 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Explicit Behavioral Models with Adaptive Questions and World-Model Probes
Jun 05, 2026Interactive agents trained only against task return can achieve high scores while failing to represent the mechanisms that make their actions succeed. This makes brittle behavior difficult to diagnose and limits adaptation when environment dynamics change. Existing LLM reflection and policy-code repair can revise behavior from failed trajectories, but questions and world-understanding tests are usually used only after training. We introduce an Explicit Symbolic Behavioral Model (ESBM), a trainable behavioral model that couples task performance with evidence-grounded question answering and executable mechanism prediction. An ESBM represents behavior through typed predicates, weighted rules, bounded options and mechanism memory; the mechanism layer predicts symbolic events, object changes, rewards and terminal consequences under action interventions. After each rollout, adaptive questions and active world-model probes convert score failures, QA errors and transition-prediction errors into constraints for local ESBM edits. Candidate models are selected by a multi-criterion rule that jointly evaluates task score, answerability and active world-model consistency. Under the tested Atari-style protocols, ESBM learns high-scoring policies while producing explicit answers and executable mechanism predictions, indicating that adaptive questions can serve as both training pressure and reusable benchmarks for mechanistic policy learning in this setting.
Kintsugi: Learning Policies by Repairing Executable Knowledge Bases
May 10, 2026Modern embodied agents achieve impressive performance, but their task knowledge is often stored in neural weights, latent state, or prompt-bound memory, making individual policy knowledge difficult to inspect, validate, recombine, and reuse. We introduce \textbf{Kintsugi}, a white-box policy-learning framework that treats embodied policy improvement as verifier-gated construction of a typed executable Knowledge Base (KB). Kintsugi represents task-level policy knowledge as composable typed entries -- predicates, operators, policy schemas, monitors, recovery rules, experience records, and goals -- and improves this artifact through localized typed edits induced from rollout evidence, rather than relying on test-time language-model reasoning. Between rollouts, a tool-constrained agentic editing loop diagnoses trajectory failures, localizes them to editable KB layers, and proposes candidate edits. A deterministic verification gate admits an edit only when the candidate type-checks, the resulting KB executes, and focused validation success or trajectory-health metrics improve without violating protected-regression checks. At inference, the accepted KB is executed by a deterministic symbolic executor with zero LLM calls. Across long-horizon text-agent benchmarks and representative object-centric manipulation settings, Kintsugi achieves strong endpoint performance while preserving inspectability, local editability, and verifier-gated deployment. These results suggest that embodied policy improvement can be organized around executable task knowledge.
Can Machines Help Us Answering Question 16 in Datasheets, and In Turn Reflecting on Inappropriate Content?
Feb 14, 2022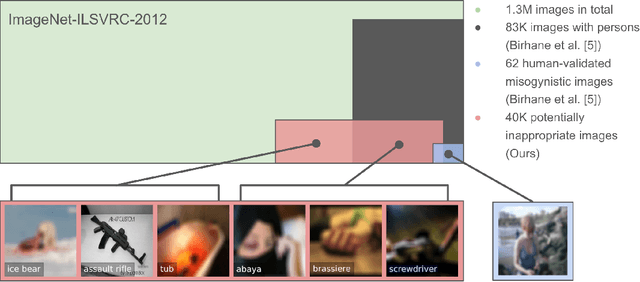
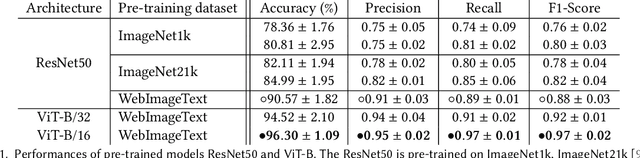
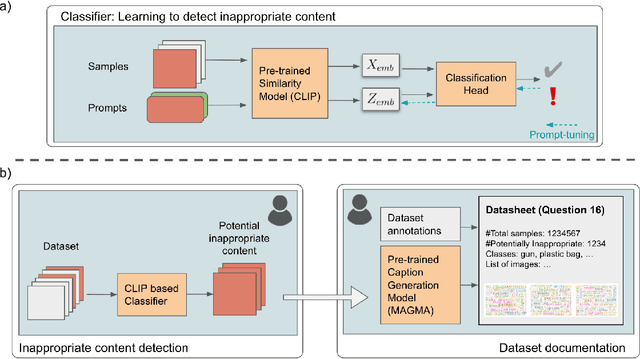
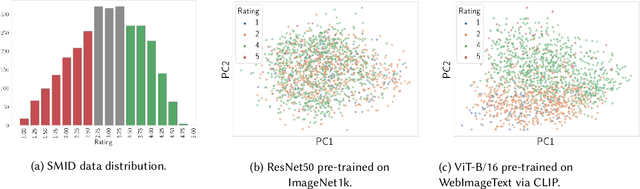
Large datasets underlying much of current machine learning raise serious issues concerning inappropriate content such as offensive, insulting, threatening, or might otherwise cause anxiety. This calls for increased dataset documentation, e.g., using datasheets. They, among other topics, encourage to reflect on the composition of the datasets. So far, this documentation, however, is done manually and therefore can be tedious and error-prone, especially for large image datasets. Here we ask the arguably "circular" question of whether a machine can help us reflect on inappropriate content, answering Question 16 in Datasheets. To this end, we propose to use the information stored in pre-trained transformer models to assist us in the documentation process. Specifically, prompt-tuning based on a dataset of socio-moral values steers CLIP to identify potentially inappropriate content, therefore reducing human labor. We then document the inappropriate images found using word clouds, based on captions generated using a vision-language model. The documentations of two popular, large-scale computer vision datasets -- ImageNet and OpenImages -- produced this way suggest that machines can indeed help dataset creators to answer Question 16 on inappropriate image content.