 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposed Vision-Language Retrieval for Skin Cancer Case Search via Joint Alignment of Global and Local Representations
Mar 10, 2026Medical image retrieval aims to identify clinically relevant lesion cases to support diagnostic decision making, education, and quality control. In practice, retrieval queries often combine a reference lesion image with textual descriptors such as dermoscopic features. We study composed vision-language retrieval for skin cancer, where each query consists of an image to text pair and the database contains biopsy-confirmed, multi-class disease cases. We propose a transformer based framework that learns hierarchical composed query representations and performs joint global-local alignment between queries and candidate images. Local alignment aggregates discriminative regions via multiple spatial attention masks, while global alignment provides holistic semantic supervision. The final similarity is computed through a convex, domain-informed weighting that emphasizes clinically salient local evidence while preserving global consistency. Experiments on the public Derm7pt dataset demonstrate consistent improvements over state-of-the-art methods. The proposed framework enables efficient access to relevant medical records and supports practical clinical deployment.
RSI-Net: Two-Stream Deep Neural Network Integrating GCN and Atrous CNN for Semantic Segmentation of High-resolution Remote Sensing Images
Sep 19, 2021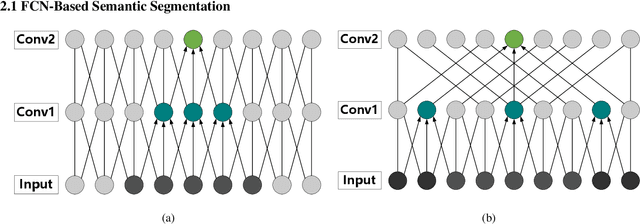
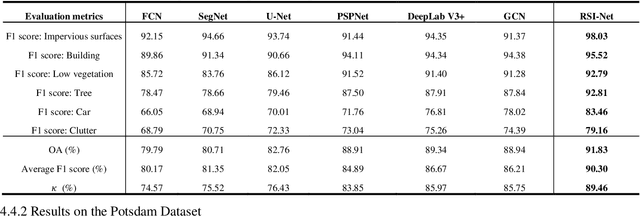
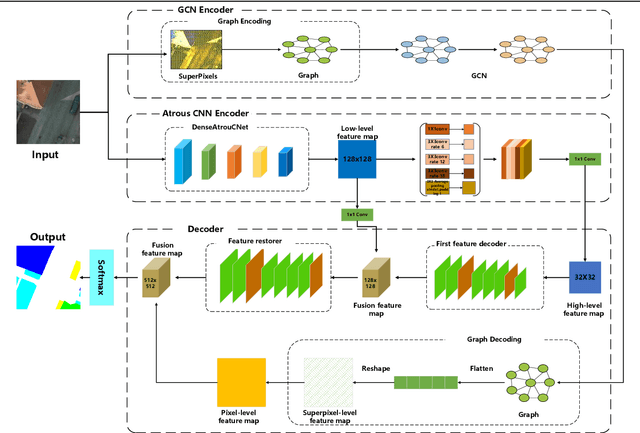
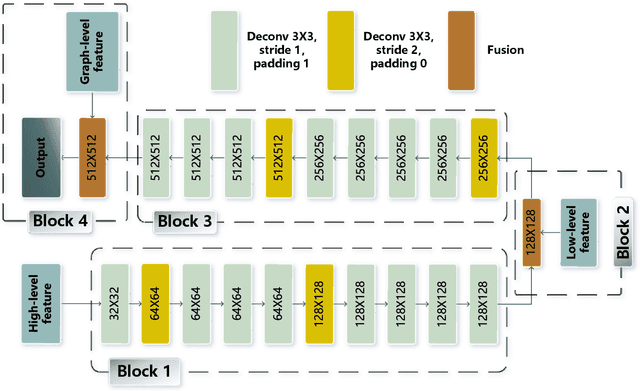
For semantic segmentation of remote sensing images (RSI), trade-off between representation power and location accuracy is quite important. How to get the trade-off effectively is an open question, where current approaches of utilizing attention schemes or very deep models result in complex models with large memory consumption. Compared with the popularly-used convolutional neural network (CNN) with fixed square kernels, graph convolutional network (GCN) can explicitly utilize correlations between adjacent land covers and conduct flexible convolution on arbitrarily irregular image regions. However, the problems of large variations of target scales and blurred boundary cannot be easily solved by GCN, while densely connected atrous convolution network (DenseAtrousCNet) with multi-scale atrous convolution can expand the receptive fields and obtain image global information. Inspired by the advantages of both GCN and Atrous CNN, a two-stream deep neural network for semantic segmentation of RSI (RSI-Net) is proposed in this paper to obtain improved performance through modeling and propagating spatial contextual structure effectively and a novel decoding scheme with image-level and graph-level combination. Extensive experiments are implemented on the Vaihingen, Potsdam and Gaofen RSI datasets, where the comparison results demonstrate the superior performance of RSI-Net in terms of overall accuracy, F1 score and kappa coefficient when compared with six state-of-the-art RSI semantic segmentation methods.