 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigVIC: Spatial Importance Guided Variable-Rate Image Compression
Mar 16, 2023Variable-rate mechanism has improved the flexibility and efficiency of learning-based image compression that trains multiple models for different rate-distortion tradeoffs. One of the most common approaches for variable-rate is to channel-wisely or spatial-uniformly scale the internal features. However, the diversity of spatial importance is instructive for bit allocation of image compression. In this paper, we introduce a Spatial Importance Guided Variable-rate Image Compression (SigVIC), in which a spatial gating unit (SGU) is designed for adaptively learning a spatial importance mask. Then, a spatial scaling network (SSN) takes the spatial importance mask to guide the feature scaling and bit allocation for variable-rate. Moreover, to improve the quality of decoded image, Top-K shallow features are selected to refine the decoded features through a shallow feature fusion module (SFFM). Experiments show that our method outperforms other learning-based methods (whether variable-rate or not) and traditional codecs, with storage saving and high flexibility.
Disentangling Orthogonal Planes for Indoor Panoramic Room Layout Estimation with Cross-Scale Distortion Awareness
Mar 04, 2023Based on the Manhattan World assumption, most existing indoor layout estimation schemes focus on recovering layouts from vertically compressed 1D sequences. However, the compression procedure confuses the semantics of different planes, yielding inferior performance with ambiguous interpretability. To address this issue, we propose to disentangle this 1D representation by pre-segmenting orthogonal (vertical and horizontal) planes from a complex scene, explicitly capturing the geometric cues for indoor layout estimation. Considering the symmetry between the floor boundary and ceiling boundary, we also design a soft-flipping fusion strategy to assist the pre-segmentation. Besides, we present a feature assembling mechanism to effectively integrate shallow and deep features with distortion distribution awareness. To compensate for the potential errors in pre-segmentation, we further leverage triple attention to reconstruct the disentangled sequences for better performance. Experiments on four popular benchmarks demonstrate our superiority over existing SoTA solutions, especially on the 3DIoU metric. The code is available at \url{https://github.com/zhijieshen-bjtu/DOPNet}.
Unsupervised OmniMVS: Efficient Omnidirectional Depth Inference via Establishing Pseudo-Stereo Supervision
Feb 22, 2023



Omnidirectional multi-view stereo (MVS) vision is attractive for its ultra-wide field-of-view (FoV), enabling machines to perceive 360{\deg} 3D surroundings. However, the existing solutions require expensive dense depth labels for supervision, making them impractical in real-world applications. In this paper, we propose the first unsupervised omnidirectional MVS framework based on multiple fisheye images. To this end, we project all images to a virtual view center and composite two panoramic images with spherical geometry from two pairs of back-to-back fisheye images. The two 360{\deg} images formulate a stereo pair with a special pose, and the photometric consistency is leveraged to establish the unsupervised constraint, which we term "Pseudo-Stereo Supervision". In addition, we propose Un-OmniMVS, an efficient unsupervised omnidirectional MVS network, to facilitate the inference speed with two efficient components. First, a novel feature extractor with frequency attention is proposed to simultaneously capture the non-local Fourier features and local spatial features, explicitly facilitating the feature representation. Then, a variance-based light cost volume is put forward to reduce the computational complexity. Experiments exhibit that the performance of our unsupervised solution is competitive to that of the state-of-the-art (SoTA) supervised methods with better generalization in real-world data.
Learning Thin-Plate Spline Motion and Seamless Composition for Parallax-Tolerant Unsupervised Deep Image Stitching
Feb 16, 2023Traditional image stitching approaches tend to leverage increasingly complex geometric features (point, line, edge, etc.) for better performance. However, these hand-crafted features are only suitable for specific natural scenes with adequate geometric structures. In contrast, deep stitching schemes overcome the adverse conditions by adaptively learning robust semantic features, but they cannot handle large-parallax cases due to homography-based registration. To solve these issues, we propose UDIS++, a parallax-tolerant unsupervised deep image stitching technique. First, we propose a robust and flexible warp to model the image registration from global homography to local thin-plate spline motion. It provides accurate alignment for overlapping regions and shape preservation for non-overlapping regions by joint optimization concerning alignment and distortion. Subsequently, to improve the generalization capability, we design a simple but effective iterative strategy to enhance the warp adaption in cross-dataset and cross-resolution applications. Finally, to further eliminate the parallax artifacts, we propose to composite the stitched image seamlessly by unsupervised learning for seam-driven composition masks. Compared with existing methods, our solution is parallax-tolerant and free from laborious designs of complicated geometric features for specific scenes. Extensive experiments show our superiority over the SoTA methods, both quantitatively and qualitatively. The code will be available at https://github.com/nie-lang/UDIS2.
Spatiotemporal Deformation Perception for Fisheye Video Rectification
Feb 08, 2023Although the distortion correction of fisheye images has been extensively studied, the correction of fisheye videos is still an elusive challenge. For different frames of the fisheye video, the existing image correction methods ignore the correlation of sequences, resulting in temporal jitter in the corrected video. To solve this problem, we propose a temporal weighting scheme to get a plausible global optical flow, which mitigates the jitter effect by progressively reducing the weight of frames. Subsequently, we observe that the inter-frame optical flow of the video is facilitated to perceive the local spatial deformation of the fisheye video. Therefore, we derive the spatial deformation through the flows of fisheye and distorted-free videos, thereby enhancing the local accuracy of the predicted result. However, the independent correction for each frame disrupts the temporal correlation. Due to the property of fisheye video, a distorted moving object may be able to find its distorted-free pattern at another moment. To this end, a temporal deformation aggregator is designed to reconstruct the deformation correlation between frames and provide a reliable global feature. Our method achieves an end-to-end correction and demonstrates superiority in correction quality and stability compared with the SOTA correction methods.
Dual Diffusion Architecture for Fisheye Image Rectification: Synthetic-to-Real Generalization
Jan 26, 2023



Fisheye image rectification has a long-term unresolved issue with synthetic-to-real generalization. In most previous works, the model trained on the synthetic images obtains unsatisfactory performance on the real-world fisheye image. To this end, we propose a Dual Diffusion Architecture (DDA) for the fisheye rectification with a better generalization ability. The proposed DDA is simultaneously trained with paired synthetic fisheye images and unlabeled real fisheye images. By gradually introducing noises, the synthetic and real fisheye images can eventually develop into a consistent noise distribution, improving the generalization and achieving unlabeled real fisheye correction. The original image serves as the prior guidance in existing DDPMs (Denoising Diffusion Probabilistic Models). However, the non-negligible indeterminate relationship between the prior condition and the target affects the generation performance. Especially in the rectification task, the radial distortion can cause significant artifacts. Therefore, we provide an unsupervised one-pass network that produces a plausible new condition to strengthen guidance. This network can be regarded as an alternate scheme for fast producing reliable results without iterative inference. Compared with the state-of-the-art methods, our approach can reach superior performance in both synthetic and real fisheye image corrections.
RecRecNet: Rectangling Rectified Wide-Angle Images by Thin-Plate Spline Model and DoF-based Curriculum Learning
Jan 04, 2023The wide-angle lens shows appealing applications in VR technologies, but it introduces severe radial distortion into its captured image. To recover the realistic scene, previous works devote to rectifying the content of the wide-angle image. However, such a rectification solution inevitably distorts the image boundary, which potentially changes related geometric distributions and misleads the current vision perception models. In this work, we explore constructing a win-win representation on both content and boundary by contributing a new learning model, i.e., Rectangling Rectification Network (RecRecNet). In particular, we propose a thin-plate spline (TPS) module to formulate the non-linear and non-rigid transformation for rectangling images. By learning the control points on the rectified image, our model can flexibly warp the source structure to the target domain and achieves an end-to-end unsupervised deformation. To relieve the complexity of structure approximation, we then inspire our RecRecNet to learn the gradual deformation rules with a DoF (Degree of Freedom)-based curriculum learning. By increasing the DoF in each curriculum stage, namely, from similarity transformation (4-DoF) to homography transformation (8-DoF), the network is capable of investigating more detailed deformations, offering fast convergence on the final rectangling task. Experiments show the superiority of our solution over the compared methods on both quantitative and qualitative evaluations. The code and dataset will be made available.
Temporal Consistency Learning of inter-frames for Video Super-Resolution
Nov 03, 2022Video super-resolution (VSR) is a task that aims to reconstruct high-resolution (HR) frames from the low-resolution (LR) reference frame and multiple neighboring frames. The vital operation is to utilize the relative misaligned frames for the current frame reconstruction and preserve the consistency of the results. Existing methods generally explore information propagation and frame alignment to improve the performance of VSR. However, few studies focus on the temporal consistency of inter-frames. In this paper, we propose a Temporal Consistency learning Network (TCNet) for VSR in an end-to-end manner, to enhance the consistency of the reconstructed videos. A spatio-temporal stability module is designed to learn the self-alignment from inter-frames. Especially, the correlative matching is employed to exploit the spatial dependency from each frame to maintain structural stability. Moreover, a self-attention mechanism is utilized to learn the temporal correspondence to implement an adaptive warping operation for temporal consistency among multi-frames. Besides, a hybrid recurrent architecture is designed to leverage short-term and long-term information. We further present a progressive fusion module to perform a multistage fusion of spatio-temporal features. And the final reconstructed frames are refined by these fused features. Objective and subjective results of various experiments demonstrate that TCNet has superior performance on different benchmark datasets, compared to several state-of-the-art methods.
Neural Contourlet Network for Monocular 360 Depth Estimation
Aug 03, 2022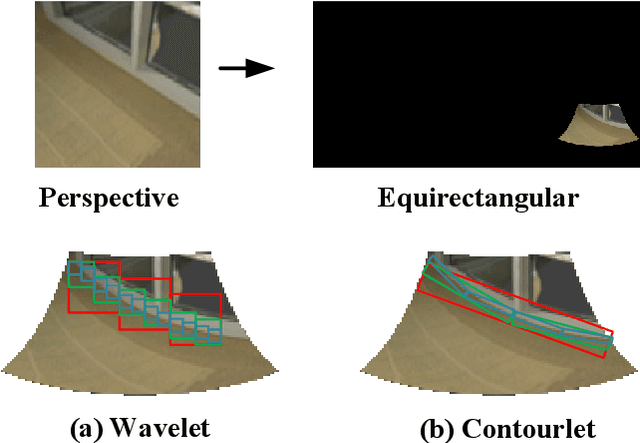


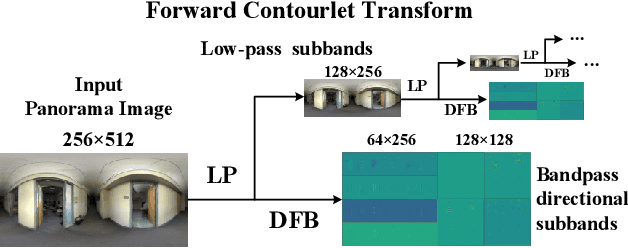
For a monocular 360 image, depth estimation is a challenging because the distortion increases along the latitude. To perceive the distortion, existing methods devote to designing a deep and complex network architecture. In this paper, we provide a new perspective that constructs an interpretable and sparse representation for a 360 image. Considering the importance of the geometric structure in depth estimation, we utilize the contourlet transform to capture an explicit geometric cue in the spectral domain and integrate it with an implicit cue in the spatial domain. Specifically, we propose a neural contourlet network consisting of a convolutional neural network and a contourlet transform branch. In the encoder stage, we design a spatial-spectral fusion module to effectively fuse two types of cues. Contrary to the encoder, we employ the inverse contourlet transform with learned low-pass subbands and band-pass directional subbands to compose the depth in the decoder. Experiments on the three popular panoramic image datasets demonstrate that the proposed approach outperforms the state-of-the-art schemes with faster convergence. Code is available at https://github.com/zhijieshen-bjtu/Neural-Contourlet-Network-for-MODE.
Deep Rotation Correction without Angle Prior
Jul 07, 2022



Not everybody can be equipped with professional photography skills and sufficient shooting time, and there can be some tilts in the captured images occasionally. In this paper, we propose a new and practical task, named Rotation Correction, to automatically correct the tilt with high content fidelity in the condition that the rotated angle is unknown. This task can be easily integrated into image editing applications, allowing users to correct the rotated images without any manual operations. To this end, we leverage a neural network to predict the optical flows that can warp the tilted images to be perceptually horizontal. Nevertheless, the pixel-wise optical flow estimation from a single image is severely unstable, especially in large-angle tilted images. To enhance its robustness, we propose a simple but effective prediction strategy to form a robust elastic warp. Particularly, we first regress the mesh deformation that can be transformed into robust initial optical flows. Then we estimate residual optical flows to facilitate our network the flexibility of pixel-wise deformation, further correcting the details of the tilted images. To establish an evaluation benchmark and train the learning framework, a comprehensive rotation correction dataset is presented with a large diversity in scenes and rotated angles. Extensive experiments demonstrate that even in the absence of the angle prior, our algorithm can outperform other state-of-the-art solutions requiring this prior. The codes and dataset will be available at https://github.com/nie-lang/RotationCorrection.