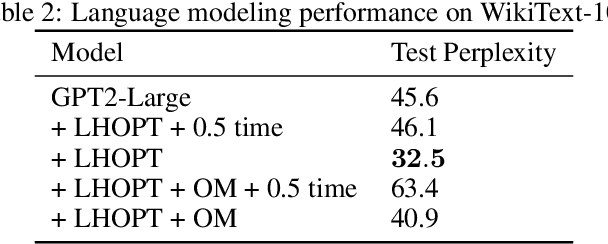
A core issue with learning to optimize neural networks has been the lack of generalization to real world problems. To address this, we describe a system designed from a generalization-first perspective, learning to update optimizer hyperparameters instead of model parameters directly using novel features, actions, and a reward function. This system outperforms Adam at all neural network tasks including on modalities not seen during training. We achieve 2x speedups on ImageNet, and a 2.5x speedup on a language modeling task using over 5 orders of magnitude more compute than the training tasks.
Language Models are Few-Shot Learners
Jun 05, 2020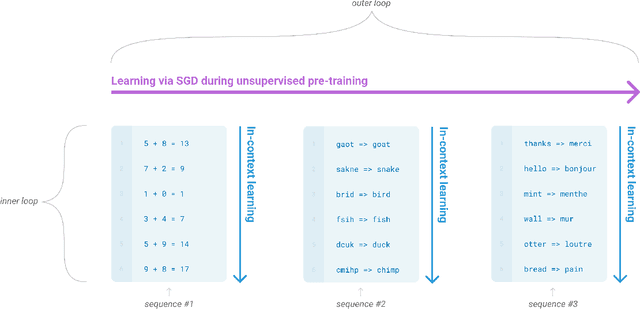
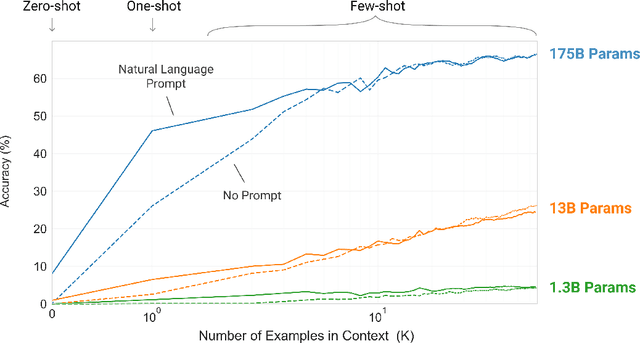
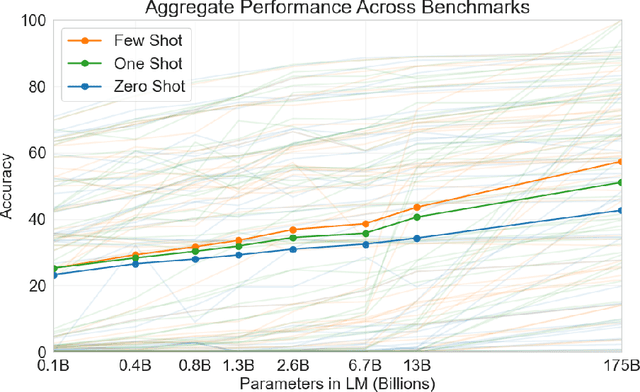
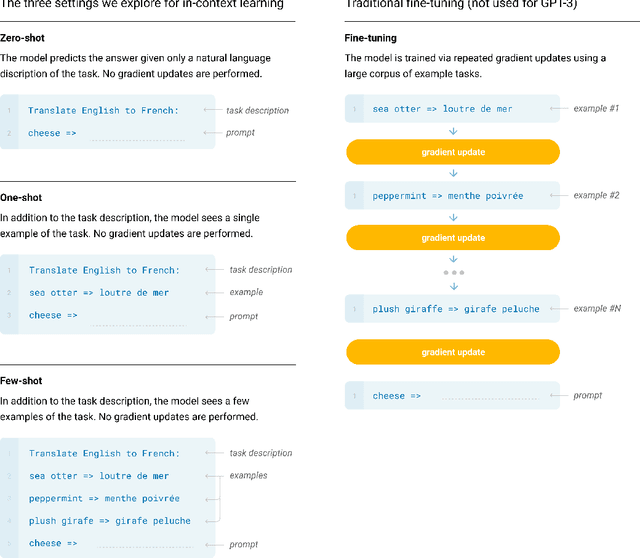
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions - something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.