 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterminantal Beam Search
Jun 21, 2021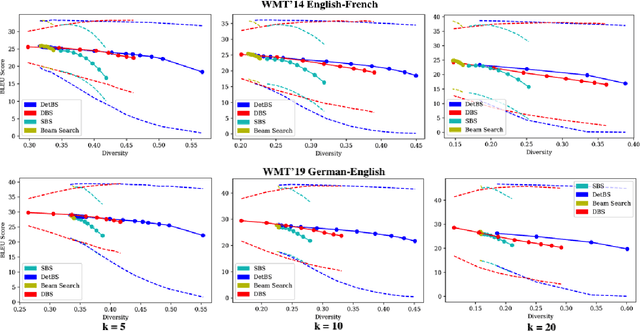


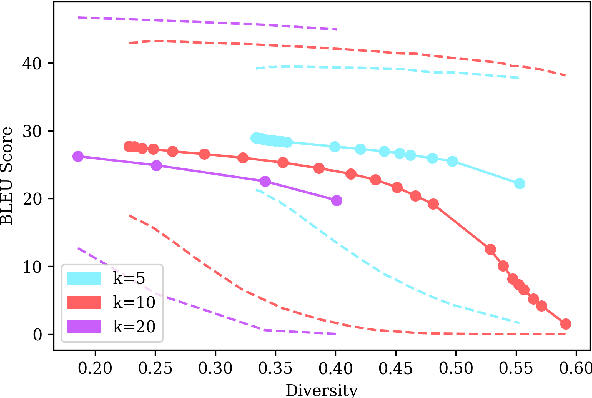
Beam search is a go-to strategy for decoding neural sequence models. The algorithm can naturally be viewed as a subset optimization problem, albeit one where the corresponding set function does not reflect interactions between candidates. Empirically, this leads to sets often exhibiting high overlap, e.g., strings may differ by only a single word. Yet in use-cases that call for multiple solutions, a diverse or representative set is often desired. To address this issue, we propose a reformulation of beam search, which we call determinantal beam search. Determinantal beam search has a natural relationship to determinantal point processes (DPPs), models over sets that inherently encode intra-set interactions. By posing iterations in beam search as a series of subdeterminant maximization problems, we can turn the algorithm into a diverse subset selection process. In a case study, we use the string subsequence kernel to explicitly encourage n-gram coverage in text generated from a sequence model. We observe that our algorithm offers competitive performance against other diverse set generation strategies in the context of language generation, while providing a more general approach to optimizing for diversity.
A Cognitive Regularizer for Language Modeling
Jun 10, 2021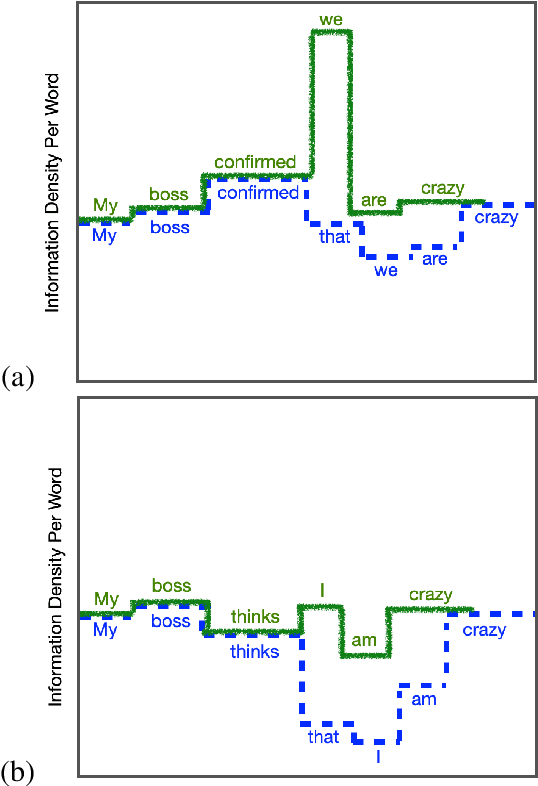
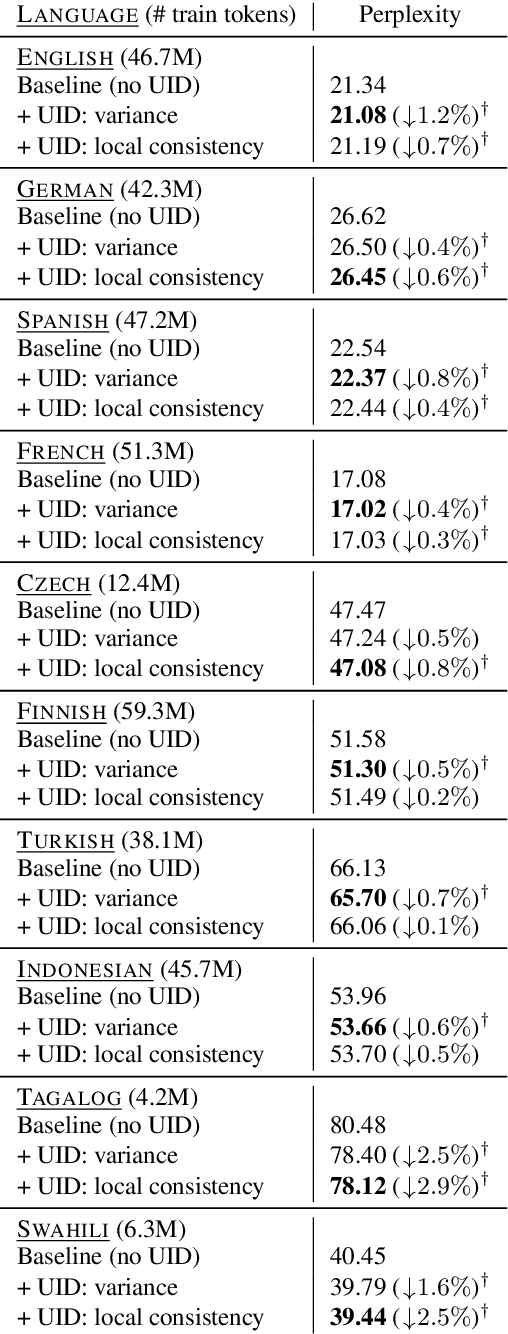
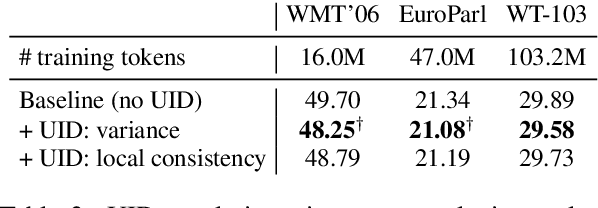
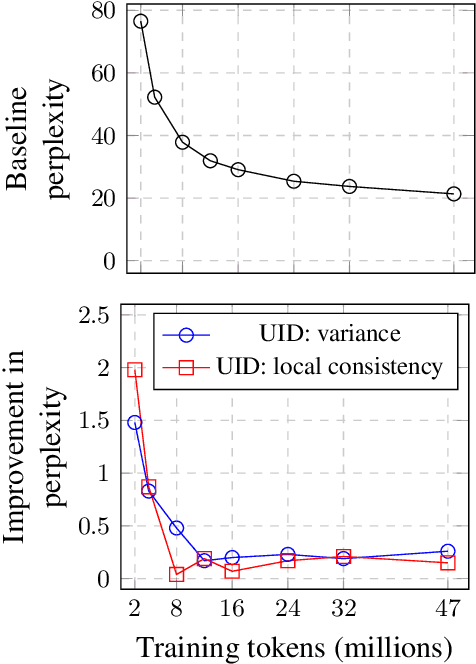
The uniform information density (UID) hypothesis, which posits that speakers behaving optimally tend to distribute information uniformly across a linguistic signal, has gained traction in psycholinguistics as an explanation for certain syntactic, morphological, and prosodic choices. In this work, we explore whether the UID hypothesis can be operationalized as an inductive bias for statistical language modeling. Specifically, we augment the canonical MLE objective for training language models with a regularizer that encodes UID. In experiments on ten languages spanning five language families, we find that using UID regularization consistently improves perplexity in language models, having a larger effect when training data is limited. Moreover, via an analysis of generated sequences, we find that UID-regularized language models have other desirable properties, e.g., they generate text that is more lexically diverse. Our results not only suggest that UID is a reasonable inductive bias for language modeling, but also provide an alternative validation of the UID hypothesis using modern-day NLP tools.
Is Sparse Attention more Interpretable?
Jun 08, 2021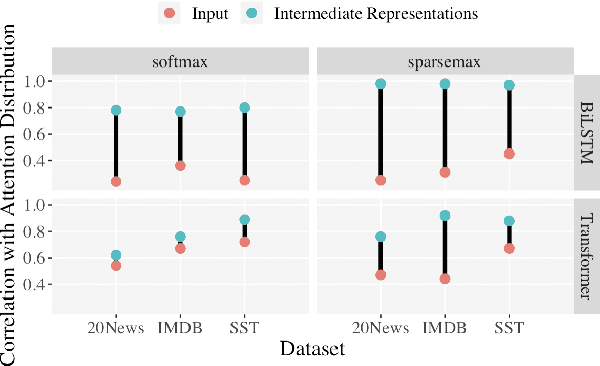
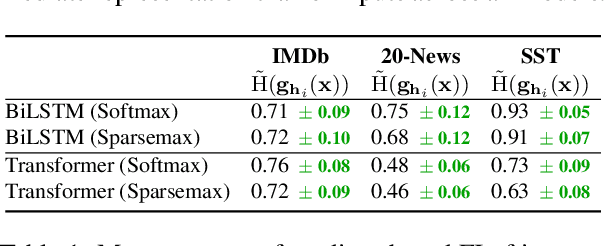
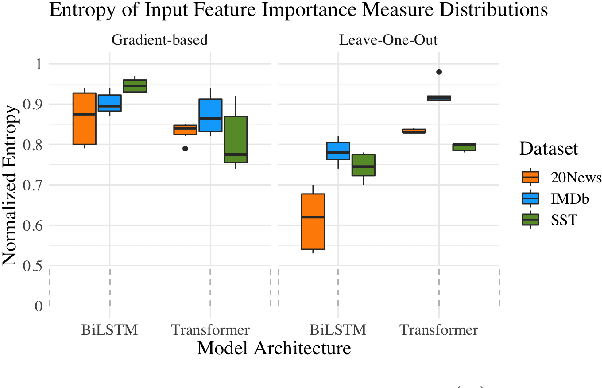
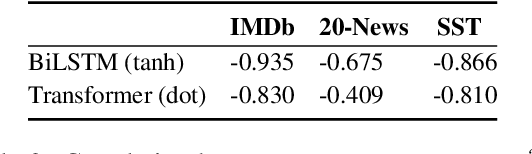
Sparse attention has been claimed to increase model interpretability under the assumption that it highlights influential inputs. Yet the attention distribution is typically over representations internal to the model rather than the inputs themselves, suggesting this assumption may not have merit. We build on the recent work exploring the interpretability of attention; we design a set of experiments to help us understand how sparsity affects our ability to use attention as an explainability tool. On three text classification tasks, we verify that only a weak relationship between inputs and co-indexed intermediate representations exists -- under sparse attention and otherwise. Further, we do not find any plausible mappings from sparse attention distributions to a sparse set of influential inputs through other avenues. Rather, we observe in this setting that inducing sparsity may make it less plausible that attention can be used as a tool for understanding model behavior.
* ACL 2021
Language Model Evaluation Beyond Perplexity
Jun 02, 2021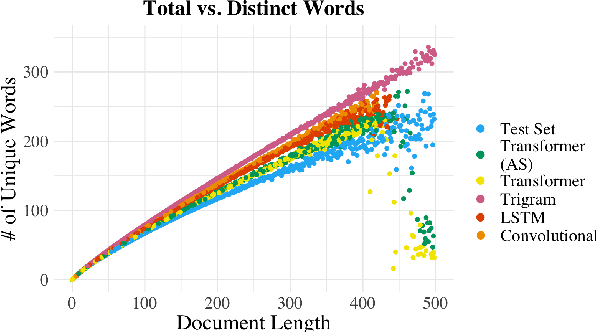
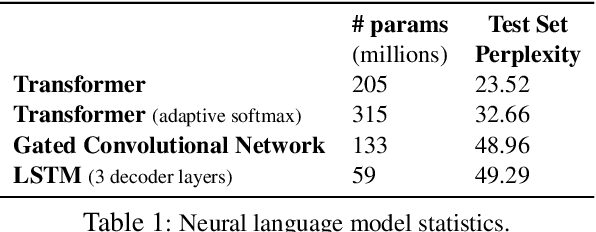
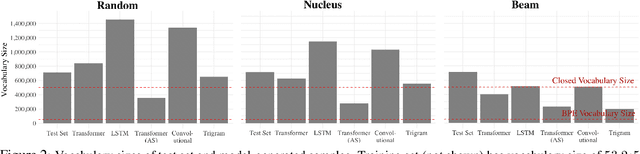
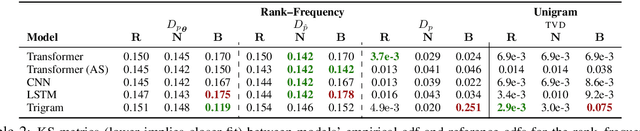
We propose an alternate approach to quantifying how well language models learn natural language: we ask how well they match the statistical tendencies of natural language. To answer this question, we analyze whether text generated from language models exhibits the statistical tendencies present in the human-generated text on which they were trained. We provide a framework--paired with significance tests--for evaluating the fit of language models to these trends. We find that neural language models appear to learn only a subset of the tendencies considered, but align much more closely with empirical trends than proposed theoretical distributions (when present). Further, the fit to different distributions is highly-dependent on both model architecture and generation strategy. As concrete examples, text generated under the nucleus sampling scheme adheres more closely to the type--token relationship of natural language than text produced using standard ancestral sampling; text from LSTMs reflects the natural language distributions over length, stopwords, and symbols surprisingly well.
Searching for Search Errors in Neural Morphological Inflection
Feb 16, 2021
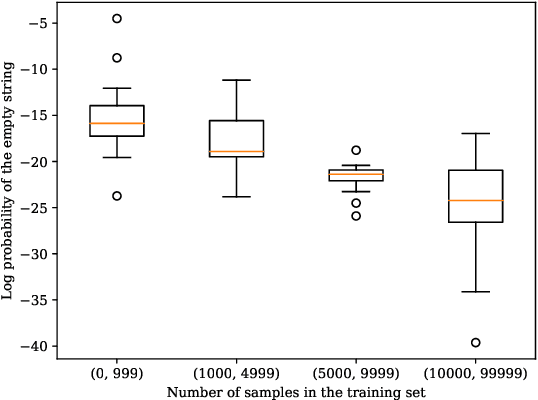

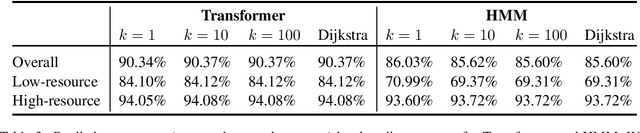
Neural sequence-to-sequence models are currently the predominant choice for language generation tasks. Yet, on word-level tasks, exact inference of these models reveals the empty string is often the global optimum. Prior works have speculated this phenomenon is a result of the inadequacy of neural models for language generation. However, in the case of morphological inflection, we find that the empty string is almost never the most probable solution under the model. Further, greedy search often finds the global optimum. These observations suggest that the poor calibration of many neural models may stem from characteristics of a specific subset of tasks rather than general ill-suitedness of such models for language generation.
If beam search is the answer, what was the question?
Oct 06, 2020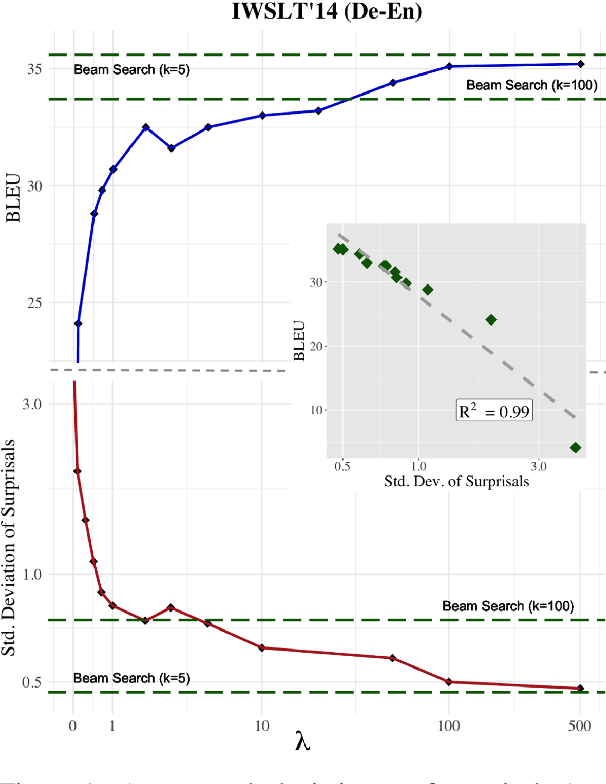
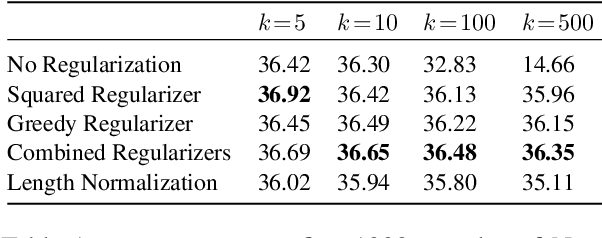
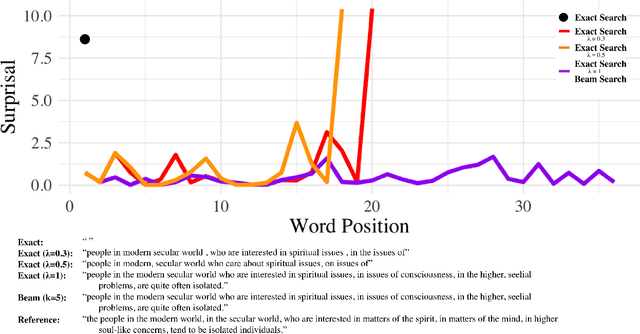

Quite surprisingly, exact maximum a posteriori (MAP) decoding of neural language generators frequently leads to low-quality results. Rather, most state-of-the-art results on language generation tasks are attained using beam search despite its overwhelmingly high search error rate. This implies that the MAP objective alone does not express the properties we desire in text, which merits the question: if beam search is the answer, what was the question? We frame beam search as the exact solution to a different decoding objective in order to gain insights into why high probability under a model alone may not indicate adequacy. We find that beam search enforces uniform information density in text, a property motivated by cognitive science. We suggest a set of decoding objectives that explicitly enforce this property and find that exact decoding with these objectives alleviates the problems encountered when decoding poorly calibrated language generation models. Additionally, we analyze the text produced using various decoding strategies and see that, in our neural machine translation experiments, the extent to which this property is adhered to strongly correlates with BLEU.
Best-First Beam Search
Jul 09, 2020
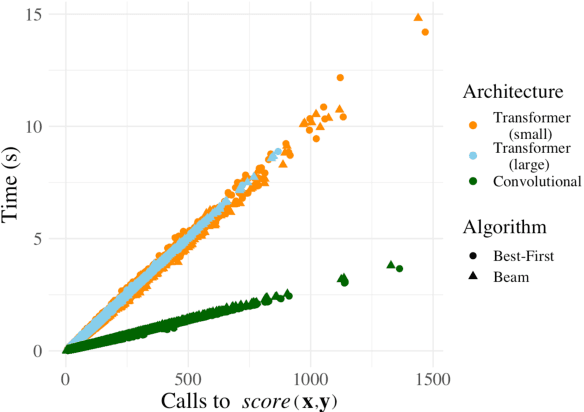

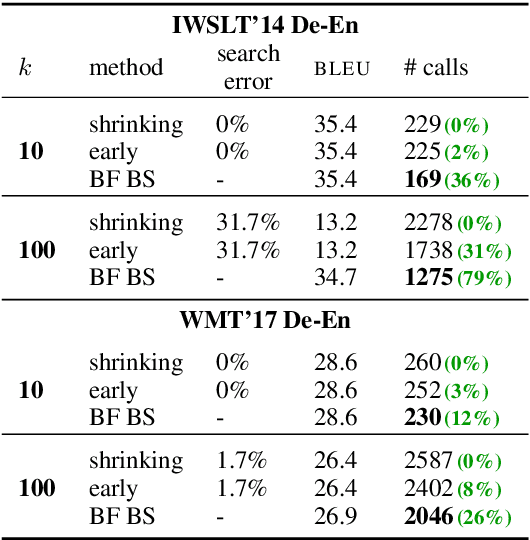
Decoding for many NLP tasks requires a heuristic algorithm for approximating exact search since the full search space is often intractable if not simply too large to traverse efficiently. The default algorithm for this job is beam search--a pruned version of breadth-first search--which in practice, returns better results than exact inference due to beneficial search bias. In this work, we show that standard beam search is a computationally inefficient choice for many decoding tasks; specifically, when the scoring function is a monotonic function in sequence length, other search algorithms can be used to reduce the number of calls to the scoring function (e.g., a neural network), which is often the bottleneck computation. We propose best-first beam search, an algorithm that provably returns the same set of results as standard beam search, albeit in the minimum number of scoring function calls to guarantee optimality (modulo beam size). We show that best-first beam search can be used with length normalization and mutual information decoding, among other rescoring functions. Lastly, we propose a memory-reduced variant of best-first beam search, which has a similar search bias in terms of downstream performance, but runs in a fraction of the time.
Generalized Entropy Regularization or: There's Nothing Special about Label Smoothing
May 12, 2020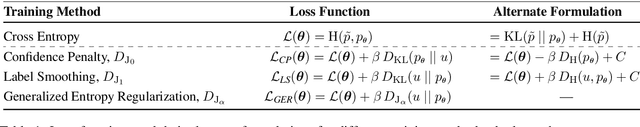
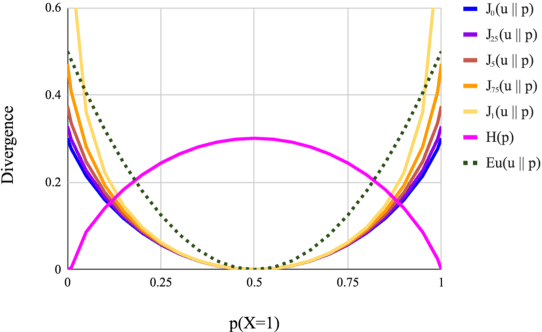
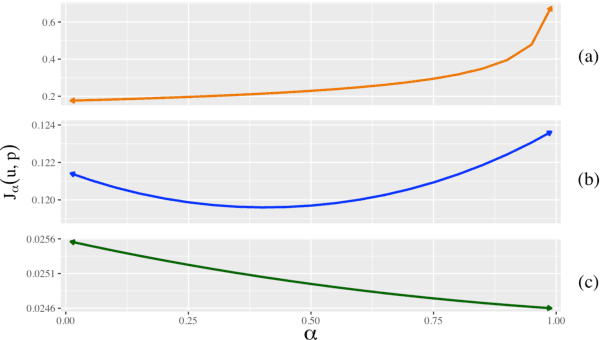
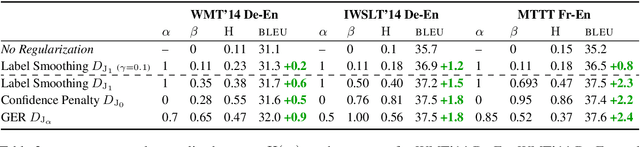
Prior work has explored directly regularizing the output distributions of probabilistic models to alleviate peaky (i.e. over-confident) predictions, a common sign of overfitting. This class of techniques, of which label smoothing is one, has a connection to entropy regularization. Despite the consistent success of label smoothing across architectures and data sets in language generation tasks, two problems remain open: (1) there is little understanding of the underlying effects entropy regularizers have on models, and (2) the full space of entropy regularization techniques is largely unexplored. We introduce a parametric family of entropy regularizers, which includes label smoothing as a special case, and use it to gain a better understanding of the relationship between the entropy of a model and its performance on language generation tasks. We also find that variance in model performance can be explained largely by the resulting entropy of the model. Lastly, we find that label smoothing provably does not allow for sparsity in an output distribution, an undesirable property for language generation models, and therefore advise the use of other entropy regularization methods in its place.
Testing Machine Translation via Referential Transparency
Apr 22, 2020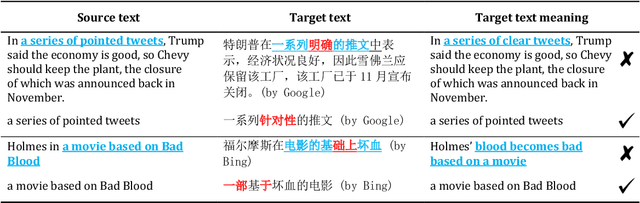
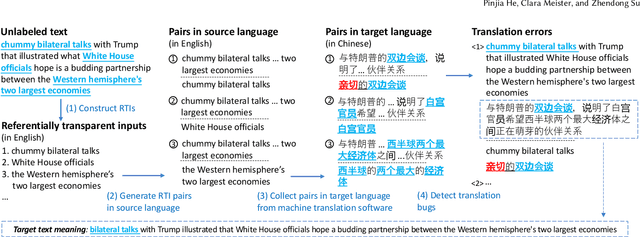

Machine translation software has seen rapid progress in recent years due to the advancement of deep neural networks. People routinely use machine translation software in their daily lives, such as ordering food in a foreign restaurant, receiving medical diagnosis and treatment from foreign doctors, and reading international political news online. However, due to the complexity and intractability of the underlying neural networks, modern machine translation software is still far from robust. To address this problem, we introduce referentially transparent inputs (RTIs), a simple, widely applicable methodology for validating machine translation software. A referentially transparent input is a piece of text that should have invariant translation when used in different contexts. Our practical implementation, Purity, detects when this invariance property is broken by a translation. To evaluate RTI, we use Purity to test Google Translate and Bing Microsoft Translator with 200 unlabeled sentences, which led to 123 and 142 erroneous translations with high precision (79.3\% and 78.3\%). The translation errors are diverse, including under-translation, over-translation, word/phrase mistranslation, incorrect modification, and unclear logic. These translation errors could lead to misunderstanding, financial loss, threats to personal safety and health, and political conflicts.
Structure-Invariant Testing for Machine Translation
Aug 24, 2019
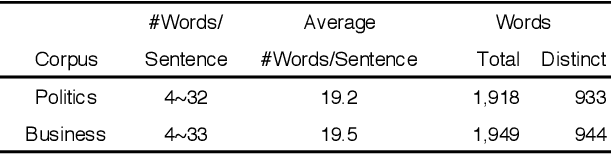
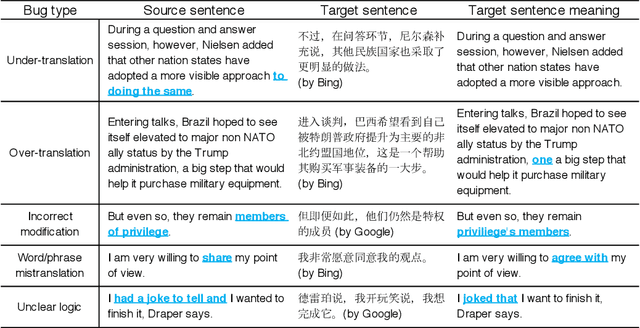
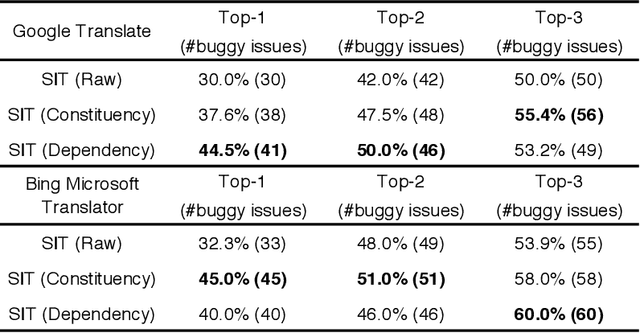
In recent years, machine translation software has increasingly been integrated into our daily lives. People routinely use machine translation for various applications, such as describing symptoms to a foreign doctor and reading political news in a foreign language. However, due to the complexity and intractability of neural machine translation (NMT) models that power modern machine translation systems, these systems are far from being robust. They can return inferior results that lead to misunderstanding, medical misdiagnoses, or threats to personal safety. Despite its apparent importance, validating the robustness of machine translation is very difficult and has, therefore, been much under-explored. To tackle this challenge, we introduce structure-invariant testing (SIT), a novel, widely applicable metamorphic testing methodology for validating machine translation software. Our key insight is that the translation results of similar source sentences should typically exhibit a similar sentence structure. SIT is designed to leverage this insight to test any machine translation system with unlabeled sentences; it specifically targets mistranslations that are difficult-to-find using state-of-the-art translation quality metrics such as BLEU. We have realized a practical implementation of SIT by (1) substituting one word in a given sentence with semantically similar, syntactically equivalent words to generate similar sentences, and (2) using syntax parse trees (obtained via constituency/dependency parsing) to represent sentence structure. To evaluate SIT, we have used it to test Google Translate and Bing Microsoft Translator with 200 unlabeled sentences as input, which led to 56 and 61 buggy translations with 60% and 61% top-1 accuracy, respectively. The bugs are diverse, including under-translation, over-translation, incorrect modification, word/phrase mistranslation, and unclear logic.